1.K-近邻算法(kNN)
1.1K-近邻算法概述
简单的说,K-近邻算法采用测量不同特征值之间的距离方法进行分类
优点:精度高、对异常值不敏感、无数据输入假定
缺点:计算复杂度高、空间复杂度高
适用数据范围:数值型和标称型
1.2KNN算法原理
存在一个样本训练数据集合,并且每个样本数据都存在标签,即我们知道样本集中每一位数据和所属分类的对应关系。输入没有新标签的数据集后,将新数据的每个特征与数据集样本中的对应的特征进行比较,然后算法提取样本集中特征最相近的数据(最近邻)的分类标签。一般来说,我们只选择数据集中前k个最相似的数据,这就是K-近邻算法中k的出处。通常K是不大于20的整数。最后选择最相似数据中出现次数最多的分类,作为新数据的分类。
电影类型评估代码(本书所需的数据集可到这位大神的GitHub下载)
import numpy as np
import operator
def createDataSet():
group=np.array([[3,104],[2,100],[101,10],[99,5]])
#四组二维特征
labels=['爱情片','爱情片','动作片','动作片']
#四组二维特征对应的标签
return group,labels
def classify0(inX,dataSet,labels,k):
dataSetSize=dataSet.shape[0]
#numpy函数shape[0]返回dataSet的行数
diffMat=np.tile(inX,(dataSetSize,1))-dataSet
#np.tile()函数,把数组沿各个方向复制,此例中是沿横向复制一倍(其实是没有增加),纵向复制dataSetSize次
sqDiffMat=diffMat**2
sqDistances=sqDiffMat.sum(axis=1)
#sum(0)列相加,sum(1)行相加
distances=sqDistances**0.5
sortedDistIndicies=distances.argsort()
#返回distance中元素从小到大的排列值
classCount={}
for i in range(k):
votelabel=labels[sortedDistIndicies[i]]
#取出前k个元素的类别
classCount[votelabel]=classCount.get(votelabel,0)+1
#dict.get(key,default=None),字典的get方法,返回指定键的值,如果不在字典中返回默认值
#计算类别次数
sortedClassCount=sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
#字典函数items(),函数以列表返回可遍历的键和值
#python3中用items()替换python2中的iteritems()
#key=operator.itemgetter[1]根据字典的值进行排序
#key=operator.itemgetter[0 ]根据字典的键进行排序
#reverse降序排序字典
return sortedClassCount[0][0]
#返回次数最多的类别
if __name__=='__main__':
group,labels=createDataSet()
test=[3,100]
result=classify0(test,group,labels,2)
print(result)
运行结果:

在约会网站上使用K—近邻算法寻找合适海伦的人
分析数据:使用Matplotlib创建散点图
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
def file2matrix(filename):
fr=open(filename)
arrayOlLines=fr.readlines()
#读取文件所有内容
numberOfLines=len(arrayOlLines)
returnMat=np.zeros((numberOfLines,3))
#np.zeros()函数生成矩阵中的值全为0
classLabelVector=[]
index=0
for line in arrayOlLines:
line=line.strip()
#strip(),括号为空时,默认删除空白符(包括\n,\r,\t)
listFromline=line.split('\t')
returnMat[index,:]=listFromline[0:3]
if listFromline[-1]=='didntLike':
classLabelVector.append(1)
elif listFromline[-1]=='smallDoses':
classLabelVector.append(2)
elif listFromline[-1]=='largeDoses':
classLabelVector.append(3)
index+=1
return returnMat,classLabelVector
def showdata(data,classla):
fig=plt.figure()
#产生一个空窗口
ax=fig.add_subplot(221)#221的意思是把一张图片分为两行两列,把ax要显示的放在第一张图上
bx=fig.add_subplot(222)
cx=fig.add_subplot(223)
#将fig画布分隔成1行1列,不共享x轴和y轴,fig画布的大小为(13,8)
#当nrow=2,nclos=2时,代表fig画布被分为四个区域,axs[0][0]表示第一行第一个区域
#fig, axs = plt.subplots(nrows=2, ncols=2,sharex=False, sharey=False, figsize=(13,8))
#number0fLabels=len(data)
labelsColors=[]
for i in classla:
if i==1:
labelsColors.append('black')
if i==2:
labelsColors.append('orange')
if i==3:
labelsColors.append('red')
#print(type(data),type(classla))
ax.scatter(data[:,0],data[:,1],color=labelsColors,s=15,alpha=.5)
bx.scatter(data[:,0],data[:,2],color=labelsColors,s=15,alpha=.5)
cx.scatter(data[:,1],data[:,2],color=labelsColors,s=15,alpha=.5)
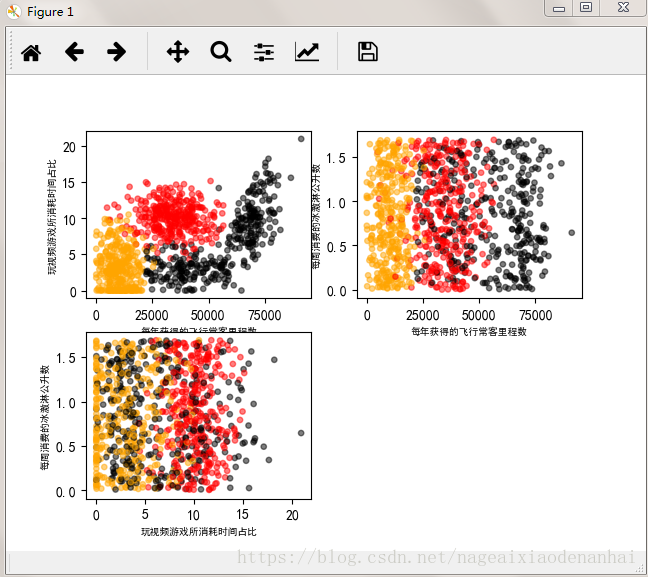
ax_xlabel_text = ax.set_xlabel(u'每年获得的飞行常客里程数')
ax_ylabel_text = ax.set_ylabel(u'玩视频游戏所消耗时间占比')
bx_xlabel_text = bx.set_xlabel(u'每年获得的飞行常客里程数')
bx_ylabel_text = bx.set_ylabel(u'每周消费的冰激淋公升数')
cx_xlabel_text = cx.set_xlabel(u'玩视频游戏所消耗时间占比')
cx_ylabel_text = cx.set_ylabel(u'每周消费的冰激淋公升数')
plt.setp(ax_xlabel_text, size=7, weight='bold', color='black')
plt.setp(bx_xlabel_text, size=7, weight='bold', color='black')
plt.setp(cx_xlabel_text, size=7, weight='bold', color='black')
plt.setp(ax_ylabel_text, size=7, weight='bold', color='black')
plt.setp(bx_ylabel_text, size=7, weight='bold', color='black')
plt.setp(cx_ylabel_text, size=7, weight='bold', color='black')
plt.show()
if __name__=="__main__":
data,classla=file2matrix('./datingTestSet.txt')
showdata(data,classla)
准备数据,这里使用了欧式距离来计算两个点之间的距离:
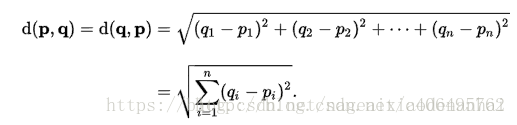
然后对数据做了归一化处理
归一化代码:
#准备数据,归一化数据
# -*- coding: utf-8 -*-
"""
Created on Sun Apr 1 20:11:04 2018
@author: Administrator
"""
import operator
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
def classify0(inX,dataSet,labels,k):
dataSetSize=dataSet.shape[0]
#numpy函数shape[0]返回dataSet的行数
diffMat=np.tile(inX,(dataSetSize,1))-dataSet
#np.tile()函数,把数组沿各个方向复制,此例中是沿横向复制一倍(其实是没有增加),纵向复制dataSetSize次
sqDiffMat=diffMat**2
sqDistances=sqDiffMat.sum(axis=1)
#sum(0)列相加,sum(1)行相加
distances=sqDistances**0.5
sortedDistIndicies=distances.argsort()
#返回distance中元素从小到大的排列值
classCount={}
for i in range(k):
votelabel=labels[sortedDistIndicies[i]]
#取出前k个元素的类别
classCount[votelabel]=classCount.get(votelabel,0)+1
#dict.get(key,default=None),字典的get方法,返回指定键的值,如果不在字典中返回默认值
#计算类别次数
sortedClassCount=sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
#字典函数items(),函数以列表返回可遍历的键和值
#python3中用items()替换python2中的iteritems()
#key=operator.itemgetter[1]根据字典的值进行排序
#key=operator.itemgetter[0 ]根据字典的键进行排序
#reverse降序排序字典
return sortedClassCount[0][0]
#返回次数最多的类别
#准备数据,归一化数据
def autoNorm(dataSet):
min=dataSet.min(0)
max=dataSet.max(0)
ranges=max-min
m=dataSet.shape[0]
normDataSet=dataSet-np.tile(min,(m,1))
