第一周 深度学习的实用层面
1. 数据集划分
训练集:用以对算法进行训练,更新参数。
验证集:用以训练过程检验模型和数据的拟合程度,可省略
测试集:训练完成后评估模型所用的数据集
划分:1、无验证集时,训练集:测试集 = 7:3
2、训练集:验证集:测试集 = 6:2:2
2. bias-variance, 偏差和方差
偏差bias:描述模型对训练集的拟合程度。偏差过大可能是“欠拟合”,可以选择更为复杂的模型。
方差variance:描述预测值的分散程度。如果训练出的模型在新的数据集上分散程度高方差大可能是过拟合,也可能是同时在训练集上偏差大,模型拟合度不够。
噪声: 决定了模型准确度的上限,描述了学习问题本身的难度。
3. 正则化避免过拟合,标准化加快学习速度
L2正则化的代价函数为:
正则化思想:减小方差,避免某些参数值过大即过于“依赖”某些神经元,表现为曲线不够平滑。
L2正则化如何起作用?从上式可以看出,L2正则化在原来代价函数的基础上增加了后面部分,这部分可以减小w的整体表现,
欧式范数是所有元素的平方和,从整体上表现了w的大小,当其当其过大时损失函数也会偏大,因此训练过程会减小其值。
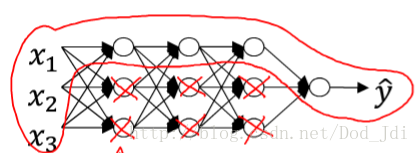
数学表示, 减小了W的值:

直观来说,当λ=2m时,w的部分值减小到趋于0,神经网络趋向于退化为线性模型,避免过拟合。 或者说由于w的减小,
减小,g(z)在接近0的部分表现接近于线性模型。
通过代码感受对梯度下降的影响:
dZ3 = A3 - Y # 代价函数的导数
dW3 = 1. / m * np.dot(dZ3, A2.T) + lambd / m * W3 # dZ3, A2.T 和 dZ3, W3.T 对应
db3 = 1. / m * np.sum(dZ3, axis=1, keepdims=True)
dA2 = np.dot(W3.T, dZ3)
dZ2 = np.multiply(dA2, np.int64(A2 > 0))
dW2 = 1. / m * np.dot(dZ2, A1.T) + lambd / m * W2
db2 = 1. / m * np.sum(dZ2, axis=1, keepdims=True)
dA1 = np.dot(W2.T, dZ2)
dZ1 = np.multiply(dA1, np.int64(A1 > 0))
dW1 = 1. / m * np.dot(dZ1, X.T) + lambd / m * W1
db1 = 1. / m * np.sum(dZ1, axis=1, keepdims=True)dropout正则化和其类似,以一定的概率去掉或保留部分神经元,也可认为从一定程度上退化为线性模型。如上图1。dropout常用于计算机视觉,在媒体中有用的数据是稀疏的,即使大量的数据集相对于大量的无用数据来说也容易导致过拟合,例如绿色像素在树和叶子中的影响。使用dropout有助于改善这一情况。
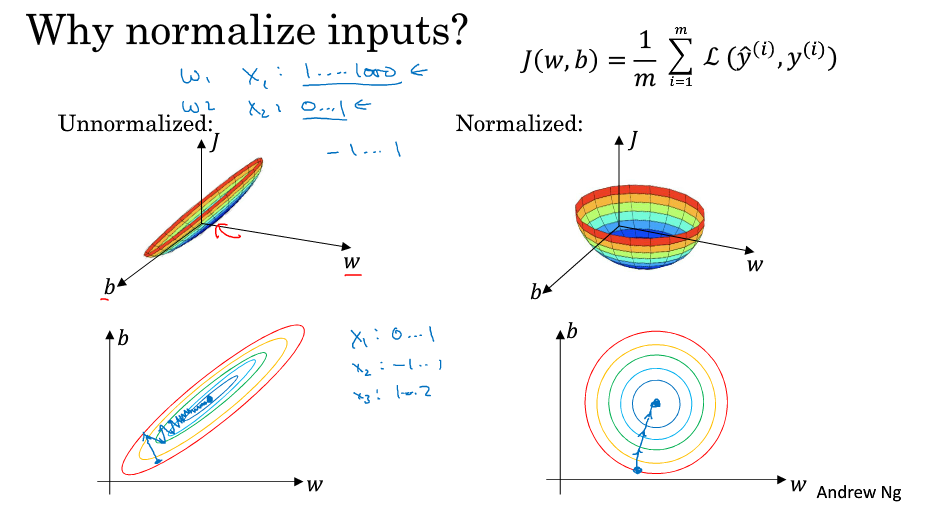
通过对输入进行标准化(归一化)可以加快训练速度:
其思想是缩小X因子间的绝对差距,使其显得相对规整,可以使用较大的学习率。
4. 梯度消失和梯度爆炸
在梯度函数上出现的以指数级递增或者递减的情况分别称为梯度爆炸或者梯度消失。尤其在很深的网络中,由于反向传播中乘法的存在容易使梯度过大导致W变得过小或者过大,如出现loss=nan(无穷大),这时候可以尝试减小学习率等。
假定 g(z)=z,b[l]=0,对于目标输出有:
对于
的值大于 1 的情况,激活函数的值将以指数级递增
对于
的值小于 1 的情况,激活函数的值将以指数级递减。
根据 ,其中x^n和前面的输出有关,因此当输入的数量 n 较大时,我们希望每个 wi 的值都小一些,这样它们的和得到的 z 也较小。为了得到较小的 wi,设置Var(wi)=1/n,这里称为 Xavier initialization。
WL = np.random.randn(WL.shape[0], WL.shape[1]) * np.sqrt(1/n)梯度检验,可以通过正向传播计算代价函数的值,然后与反向传播计算出的梯度进行比较,检查模型的codeing是否正确。公式如下:
一般当ϵ=1e-7(即 )时,diff<1e-6即可认为基本正确。代码如下:
gradapprox = (J_plus - J_minus) / (2 * epsilon)
numerator = np.linalg.norm(grad - gradapprox)
denominator = np.linalg.norm(grad) + np.linalg.norm(gradapprox)
difference = numerator / denominator第二周优化算法
BGD(batch gradient descent):每次迭代都使用全部数据集进行训练取误差平均值进行梯度下降。
min-batch或MBGD(min-batch gradient descent):每次迭代取部分数据集进行训练,加快迭代速度。
SGD(stochastic gradient descent)随机梯度下降:可以认为是min-batch或者包含下面部分的更广泛的内容。
1 指数加权平均算法和动量(momentum)梯度下降法
指数加权平均算法, 即用均值v代替原值θ:
。一般取β=0.9。例如:
可以看出,其基本思想是 将t时刻的值与以前的值按由近到远以指数级“疏远”关联起来。
偏差: 一般
为了修正这种较大偏差,t为t时刻或者t次迭代等:
动量梯度下降法(gradient descent witht momentum):将指数加权平均引入梯度计算当中:
视频中 , 但我们一般认为w都是对同一层而言,故将层数 l 改为迭代次数 t 方便理解.
形象的理解:v可以看做均值也可以看做“速度(其实也是均值的概念)”,梯度下降描述为从一个坑坑洼洼的大坑上的点下滑,由于采用min-batch,可能batch1往左下,batch2往右下,使用指数加权平均将其和前面联系起来,相当于给火车头一个牵往“中间”的阻力系数β(也是维持原来动量的系数),而1-β为该时刻“下降”的加速度。
2 Adam(adaptive moment estimation)适应性矩估计算法
先说说RMSprop(root mean square prop)均方根支算法,和动量梯度下降类似( ϵ 防止分母过小为0 ):
Adagrad(适应性梯度下降):令学习率 跟随梯度、训练次数n等变化,如:
Adam结合了RMSprop、Adagrad以及前面的动量梯度下降法,即:
经典取值为
for l in range(1, L + 1):
# 计算 v
v['dW' + str(l)] = beta1 * v['dW' + str(l)] + (1 - beta1) * grads['dW' + str(l)]
v['db' + str(l)] = beta1 * v['db' + str(l)] + (1 - beta1) * grads['db' + str(l)]
# 修正 v
v_corrected['dW' + str(l)] = v['dW' + str(l)] / (1 - beta1 ** t) # 快捷指数 ** n
v_corrected['db' + str(l)] = v['db' + str(l)] / (1 - beta1 ** t)
# 计算 s
s['dW' + str(l)] = beta2 * s['dW' + str(l)] + (1 - beta2) * (grads['dW' + str(l)] ** 2)
s['db' + str(l)] = beta2 * s['db' + str(l)] + (1 - beta2) * (grads['db' + str(l)] ** 2)
# 修正 s
s_corrected['dW' + str(l)] = s['dW' + str(l)] / (1 - beta2 ** t)
s_corrected['db' + str(l)] = s['db' + str(l)] / (1 - beta2 ** t)
# 更新参数, w = w - a * v / s(s) , 即此时 dw = v / s(s)
parameters['W' + str(l)] -= learning_rate * v_corrected['dW' + str(l)] / (
np.sqrt(s_corrected['dW' + str(l)]) + epsilon)
parameters['b' + str(l)] -= learning_rate * v_corrected['db' + str(l)] / (
np.sqrt(s_corrected['db' + str(l)]) + epsilon)
return parameters, v, s第三周:超参数调试、Batch 正则化和程序框架
1、超参数调试
最重要: 学习率
其次: 动量梯度下降系数
, 各层隐藏单元数 hidden_units,mini-batch 的大小
最后:β1,β2,ϵ:Adam 优化算法的超参数,常设为 0.9、0.999、10−8;#layers:神经网络层数; decay_rate:学习衰减率
多个超参数参数可以通过表格选取比较,0.0001~0.1可以选取0.0001,0.001,0.01,0.1等值,但 β 涉及指数运算,在1较大的数时差异较大,可以适当增大选取频率。
2、Batch normalization(BN)
和输入标准化处理类似,Batch normalization对 Z 进行标准化处理,ϵ 是为了防止分母为零,通常取 10−8:
为了避免Z的值过小(全都靠近0)影响后续层计算,引入两个自定义参数:
Batch normalization的作用:1、类似标准化处理,加快训练速度 2、防止某些参数过大,减小对某些使其分散分布的神经元的依赖(正则化) 3、将不同类别“聚集”,更易“区分”,减小前面神经元的影响,后续神经元有更大的自由度,有利于去噪。
3、softmax激活函数
一个4分类的计算出属于各个分类的维度为[1,4]的概率 p 后取max为其类别,计算如下:
举个栗子
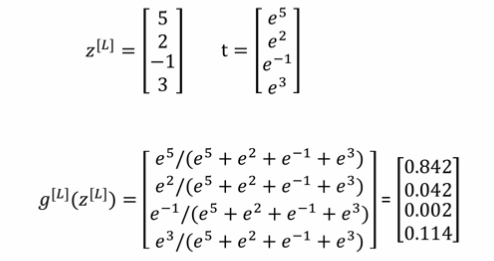
代价函数和sigmoid类似,由于正向传播涉及指数运算,这里也要用对数运算,c个类别的m个样本, 其损失函数为:
这样理解,其中 为属于 i 类的概率,则 故前面有个 负号且使用对数和激活值联系起来, 并且当 pj 越接近 1 时, log(pi)越接近0,和 乘积的绝对值就越小,损失值也就越小。
另外 y 一般是一个ont-hot编码,只有在特定位置 yj=1, 因此可以简写为下面的形式(其中 1{.} 表示 {.} 里面的内容为真则值为1,否则为0):
代价函数:
在梯度下降时往往在输出层使用sigmoid函数替换进行计算,损失函数使用交叉熵损失函数,梯度一般为也是:
4、框架:
TensorFlow等框架可以帮助实现梯度下降等功能,方便编码:
import numpy as np
import tensorflow as tf
cofficients = np.array([[1.],[-10.],[25.]])
w = tf.Variable(0,dtype=tf.float32)
x = tf.placeholder(tf.float32,[3,1])
# Tensorflow 重载了加减乘除符号
cost = x[0][0]*w**2 + x[1][0]*w + x[2][0]
# 改变下面这行代码,可以换用更好的优化算法
train = tf.train.GradientDescentOptimizer(0.01).minimize(cost)
init = tf.global_variables_initializer()
session = tf.Session()
session.run(init)
for i in range(1000):
session.run(train, feed_dict=(x:coefficients))
print(session.run(w))