第2章 k-近邻算法【02】
实战2:在约会网站上使用k-近邻算法
一、涉及的Python函数功能介绍:
1、append() 函数的作用
在列表末尾添加新的对象
http://www.runoob.com/python/att-list-append.html
2、split()函数作用
切分数据
http://www.runoob.com/python/att-string-split.html
3、strip()函数作用
移除字符串头尾指定的字符(默认为空格)
http://www.runoob.com/python/att-string-strip.html
4、readlines()函数作用
读取所有行(直到结束符 EOF)并返回列表
http://www.runoob.com/python/file-readlines.html
5、add_subplot()函数作用
6、scatter()函数作用
http://blog.csdn.net/u013634684/article/details/49646311
7、for i in range ()作用
http://blog.csdn.net/weixin_38705903/article/details/79238226
8、min()与max()函数作用
http://blog.csdn.net/weixin_38705903/article/details/79238249
9、符号&和\作用
& 是位运算“与”
\ 是“续行”的意思
二、实际操作
1、读取数据
1)在kNN.py内新增代码
#提取datingTestSet2.txt中的数据
def file2matrix(filename):
fr = open(filename) #打开datingTestSet2.txt
arrayOLines = fr.readlines() #读取每一行的内容
numberofLines = len(arrayOLines) #记录训练集的行数(即样本数)
#定义returnMat,用于存放提取后的数据,参数3的意思是3列,因为有3个特征
returnMat = zeros((numberofLines,3))
classLabelVector = []
index = 0
#把每一行的数据依次放入line中
for line in arrayOLines:
line = line.strip() #去掉\n
listFromLine = line.split('\t') #以\t为依据,对数据进行切片
#提取切片后的前三个数据,即三个特征的数值,只会读取到listFromLine[2]
returnMat[index,:] = listFromLine[0:3]
classLabelVector.append(int(listFromLine[-1])) #将label放入classLabelVector中
index += 1 #returnMat下移一行以便存放新的样本数据
return returnMat,classLabelVector2)将datingTestSet.txt文件放在kNN.py的目录下,datingTestSet.txt文件可在此处免费下载:http://www.ituring.com.cn/book/1021
(如果不介意施舍我2个积分的话也可以到这里。。。
http://download.csdn.net/download/weixin_38705903/10235455)
3)在kNN.py目录下打开cmd窗口 (cmd窗口快速定位到具体文件夹方法)
然后输入以下代码
reload(kNN)
datingDataMat,datingLabels = kNN.file2matrix('datingTestSet2.txt')再次输入datingDataMat和datingLabels即可查看数据
2、分析数据:使用Matplotlib创建散点图
在cmd窗口下继续输入,得到普通散点图
(可以直接粘贴整块代码到cmd窗口中,电脑会自动执行每一行)
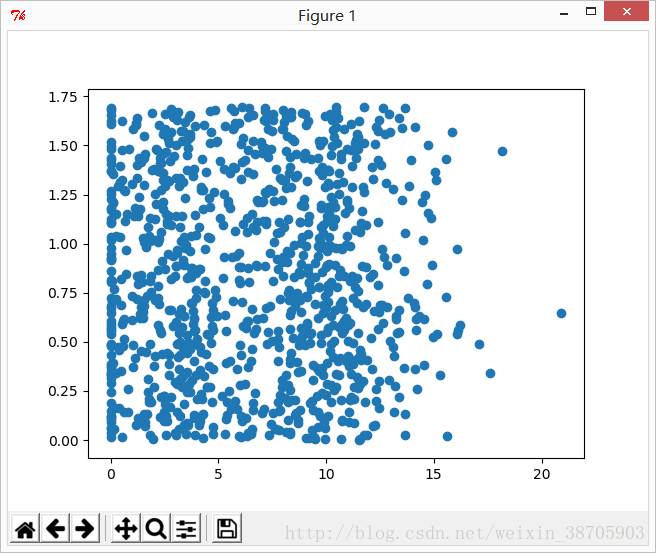
import matplotlib
import matplotlib.pyplot as plt
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(datingDataMat[:,1], datingDataMat[:,2])
plt.show()关闭图片,继续输入,得到不同颜色和尺寸的散点图
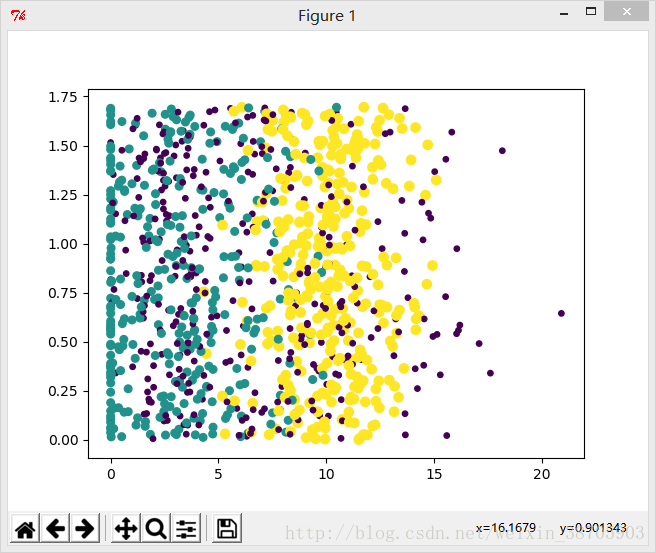
fig = plt.figure()
ax = fig.add_subplot(111)
from numpy import *
ax.scatter(datingDataMat[:,1], datingDataMat[:,2], 15.0*array(datingLabels), 15.0*array(datingLabels))
plt.show()这段分析的代码记住,会用即可
3、准备数据:归一化数值
归一化方法为:
newValue = (oldValue-min)/(max-min)
1)在kNN.py内新增代码
#归一化特征值
def autoNorm(dataSet):
minVals = dataSet.min(0) #把每一列最小值放到minVals中
maxVals = dataSet.max(0) #把每一列最大值放到maxVale中
#minVals,maxVals为1行n列(n个特征)
ranges = maxVals - minVals #计算可能的取值范围
normDataSet = zeros(shape(dataSet)) #初始化normDataSet
m = dataSet.shape[0] #记录data的行
normDataSet = dataSet - tile(minVals, (m,1)) #得到每一个样本的(oldValue-min),并放入normDataSet中
#tile(minVals, (m,1))生成m行n列的矩阵,即将minVals复制m份(因为有m个样本)
normDataSet = normDataSet/tile(ranges, (m,1)) #newValue = (oldValue-min)/(max-min),得到归一化后的特征值
#返回归一化后的特征值,取值范围和最小值
return normDataSet, ranges, minVals2)在kNN.py目录下打开cmd窗口,然后输入
reload(kNN)
normMat, ranges, minVals = kNN.autoNorm(datingDataMat)输入normMat即可看到归一化后的数据
4、测试算法:作为完整程序验证分类器
1)在kNN.py内新增代码
#分类器针对约会网站的测试代码
def datingClassTest():
hoRatio = 0.10 #设置测试集比重,此处为前10%作为测试集,后90%作为训练集
#提取datingTestSet2.txt内数据
datingDataMat, datingLabels = file2matrix('datingTestSet2.txt')
#得到归一化后的训练集,取值范围和最小值
normMat, ranges, minVals = autoNorm(datingDataMat)
m = normMat.shape[0] #得到样本数量m
numTestVecs = int(m*hoRatio) #得到测试集最后一个样本的位置
errorCount = 0.0 #初始化定义错误的个数为0个
#range(numTestVecs)=100,因为数组从0开始,故共100个测试样本
for i in range(numTestVecs):
#测试集中元素逐一放进分类器测试,k = 3,\是续行的意思
classifierResult = classify0(normMat[i,:],normMat[numTestVecs:m, :],\
datingLabels[numTestVecs:m],3)
#输出分类结果与实际label
print "the classifier came back with: %d, the real answer is: %d"\
% (classifierResult, datingLabels[i])
#若预测结果与实际label不同,则errorCount+1
if (classifierResult != datingLabels[i]):errorCount += 1.0
#输出错误率 = 错误的个数 / 总样本个数
print "the total error rate is: %f" % (errorCount/float(numTestVecs))2)在kNN.py目录下打开cmd窗口,然后输入
reload(kNN)
kNN.datingClassTest()得到错误率是:0.050000
5、使用算法:构建完整可用系统
1)在kNN.py内新增代码
#约会网站预测函数
def classifyPerson():
resultList = ['not at all','in small doses','in large doses'] #给label贴上名字
#得到特征1(玩视频游戏所耗时间百分比)数据
percentTats = float(raw_input("percentage of time spent playing video games?"))
#得到特征2(每年获得的飞行常客里程数)数据
ffMiles = float(raw_input("frequent flier miles earned per year?"))
#得到特征3(每周消费的冰淇淋公升数)数据
iceCream = float(raw_input("liters of ice cream consumed per year?"))
datingDataMat, datingLabels = file2matrix('datingTestSet2.txt') #加载训练集
normMat, ranges, minVals = autoNorm(datingDataMat) #训练集数据归一化
inArr = array([ffMiles, percentTats, iceCream]) #将输入的数据变成一个向量
#放入分类器进行分类
classifierResult = classify0((inArr-minVals)/ranges, normMat,datingLabels,3)
print "You will probably like this person:",resultList[classifierResult - 1] #输出结果2)在kNN.py目录下打开cmd窗口,然后输入
reload(kNN)
kNN.classifyPerson()用以下数据测试:
percentage of time spent playing video games?10
frequent flier miles earned per year?10000
liters of ice cream consumed per year?0.5
得到结果为:
You will probably like this person:in small doses
三、常见错误
1、NameError:name ‘kNN’ is not defined
可能原因:之前关闭了cmd窗口,因此需要重新加载kNN
解决办法:输入import kNN
2、输入ax.scatter(datingDataMat[:,1], datingDataMat[:,2], 15.0*array(datingLabels),15.0*array(datingLabels))一直在等待,无反应
解决办法:按回车键
3、classify0时报错:AttributeError: ‘module’ object has no attribute ‘xxx:

解决办法:输入import kNN
from numpy import * 4、plot()后,不能输入新的scatter函数,输入代码没反应
需要关掉图片,从ax = fig.add_subplot(111)开始重新输入
5、import kNN或者reload(kNN)报错
正常情况下import kNN成功不会返回信息,reload(kNN)成功会返回module ‘kNN’ from
若是cmd报错了,必然是kNN内代码错误,错误提示信息里面会具体告诉你是哪一行出现了问题
例如下图:
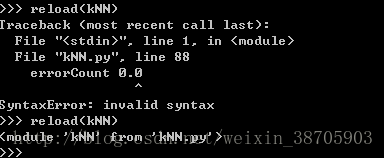
解决办法:根据错误提示去更改kNN里面的错误
6、出现错误ValueError: invalid literal for int() with base 10: ‘largeDoses’
可能原因:’datingTestSet1.txt’内的label不是数字
解决办法:P22页,命令
datingDataMat,datingLabels=kNN.file2matrix(‘datingTestSet.txt’)
要改为
datingDataMat,datingLabels=kNN.file2matrix(‘datingTestSet2.txt’)
变化的地方是’datingTestSet2.txt’