normDataSet=normDataSet/np.tile(ranges,(m,1))
return normDataSet,ranges,min
def file2matrix(filename):
fr=open(filename)
arrayOlLines=fr.readlines()
#读取文件所有内容
numberOfLines=len(arrayOlLines)
returnMat=np.zeros((numberOfLines,3))
#np.zeros()函数生成矩阵中的值全为0
classLabelVector=[]
index=0
for line in arrayOlLines:
line=line.strip()
#strip(),括号为空时,默认删除空白符(包括\n,\r,\t)
listFromline=line.split('\t')
returnMat[index,:]=listFromline[0:3]
if listFromline[-1]=='didntLike':
classLabelVector.append(1)
elif listFromline[-1]=='smallDoses':
classLabelVector.append(2)
elif listFromline[-1]=='largeDoses':
classLabelVector.append(3)
index+=1
return returnMat,classLabelVector
if __name__=="__main__":
data,classla=file2matrix('./datingTestSet.txt')
data1=autoNorm(data)
print(data1)
运行结果:

用完整代码测试分类器效果
# -*- coding: utf-8 -*-
"""
Created on Sun Apr 1 20:11:04 2018
@author: Administrator
"""
import operator
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
def classify0(inX,dataSet,labels,k):
dataSetSize=dataSet.shape[0]
#numpy函数shape[0]返回dataSet的行数
diffMat=np.tile(inX,(dataSetSize,1))-dataSet
#np.tile()函数,把数组沿各个方向复制,此例中是沿横向复制一倍(其实是没有增加),纵向复制dataSetSize次
sqDiffMat=diffMat**2
sqDistances=sqDiffMat.sum(axis=1)
#sum(0)列相加,sum(1)行相加
distances=sqDistances**0.5
sortedDistIndicies=distances.argsort()
#返回distance中元素从小到大的排列值
classCount={}
for i in range(k):
votelabel=labels[sortedDistIndicies[i]]
#取出前k个元素的类别
classCount[votelabel]=classCount.get(votelabel,0)+1
#dict.get(key,default=None),字典的get方法,返回指定键的值,如果不在字典中返回默认值
#计算类别次数
sortedClassCount=sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
#字典函数items(),函数以列表返回可遍历的键和值
#python3中用items()替换python2中的iteritems()
#key=operator.itemgetter[1]根据字典的值进行排序
#key=operator.itemgetter[0 ]根据字典的键进行排序
#reverse降序排序字典
return sortedClassCount[0][0]
#返回次数最多的类别
#准备数据,归一化数据
def autoNorm(dataSet):
min=dataSet.min(0)
max=dataSet.max(0)
ranges=max-min
m=dataSet.shape[0]
normDataSet=dataSet-np.tile(min,(m,1))
normDataSet=normDataSet/np.tile(ranges,(m,1))
return normDataSet,ranges,min
def file2matrix(filename):
fr=open(filename)
arrayOlLines=fr.readlines()
#读取文件所有内容
numberOfLines=len(arrayOlLines)
returnMat=np.zeros((numberOfLines,3))
#np.zeros()函数生成矩阵中的值全为0
classLabelVector=[]
index=0
for line in arrayOlLines:
line=line.strip()
#strip(),括号为空时,默认删除空白符(包括\n,\r,\t)
listFromline=line.split('\t')
returnMat[index,:]=listFromline[0:3]
if listFromline[-1]=='didntLike':
classLabelVector.append(1)
elif listFromline[-1]=='smallDoses':
classLabelVector.append(2)
