超参数调试、Batch 正则化和程序框架
一、超参数调试(hyperparameter tuning)
推荐的超参数重要性排序:
1、学习率(learning rate): α
2、隐藏神经单元(hidden units); mini-batch的大小 (mini-batch size); β (momentum)
3、神经网络层数(layers); 学习率衰减率(learning rate decay)
4、Adam优化算法的其它超参数,正常不用调优
参数调试的方法:
网格点选取(grid):
对每一个超参数取一系列不同的值, 组成一个大表包含所有的组合,然后从头到尾一个一个试。超参数比较少的情况下使用。
随机选择(select random values):
对每一个超参数随机选取不同的值组合成一个实验组合, 然后进行调试,重复随机选取。超参数较多的情况下使用,通常神经网络采取这种方式。
粗超到精细(coarse to fine):
先进行比较粗超的调试,如果发现在某一区域里的点效果都比较好,对这个的小区域进行更精细的调试。
选择超参数的合理范围(appropriate scale):
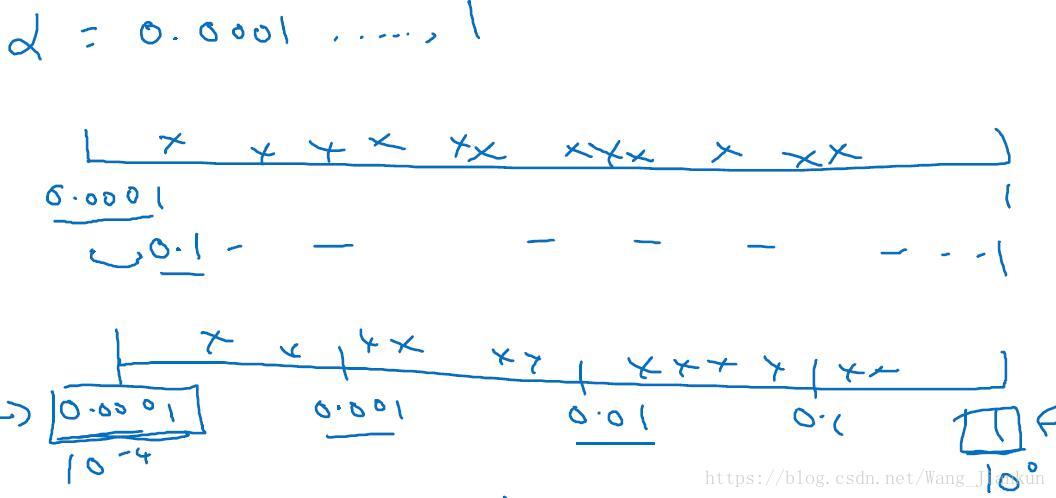
在 0.0001~1 的范围内进行进行均匀随机取值,则有90%的概率选择到 0.1∼1 之间,而只有10%的概率选择到0.0001∼0.1之间,显然是不合理的。合理的选择应该是对于不同比例范围随机选取的概率一样,如在 0.0001∼0.001、0.001∼0.01、0.01∼0.1、0.1∼1 中随机选择的概率一样。称为对数坐标选择,即logx。
python实现代码:
# 在 10^a~10^b 间进行对数坐标的选择时,生成a到b的随机数,以上面为例a=-4,b=0
r = -4 * np.random.rand()
# 求学习率10^r,范围变为0.0001到1
learning_rate = 10 ** r 超参数调试的不同策略(Panda & Caviar):
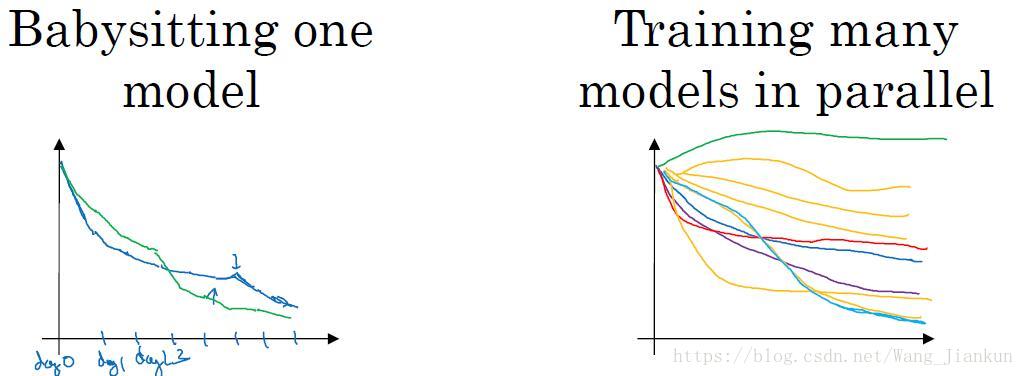
计算资源有限时:使用Panda策略(左图),每次仅调试一个模型,不断查看效果并相应的修改超参数;
计算资源充足时:使用Caviar策略(右图),同时并行调试多个模型,选取其中最好的模型。
二、Batch 正则化(batch normolization)
Batch 正则化:
类似于我们对input进行归一化,Batch 正则化是对每一层的每个z(不是a)进行归一化,起到加速训练的作用。公式如下:ε的作用就是不让分母过小。
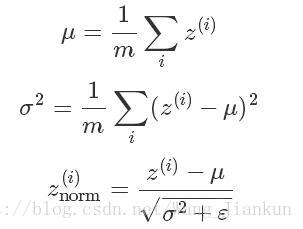
这样所有的z都变成了平均值为0、方差为1的分布,但我们不希望隐藏层的单元总是如此,也许不同的分布会更有意义,所以进行下式计算:

这个式子的含义就是z可以还原会没有归一化的时候,也可以还原一部分,也可以不还原。这就使得 γ 和 β 需要被学习变成了超参数,可以用梯度下降进行更新。
将Batch正则化拟合进神经网络(Fitting Batch Norm into a neural network):

因为z[l]=w[l]*a[l−1]+b[l],对z[l]进行归一化使其均值为0,标准差为1的分布,所以无论b[l]值为多少,在归一化的过程中都会被减去,所以可以将b[l]去掉,或者将其置零。之后由β和γ进行重新的缩放,其实β[l]等效于b[l]的功能。
Batch正则化梯度下降的实现(implementing gradient descent)
主要就是用把z[l] 替换为经过正则化的z˜[l],还有删除b[l]这个参数:

Batch Norm为什么有效:
1、类似于归一化输入,优化cost function的形状,加速迭代
2、因为对z进行正则化,使其值保持在相同的均值和方差的分布上。一定程度上减小z的变化,即减小了前层的参数更新对后层网络数值分布的影响,使得输入后层的数值变得更加稳定。另一个角度就是可以看作,Batch Norm 削弱了前层参数与后层参数之间的联系,使得网络的每层都可以自己进行学习,相对其他层有一定的独立性,这会有助于加速整个网络的学习。
Batch Norm有轻微的正则化效果:
这只是顺带产生的副作用,好坏不定,不能以此来作为正则化的工具。

测试时如何进行 Batch Norm( Batch Norm at test time):
训练时对每个Mini-batch使用Batch Norm时,可以计算出均值μ和方差σ2。但是在测试的时候,我们需要对每一个测试样本进行预测,计算单个样本的均值和方差没有意义。因此需要事先给出均值μ和方差σ2,通常的方法在训练每个Mini-batch时,缓存使用指数加权平均求出的均值μ和方差σ2,当训练结束的时候,可以得到指数加权平均后的均值μ和方差σ2并把它用于测试集的 Batch Norm 的计算,进而对测试样本进行预测。
三、Softmax回归(Softmax Regression)
二分类的时候使用 Logistic Regression,即得出是该类别的概率。多分类的时候实现相同作用的叫做 Softmax Regression,即得出和为1的各个类别可能的概率。预测时将最大的概率值所对应的类别作为预测类别。
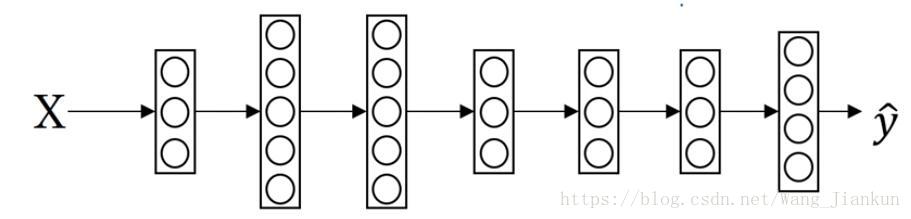
只要把最后一层的 hidden unit 的个数改为要分类的类别数即可。
softmax计算:
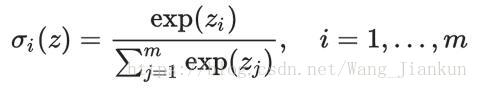
loss function–交叉熵(cross entropy):

cost function:
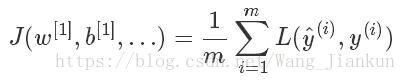
softmax层的梯度:
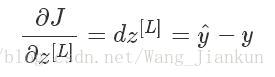
四、深度学习框架( Deep learning frameworks)
各种深度学习的框架和选择框架的建议:

tensorflow框架的编程例子:
