主要内容:
一.算法概述
二.距离度量
三.k值的选择
四.分类决策规则
五.利用KNN对约会对象进行分类
六.利用KNN构建手写识别系统
七.KNN之线性扫描法的不足
一.算法概述
1.k近邻算法,简而言之,就是选取k个与输入点的特征距离最近的数据点中出现最多的一种分类,作为输入点的类别。
2.如下面一个例子,有六部电影,可用“打斗镜头”和“接吻镜头”作为每一部电影的特征值,且已知每一部电影的类别,即“爱情片”还是“动作片”。此外,还有一部电影,只知道其特征,但不知道其类别。如下:

为了方便研究,可以将其放到二维平面上:

为了得出?的类别,可以选择与之距离最近的k部电影,然后将这k部电影中出现次数最多的类别作为该部电影的类别。
?与每一部电影的距离为:
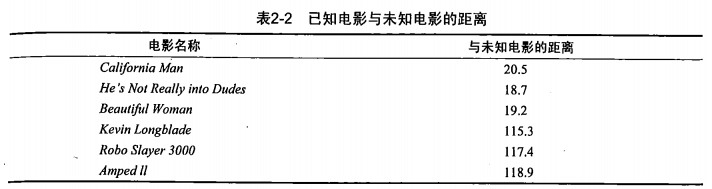
假如选取k为3,而前面3部电影的类别均为爱情片,所以可以认为?的类别为爱情片。
3.通过例子可以看出,KNN算法的三个基本要素为:距离度量、k值的选择、分类决策规则,下面将一一讲解。
二.距离度量
1.特征空间中两个实例点的距离反应了两个实例点的相似程度,k近邻模型的特征空间是n维的实数向量空间。其中使用的距离是欧式距离,即我们平常所说的“直线距离”,但也可以是其他距离。或者可以归于一个类别,即Lp距离。其基本介绍如下:
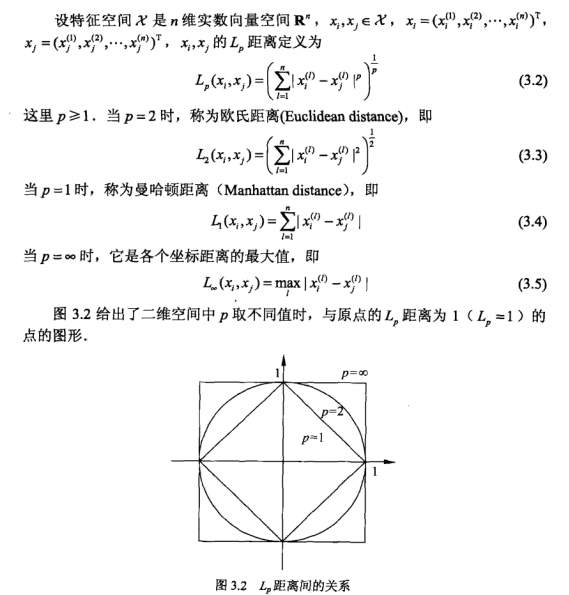
三.k值的选择
从直觉上可得出:k值的选择对模型的有效性影响很大。
1.如果k值选得比较小,那么预测结果会对临近的点十分敏感。假如附近的点刚好是噪声,那么预测结果就会出错。总体而言,容易发生过拟合。
2.假如k值选得比较大,那么预测结果就很容易受到数量大的类别的干扰,特别地,当k=N时,那么类别就永远为数量最大的那个类别,算法就没有意义的。
3.综上,k过大或者过小,预测结果都可能变得糟糕。所以可以通过交叉验证法来选取最优值k。
思考:在选取了k个最近点之后,每个点对于预测结果的影响所占的权值都是一样的,即都是“一票”,但可不可以设置权值:越靠近的点权值越大呢?这样做会不会好一点?不过这个问题好像归类于下面一节的。
四.分类决策规则
分类决策规则,即得到k个最近点之后,通过什么方式去决定最终的分类。从直觉上可感觉到选取数量最多的那个类别作为输入点的类别或许是比较合理的。下面是具体的数学解释:

五.利用KNN对约会对象进行分类
六.利用KNN构建手写识别系统
七.KNN之线性扫描法的不足