elif listFromline[-1]=='largeDoses':
classLabelVector.append(3)
index+=1
return returnMat,classLabelVector
#测试算法,作为完整程序验证分类
def datingClassTest():
hoRatio=0.2
datingDataMat,datingLabels=file2matrix('datingTestSet.txt')
normMat,ranges,min=autoNorm(datingDataMat)
m=normMat.shape[0]
numTestVecs=int(m*hoRatio)
errorCount=0.0
for i in range(numTestVecs):
classifierResult=classify0(normMat[i,:],normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],5)
print('分类器返回:{},正确结果是:{}'.format(classifierResult,datingLabels[i]))
if(classifierResult!=datingLabels[i]):
errorCount+=1.0
print('the total error rate is:{}'.format(errorCount/float(numTestVecs)))
if __name__=="__main__":
datingClassTest()
运行结果:
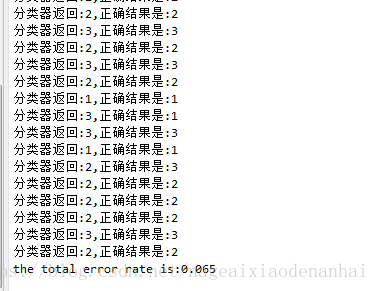
这里的数据集错误率是6.5%,有点高,可以试着改变k值和hoRatio的值来调整错误率。
使用算法
# -*- coding: utf-8 -*-
"""
Created on Sun Apr 1 20:11:04 2018
@author: Administrator
"""
import operator
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
def classify0(inX,dataSet,labels,k):
dataSetSize=dataSet.shape[0]
#numpy函数shape[0]返回dataSet的行数
diffMat=np.tile(inX,(dataSetSize,1))-dataSet
#np.tile()函数,把数组沿各个方向复制,此例中是沿横向复制一倍(其实是没有增加),纵向复制dataSetSize次
sqDiffMat=diffMat**2
sqDistances=sqDiffMat.sum(axis=1)
#sum(0)列相加,sum(1)行相加
distances=sqDistances**0.5
sortedDistIndicies=distances.argsort()
#返回distance中元素从小到大的排列值
classCount={}
for i in range(k):
votelabel=labels[sortedDistIndicies[i]]
#取出前k个元素的类别
classCount[votelabel]=classCount.get(votelabel,0)+1
#dict.get(key,default=None),字典的get方法,返回指定键的值,如果不在字典中返回默认值
#计算类别次数
sortedClassCount=sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
#字典函数items(),函数以列表返回可遍历的键和值
#python3中用items()替换python2中的iteritems()
#key=operator.itemgetter[1]根据字典的值进行排序
#key=operator.itemgetter[0 ]根据字典的键进行排序
#reverse降序排序字典
return sortedClassCount[0][0]
#返回次数最多的类别
#准备数据,归一化数据
def autoNorm(dataSet):
min=dataSet.min(0)
max=dataSet.max(0)
ranges=max-min
m=dataSet.shape[0]
normDataSet=dataSet-np.tile(min,(m,1))
normDataSet=normDataSet/np.tile(ranges,(m,1))
return normDataSet,ranges,min
def file2matrix(filename):
fr=open(filename)
arrayOlLines=fr.readlines()
#读取文件所有内容
numberOfLines=len(arrayOlLines)
returnMat=np.zeros((numberOfLines,3))
#np.zeros()函数生成矩阵中的值全为0
classLabelVector=[]
index=0
for line in arrayOlLines:
line=line.strip()
#strip(),括号为空时,默认删除空白符(包括\n,\r,\t)
listFromline=line.split('\t')
returnMat[index,:]=listFromline[0:3]
if listFromline[-1]=='didntLike':
classLabelVector.append(1)
elif listFromline[-1]=='smallDoses':
classLabelVector.append(2)
