摘要
本文提出了一种通过3级卷积神经网络估计脸部关键点的新方法。在每一级,网络的输出都是鲁棒且准确的。卷积网络的深度结构能在初始阶段中,从全部的脸部区域中提取出高级的特征,这些有利于关键点的准确定位。有两个主要的优点:1、整张脸的上下文信息都被利用到了,2、关键点的几何学约束已经被暗含了。避免了局部优化方法带来的缺点。网络的后两级被训练用于局部优化初试预测值。
1、 介绍
脸部关键点检测对人脸识别、分析来说至为重要。主要的挑战是when face images are taken with extreme poses, lightings, expressions, and occlusions, as shown in Figure 1.现有的方法主要分成两类:分类查找窗口[3,4,1,20,28],和直接预测关键点位置(或形状参数)[5,8,9,21,25,26]。对于第一种方法,为每一个关键点训练一个被称为component detector的分类器,是基于局部信息的。可能找到多个类似脸部关键点的候选区域或找到的候选区域不合适。在这种情况下,一个优化方法是加入形状约束。和component detector相比,直接预测位置(或形状参数)是更有效的,不需要扫描。回归经常被用于预测,基于靠近脸部关键点的局部区域或者整个图像区域。同时需要添加空域约束。

许多方法迭代地更新脸部关键点为位置,好的初始化是关键的。平均shape或者从训练集中采样到的shape被作为初试值,这些往往离目标位置很远,然后更新到一个局部最小值。另外,许多方法面临提取的特征没有判别力或者不够可靠,所以上下文信息是很重要的。许多方法使用shape约束,这是相对较弱的。从整个脸部区域提取纹理信息是很有必要的。这需要更有力的分类器或回归器,因为视觉复杂度随着图像区域的大小指数增长。
为了解决这些问题,本文提出了一种级联回归器的方法。用三级卷积网络检测脸部关键点。不同于现有的方法大致地估计脸部关键点的初试位置,我们的卷积网络在第一级就做出了准确的估计。这有效地避免了局部最小值问题。卷积网络把整张脸作为输入,最好地利用了上下文信息,并在深度构架的高层提取了全局的高级特征,即使局部的低级特征变得不可靠时也能有效地预测关键点位置。同时由于同时预测多个点,关键点的约束也被隐含其中。
剩余的两级卷积网络用于提纯初始估计。这两级的卷积网络是浅层的,它们的任务是低层的且他们的输入被限制在一个小的初始点的小局部区域。详细的试验评估证明了本文的方法在准确性和可靠性的表现都是state-of-art的。
2、 级联的卷积网络
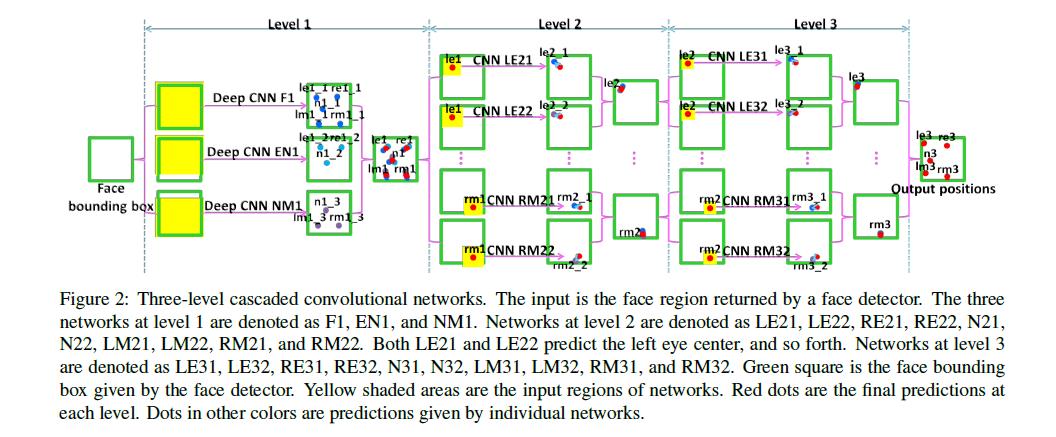
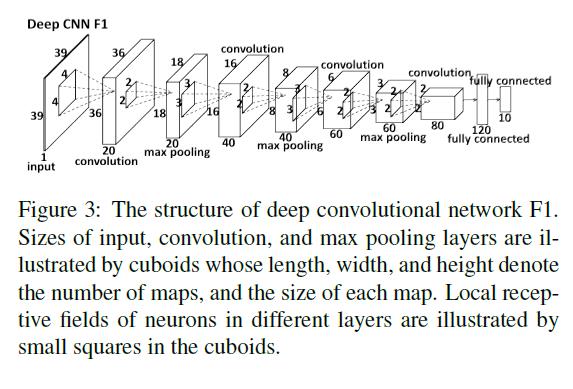
Fig2.是本文方法的概要。有5个面部点,左眼中心(LE),右眼中心(RE),鼻子(N),左嘴角(LM),右嘴角(RM)。在第一级,我们使用3个深度卷积网络,输入区域分别包括整张脸(F1),眼和鼻子,鼻子和嘴。每个网络同时估计多个面部点。对每一个面部点,多个网络的预测求平均来减少变动。Fig3.阐述了F1的结构,包括4个卷积层,后面跟着是max pooling层,还有2个全连阶层。EN1和NM1使用相同的深度结构,由于输入区域的大小不同,每一层的大小不同。第2、3级的网络把预测点局部的一小块作为输入,且只允许在之前的预测上做微小改变。小块的大小和搜索范围随着级数减小。后两级的预测是被严格限制的,因为局部的图像有时是不可靠的。在后两级,每个点的预测位置是由两个取不同的patch大小的网络的平均值得到的。第一级的目标是稳定地估计关键点位置,同时保证极少的大误差。网络的后两级目标是得到高精度。后两级的所有网络使用一个相同的浅层结构。
2.1网络结构选择
分析3个选择网络的重要因素。讨论集中在最难训练的第一级网络。第一,第一级的网络必须要深。从大的输入区域中预测关键点是一个高级任务。更深的结构有利于形成全局的高级特征,在低层,由于局部感受野,神经元提取的特征是局部的。通过结合空间上相邻的低层特征,高层的神经元能从更大的区域提取特征。此外,高层的特征是高度非线性的,增加额外的层增强了从输入到输出的非线性,更有可能代表输入和输出的关系。
第二,对卷积层上的神经元,在双曲正切激活函数后的绝对值校正(下一章)能有效提高效果。这在[14]中被体术。
第三,局部地共享权值有利于更好的表现。
2.2多级回归
我们发现几种有效的方法结合多重卷积网络。第一章是多级回归。脸部bounding box是仅有的先验知识。一个面部点对bounding box的相对位置可能分部在一个很大的范围,这是由于脸部检测器的不稳定性和姿态的多样性。所以第一级的输入区域应该是足够大来覆盖所有可能的预测。但大的输入区域是主要的不准确原因,因为不相关的区域可能退化网络最后的输出。第一级的网络输出为接下来的检测提供了一个强大的先验知识。真实的脸部点伪装分布在第一级预测的一个小领域内。所以第二级的检测可以在一个小范围内完成。但没有上下文信息,局部区域的表现是不可靠的。为了避免发散,我们不能级联太多层,或者过多信任接下来的层。这些网络只能在一个小范围内调整初始预测。
为了更好的提高检测精度和可靠性,我们提出了每一级都有多个网络共同地预测每一个点。这些网络的不同在于输入区域。最后的预测可以用公式表达如下:
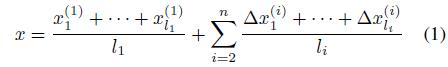
对n-级级联,在i级有li个预测。第一级的预测是绝对位置,接下来的级的预测是调整。
3、 调整细节
输入层I(h,w),2D的没有用到颜色信息。卷积层CR(s,n,p,q)(卷积核大小,特征层数,共享权值参数(局部共享权值))。(h,w,m)代表前一层的大小。卷积操作表示为:

激活函数为双曲正切函数。池化层表示为P(s),s为卷积区域长度。卷积结果乘以一个增益系数g,加上一个偏置b。公式表示如下:
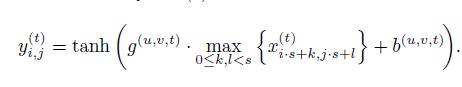
全连接层F(n),公式:
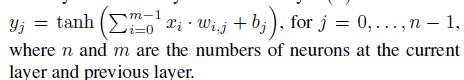
结构:

1、 输入区域:
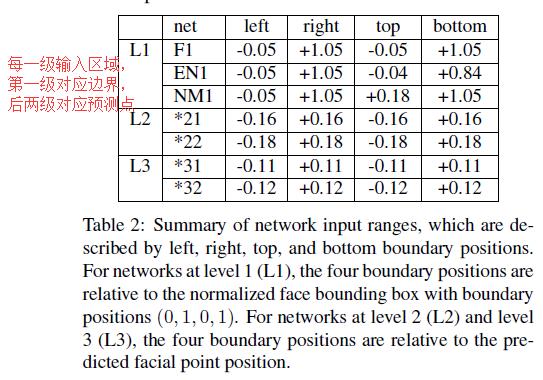
F1输入整个脸,输出5个点,EN1输入上部和中部,输出两个眼睛和鼻子,NM1输入中部和底部,输出3个点。第二级和第三级的所有网络使用前一层的预测为中心的方形区域为输入,输出一个增量预测。在这两级,我们用两个不同大小的区域来预测每个点,第三层的区域比第二层小。每一级的网络精度输入如Table2所示。
2、 训练
第一级,训练和边界相关的小块,通过小的变换和旋转增强数据。在接下来的级中,我们训练以ground truth 位置随机变换得到的位置为中心的小块,第二级在水平和竖直最大的shift为0.05,第三级为0.02,这个距离是以bounding box的大小为基准。参数通过随机初始化和随机梯度下降法得到。LM算法用于估计学习律[19].
4、试验

5、参考文献
[1] http://www.luxand.com/facesdk/. 6
[2] http://research.microsoft.com/en-us/projects/facesdk/. 6
[3] B. Amberg and T. Vetter. Optimal landmark detection usingshape models and branch and bound. In Proc. ICCV, 2011.1, 2
[4] P. N. Belhumeur, D. W. Jacobs, D. J. Kriegman, and N. Kumar.Localizing parts of faces using a consensus of exemplars.In Proc. CVPR, 2011. 1, 2, 6, 7
[5] X. Cao, Y. Wei, F. Wen, and J. Sun. Face alignment by explicitshape regression. In Proc. CVPR, 2012. 1, 2, 6, 7
[6] D. Ciresan, U. Meier, and J. Schmidhuber. Multi-columndeep neural networks for image classification. In Proc.CVPR, 2012. 2
[7] A. Coates, A. Y. Ng, and H. Lee. An analysis of singlelayernetworks in unsupervised feature learning. Journal of Machine Learning Research, 2011. 2
[8] T. F. Cootes, G. J. Edwards, and C. J. Taylor. Active appearance models. In Proc. ECCV, 1998. 1
[9] M. Dantone, J. Gall, G. Fanelli, and L. J. V. Gool. Real-time facial feature detection using conditional regression forests. In Proc. CVPR, 2012. 1, 2
[10] C. Farabet, C. Couprie, L. Najman, and Y. LeCun. Learning hierarchical features for scene labeling. PAMI, 2013. 2
[11] L. Gu and T. Kanade. A generative shape regularization model for robust face alignment. In Proc. ECCV, 2008. 1
[12] G. B. Huang, H. Lee, and E. Learned-Miller. Learning hierarchical representations for face verification with convolutional deep belief networks. In Proc. CVPR, 2012. 4
[13] G. B. Huang, M. Ramesh, T. Berg, and E. Learned-Miller. Labeled faces in the wild: A database for studying face recognition in unconstrained environments. Technical Report 07-49, University of Massachusetts, Amherst, 2007. 5
[14] K. Jarrett, K. Kavukcuoglu, M. Ranzato, and Y. LeCun. What is the best multi-stage architecture for object recognition? In Proc. ICCV, 2009. 2, 3
[15] O. Jesorsky, K. J. Kirchberg, and R. Frischholz. Robust face detection using the hausdorff distance. In Proc. AVBPA, 2001. 6
[16] K. Kavukcuoglu, P. Sermanet, Y.-L. Boureau, K. Gregor, M. Mathieu, and Y. LeCun. Learning convolutional feature hierarchies for visual recognition. In Proc. NIPS, 2010. 2
[17] A. Krizhevsky, I. Sutskever, and G. Hinton. Imagenet classification with deep convolutional neural networks. In Proc. NIPS, 2012. 2
[18] Q. Le, M. Ranzato, R. Monga, M. Devin, K. Chen, G. Corrado, J. Dean, and A. Ng. Building high-level features using large scale unsupervised learning. In Proc. ICML, 2012. 2
[19] Y. LeCun, L. Bottou, G. Orr, and K. Muller. Efficient backprop. In G. Orr and M. K., editors, Neural Networks: Tricks of the trade. Springer, 1998. 5
[20] L. Liang, R. Xiao, F. Wen, and J. Sun. Face alignment via component-based discriminative search. In Proc. ECCV, 2008. 1, 2, 6
[21] X. Liu. Generic face alignment using boosted appearance model. In Proc. CVPR, 2007. 1
[22] P. Luo, X. Wang, and X. Tang. Hierarchical face parsing via deep learning. In Proc. CVPR, 2012. 2
[23] S. Milborrow and F. Nicolls. Locating facial features with an extended active shape model. In Proc. ECCV, 2008. 1
[24] M. Osadchy, Y. L. Cun, and M. L. Miller. Synergistic face detection and pose estimation with energy-based models. Journal of Machine Learning Research, 2007. 2
[25] P. Sauer, T. Cootes, and C. Taylor. Accurate regression procedures for active appearance models. In Proc. BMVC, 2011. 1, 2
[26] M. Valstar, B. Martinez, X. Binefa, and M. Pantic. Facial point detection using boosted regression and graph models. In Proc. CVPR, 2010. 1, 2, 6
[27] H. Wu, X. Liu, and G. Doretto. Face alignment via boosted ranking model. In Proc. CVPR, 2008. 1
[28] X. Zhu and D. Ramanan. Face detection, pose estimation, and landmark localization in the wild. In Proc. CVPR, 2012. 1, 2, 5
摘要
本文提出了一种通过3级卷积神经网络估计脸部关键点的新方法。在每一级,网络的输出都是鲁棒且准确的。卷积网络的深度结构能在初始阶段中,从全部的脸部区域中提取出高级的特征,这些有利于关键点的准确定位。有两个主要的优点:1、整张脸的上下文信息都被利用到了,2、关键点的几何学约束已经被暗含了。避免了局部优化方法带来的缺点。网络的后两级被训练用于局部优化初试预测值。
1、 介绍
脸部关键点检测对人脸识别、分析来说至为重要。主要的挑战是when face images are taken with extreme poses, lightings, expressions, and occlusions, as shown in Figure 1.现有的方法主要分成两类:分类查找窗口[3,4,1,20,28],和直接预测关键点位置(或形状参数)[5,8,9,21,25,26]。对于第一种方法,为每一个关键点训练一个被称为component detector的分类器,是基于局部信息的。可能找到多个类似脸部关键点的候选区域或找到的候选区域不合适。在这种情况下,一个优化方法是加入形状约束。和component detector相比,直接预测位置(或形状参数)是更有效的,不需要扫描。回归经常被用于预测,基于靠近脸部关键点的局部区域或者整个图像区域。同时需要添加空域约束。
许多方法迭代地更新脸部关键点为位置,好的初始化是关键的。平均shape或者从训练集中采样到的shape被作为初试值,这些往往离目标位置很远,然后更新到一个局部最小值。另外,许多方法面临提取的特征没有判别力或者不够可靠,所以上下文信息是很重要的。许多方法使用shape约束,这是相对较弱的。从整个脸部区域提取纹理信息是很有必要的。这需要更有力的分类器或回归器,因为视觉复杂度随着图像区域的大小指数增长。
为了解决这些问题,本文提出了一种级联回归器的方法。用三级卷积网络检测脸部关键点。不同于现有的方法大致地估计脸部关键点的初试位置,我们的卷积网络在第一级就做出了准确的估计。这有效地避免了局部最小值问题。卷积网络把整张脸作为输入,最好地利用了上下文信息,并在深度构架的高层提取了全局的高级特征,即使局部的低级特征变得不可靠时也能有效地预测关键点位置。同时由于同时预测多个点,关键点的约束也被隐含其中。
剩余的两级卷积网络用于提纯初始估计。这两级的卷积网络是浅层的,它们的任务是低层的且他们的输入被限制在一个小的初始点的小局部区域。详细的试验评估证明了本文的方法在准确性和可靠性的表现都是state-of-art的。