K-近邻算法采用测量不同特征值之间的距离方法进行分类。具有精度高,对异常值不敏感,无数据输入假定的有点,缺点是计算复杂度高,空间复杂度高。
k-近邻算法(KNN)的工作原理是:存在一个样本数据集合,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分类的对应关系。输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本集中特征最相似数据的分类标签。
在判断电影类型的例子中,给出了6部电影的打斗和接吻镜头数,假设这时候有一部电影已知其打斗和接吻的镜头数,要求给出这部电影是爱情片还是动作片?
首先计算未知电影的与样本集中其他6部电影的距离,得到距离之后将其按照递增的方式进行排序,取前k个距离对应的电影,根据前k个电影对应的类型来判断未知电影的类型。假设前k个电影都是爱情片则判定未知电影的类型也是爱情片。
关于python的编译环境我用的是pyCharm,python的版本是2.7
在pyCharm中新建一个项目,然后添加.py文件之后,在新建的.py文件中编写代码,首先是createDataSet()函数的编写。
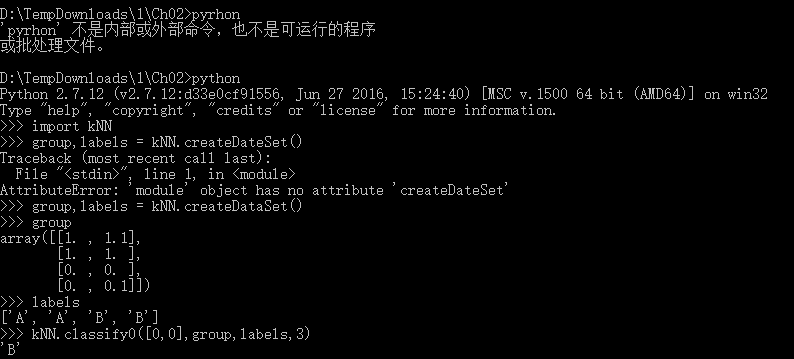
对未知属性的数据集中的每个点按照以下步骤执行:
1. 计算已知类别数据集中的点与当前点之间的距离;
2. 按照距离递增次序排序
3. 选取与当前点距离最小的k个点
4. 确定前k个点所在类别的出现频率
5. 返回前k个点出现频率最高的类别作为当前点的预测分类。
使用k-近邻算法改进约会网站的配对效果:
Python语言使用索引值-1表示列表中的最后一列元素。
创建散点图,Matplotlib提供的scatter函数支持个性化标记散点图上的点。


处理不同取值范围的特征值时,常采用的方法是将数值归一化。
手写识别系统:
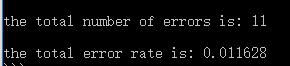
K近邻算法是基于实例的学习,使用算法时我们必须有接近实际数据的训练样本数据。K-近邻算法必须保存全部数据集,如果训练数据集的很大,必须使用大量的存储空间。此外必须对数据集中的每个数据计算距离值,实际使用时可能非常耗时。