elif listFromline[-1]=='largeDoses':
classLabelVector.append(3)
index+=1
return returnMat,classLabelVector
#测试算法,作为完整程序验证分类
def datingClassTest():
hoRatio=0.2
datingDataMat,datingLabels=file2matrix('datingTestSet.txt')
normMat,ranges,min=autoNorm(datingDataMat)
m=normMat.shape[0]
numTestVecs=int(m*hoRatio)
errorCount=0.0
for i in range(numTestVecs):
classifierResult=classify0(normMat[i,:],normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],5)
print('分类器返回:{},正确结果是:{}'.format(classifierResult,datingLabels[i]))
if(classifierResult!=datingLabels[i]):
errorCount+=1.0
print('the total error rate is:{}'.format(errorCount/float(numTestVecs)))
def classifPreson():
resultList=['nor at all','in small does','in large doses']
percentTate=float(input('话费在玩游戏上的时间百分比:'))
ffMile=float(input('每年飞行公里数:'))
iceCream=float(input('每周消耗的冰激凌公升数:'))
dataset,dataLabels=file2matrix('datingTestSet.txt')
normMat,ranges,min=autoNorm(dataset)
inArr=np.array([ffMile,percentTate,iceCream])
classifierresult=classify0((inArr-min)/ranges,normMat,dataLabels,3)
print('你将要可能喜欢这个喜欢人:',resultList[classifierresult-1])
if __name__=="__main__":
#datingClassTest()
classifPreson()
运行结果:
sklearn实战——手写识别系统
sklearn有提供KNN算法的API,直接调用即可。
import numpy as np
import operator
from sklearn.neighbors import KNeighborsClassifier as kNN
from os import listdir
def img2vector(filename):
returnvect=np.zeros((1,1024))
fr=open(filename)
for i in range(32):
linestr=fr.readline()
for j in range(32):
returnvect[0,32*i+j]=int(linestr[j])
return returnvect
def handwritingClassTest():
hwLabels=[]
trainingFileList=listdir('trainingDigits')
m=len(trainingFileList)
trainingMat=np.zeros((m,1024))
for i in range(m):
fileNameStr=trainingFileList[i]
classNumber=int(fileNameStr.split('_')[0])
hwLabels.append(classNumber)
trainingMat[i,:]=img2vector('trainingDigits/{}'.format(fileNameStr))
neigh=kNN(n_neighbors=3,algorithm='auto')
neigh.fit(trainingMat,hwLabels)
testFileList=listdir('testDigits')
errorCount=0.0
mtest=len(testFileList)
for i in range(mtest):
fileNameStr=testFileList[i]
classNumber=int(fileNameStr.split('_')[0])
vectoUndertest=img2vector('testDigits/{}'.format(fileNameStr))
classifierResult=neigh.predict(vectoUndertest)
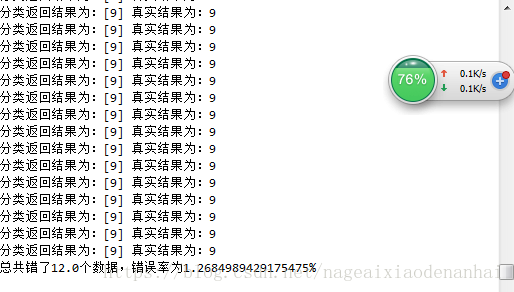
print('分类返回结果为:{} 真实结果为:{}'.format(classifierResult,classNumber))
if (classifierResult!=classNumber):
errorCount+=1
print('总共错了{}个数据,错误率为{}'.format(errorCount,errorCount/mtest*100))
if __name__=='__main__':
handwritingClassTest()
运行结果: