Tuning process(调试处理):神经网络的调整会涉及到许多不同超参数的设置。需要调试的重要超参数一般包括:学习率、momentum、mini-batch size、隐藏单元(hidden units)、层数、学习率衰减。一般对于你要解决的问题而言,你很难提前知道哪个参数最重要。超参值的搜索过程可以随机取值和精确搜索,考虑使用由粗糙到精细的搜索过程。
超参数搜索过程:Re-test hyper parameters occasionally、Babysitting one model(计算机资源有限时)、Training many models in parallel。
Batch Normalization(Batch 归一化):会使超参数搜索变得容易,使神经网络对超参数的选择更加稳定(robust)。在神经网络中已知一些中间值,假设有一些来自隐藏层的隐藏单元值从z(1)到z(m)即z[l](i),归一化第l层的隐藏单元z(i),归一化z到含均值0和标准单元方差(normalized z to have mean zero and standard unit variance),如下图。因此z的每一个分量都含有平均值0和方差1.但是我们不想让隐藏单元总是含有平均值0和方差1,因为隐藏单元有不同的分布会更有意义,因此由znorm(i)变为z~(i),这里的γ和β是学习参数。γ和β的作用是可以随意设置z~(z tilde)的平均值。采用Batch Normalization后会使用现在的z~(i)替代原来的z(i)已方便神经网络的后续计算。
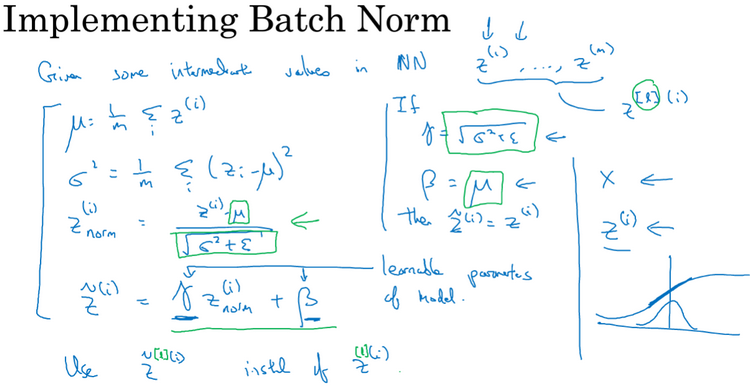
将Batch Norm应用到神经网络:如下图,Batch归一化是发生在计算z和计算a之间。
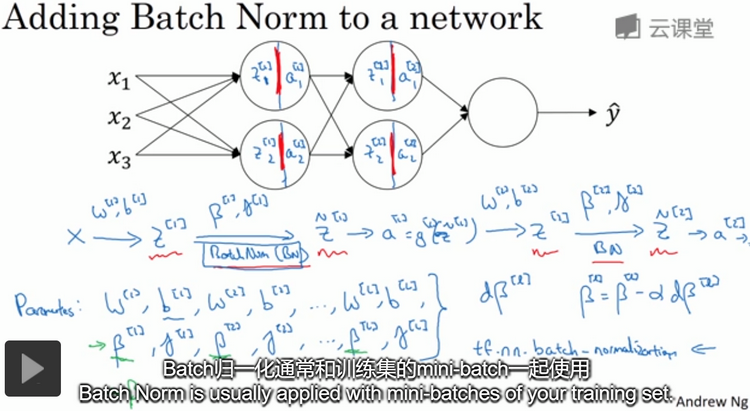
Batch归一化通常和训练集的mini-batch一起使用,如下图。参数b在Batch归一化中没有意义,所以必须去掉它,由β替代。Batch归一化一次只能处理一个mini-batch数据,它在mini-batch上计算均值和方差。

将Batch归一化应用到梯度下降法中,如下图。

Softmax layer/Softmax 激活函数:实现过程如下图所示,以识别四种类别为例。图中的输出层L为(4,1)向量,代表对应类所对应的概率。softmax用于多分类中。softmax回归或softmax激活函数将logistic激活函数推广到C类而不仅仅是两类。
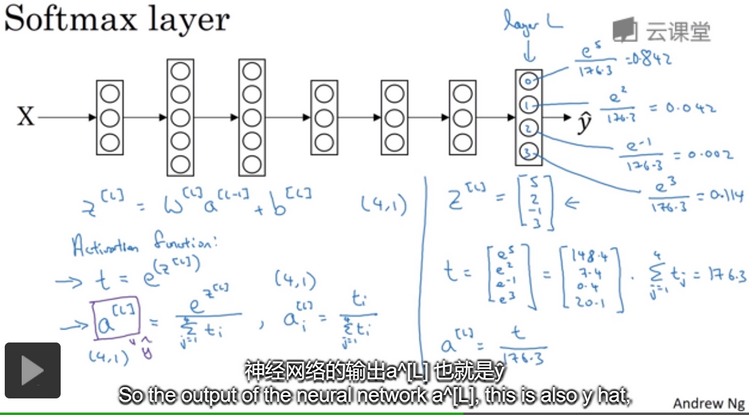
softmax中用到的损失函数(loss function):实现过程如下图所示,以识别四种类别为例。

深度学习软件框架:Caffe/Caffe2、CNTK、DL4J、Keras、Lasagne、mxnet、PaddlePaddle、TensorFlow、Theano、Torch。每一个框架都是针对某一个特定用户或开发者群体的。
选择深度学习框架的标准:便于编程;运行速度;框架是否真的开放(truly open)。