1.训练集(training set)、验证集(开发集dev set)、测试集(test set)
训练集用来训练算法,验证集用来选择模型,测试集用来评估模型。
模型划分:
数据量小,一般70%、0%(无验证集)、30%或60%、20%、20%;
数据量大(eg:100万数据),可以98%、1%、1%。
如何解决训练集与验证集/测试集不匹配问题?
举一个识别猫的二分类问题,假若训练采用的是网络爬取的猫图片(分辨率高、制作精良),测试集用的是用户手机上传的猫图形(较模糊、干涉物多)。可以做误差分析(分析训练集和测试集存在的差异),人为加工训练集,可以将测试集抽一部分混进训练集,确保同一分布。
结果为 训练集: 网络 + 手机 ; 验证集/测试集 : 手机
人为加增声不能重复加,否则容易过拟合。
2.高偏差(high bias)和高方差(high variance)区别?
数据不匹配问题
假设 a = 人类误差、训练误差的差距 , b = 训练误差、测试误差的差距
欠拟合(a)等价于高偏差,过拟合(b)等价于高方差。
eg:
训练误差: 1% 15% 15% 0.5%
验证误差: 11% 16% 30% 1%
第一种情况:过拟合,训练得不错,但验证误差大。
第二种情况:欠拟合,训练就不行,验证和训练差不多。
第三种情况:过拟合+欠拟合,训练得不行,验证更差。
第四种情况:都挺好
数据不匹配:训练集误差、训练-开发集误差的差距

3.正则化L1、L2区别?
L1是参数绝对值之和,L2是平方之和
相同点:都用于避免过拟合
不同点:L1可以让一部分特征的系数缩小到0,从而间接实现特征选择。所以L1适用于特征之间有关联的情况。
L2让所有特征的系数都缩小,但是不会减为0,它会使优化求解稳定快速。所以L2适用于特征之间没有关联的情况
L1和L2的优点可以结合起来,这就是Elastic Net
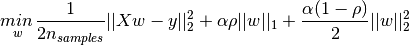
对于稀疏性的解释:L1求导为一个常数,L2求导为一次参数W,0附近时,L1导数比L2大,经过多次梯度下降,L1参数W可以取0值,L2参数W只会趋近于0。
从数学求导的角度看:
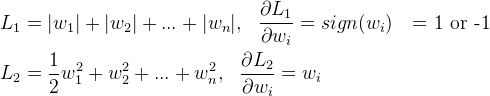
从几何空间的角度看:
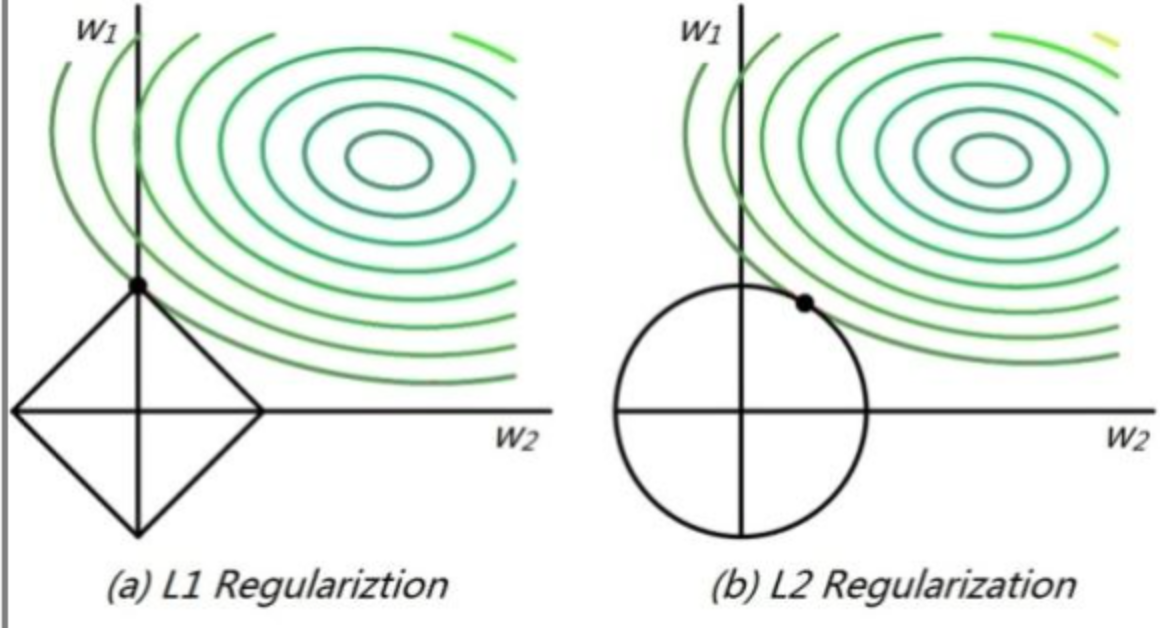
高维我们无法想象,简化到2维的情形,如上图所示。其中,左边是L1图示,右边是L2图示,左边的方形线上是L1中w1/w2取值区间,右边得圆形线上是L2中w1/w2的取值区间,绿色的圆圈表示w1/w2取不同值时整个正则化项的值的等高线(凸函数),从等高线和w1/w2取值区间的交点可以看到,L1中两个权值倾向于一个较大另一个为0,L2中两个权值倾向于均为非零的较小数。这也就是L1稀疏,L2平滑的效果。
4.其它正则化方法
1) data augmentation
2) early stopping
类似于L2正则化
优点:只进行一次梯度下降,就可以得到参数W的较小、中间、较大值,而无需尝试L2正则化中超参数λ的很多值。
缺点:没有解决求损失函数最优解和过拟合的平衡问题(这一点比L2差)
5.为什么要归一化输入特征?
Batch Normalization 流程 详细
Batch Normlization 为什么起作用 ?
Batch Norm 正则化效果
归一化输入需要两个步骤:
第一步是零均值化,即每个元素减去均值操作,公式如下:

结果如下图:

第二步是,归一化方差,上图中,特征x1的方差比特征x2的方差要大的多,处理如下:

最后,数据分布形式如下图:
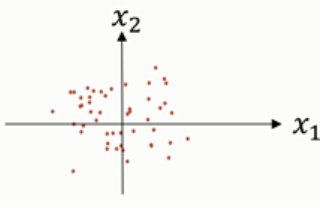
此时,x1和x2的方差都等于1。
代价函数定义: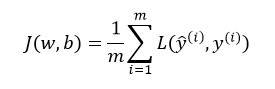
如果不用输入特征的范围差别很大,如x1在(0,1),x2在(0,100),代价函数将是一个非常狭长的形状,必须用小的学习率(大了可能直接偏离函数的范围)。
如图所示:
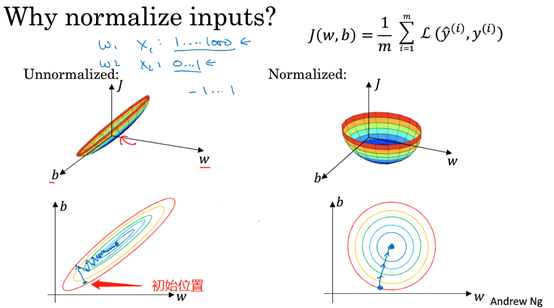
总结:归一化的目的是让输入特征都处在相似范围内,加快训练速度,也更容易优化。
Batch Normalization 又称批归一化
以神经网络中某一隐藏层的中间值为例:
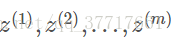
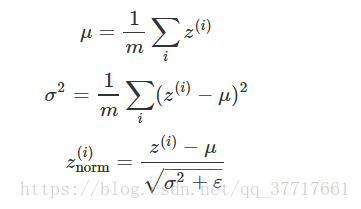
到这里所有z的分量都是平均值为0和方差为1的分布,但是我们不希望隐藏层的单元总是如此,也许不同的分布会更有意义,所以我们再进行计算:

这里γ和β是可以更新学习的参数,如神经网络的权重w一样,两个参数的值来确定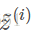

Batch Normaliztion 起作用的原因
①类似于普通归一化的原理。对输入特征做归一化,改变损失函数的形状,使得每次迭代都可以更接近函数最小值点,从而加速训练。只是Batch Normaliztion是对激活值a之前的线性加权值z做归一化,从而调整到同一分布。
②可以使得权重比网络更滞后或更深层。前一层的z[l-1]值变化 ,但是其均值和方差不变,这使得输入后层的值更加稳定,削弱了前后层之间的联系,加快学习。
Batch Norm 正则化效果
这是因为在使用Mini-batch梯度下降的时候,每次计算均值和偏差都是在一个Mini-batch上进行计算,而不是在整个数据样集上,这样就在均值和偏差上带来一些比较小的噪声。那么用均值和偏差计算得到的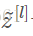
所以和Dropout相似,其在每个隐藏层的激活值上加入了一些噪声,(这里因为Dropout以一定的概率给神经元乘上0或者1)。所以和Dropout相似,Batch Norm 也有轻微的正则化效果。
这里引入一个小的细节就是,如果使用Batch Norm ,那么使用大的Mini-batch如256,相比使用小的Mini-batch如64,会引入跟少的噪声,那么就会减少正则化的效果。
6.参数初始化方法总结
①小随机数初始化
W = 0.001* np.random.randn(nn_input_dim,nn_hdim)
②Xavier初始化

目的是让输入层和输出层的方差一致,让网络中的信息更好地流通
一般情况下,

7.指数加权平均和偏差修正
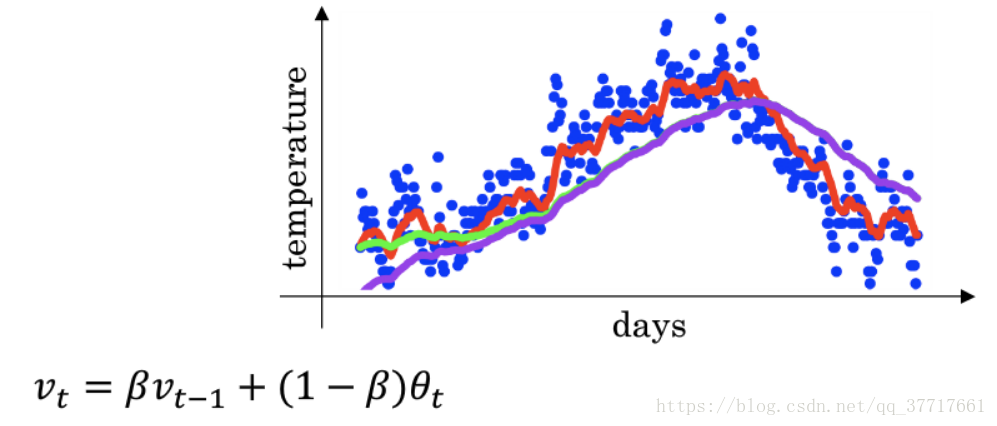
之所以称为指数加权平均是因为权重系数β随着指数递减。
上图是一个温度变化的栗子,为0.9时,得到的是红线,为0.98,得到的是绿线,为0.5时,得到的是黄线.
物理意义:①平稳性:β越接近于1,说明对过去结果依赖越强;②时效性:随着β的衰减,对当前结果(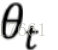
但是使用指数加权平均,前期取值对后面的结果有很大的影响(比如v0=0的情况) 引用

8.神经网络中加速训练的方法
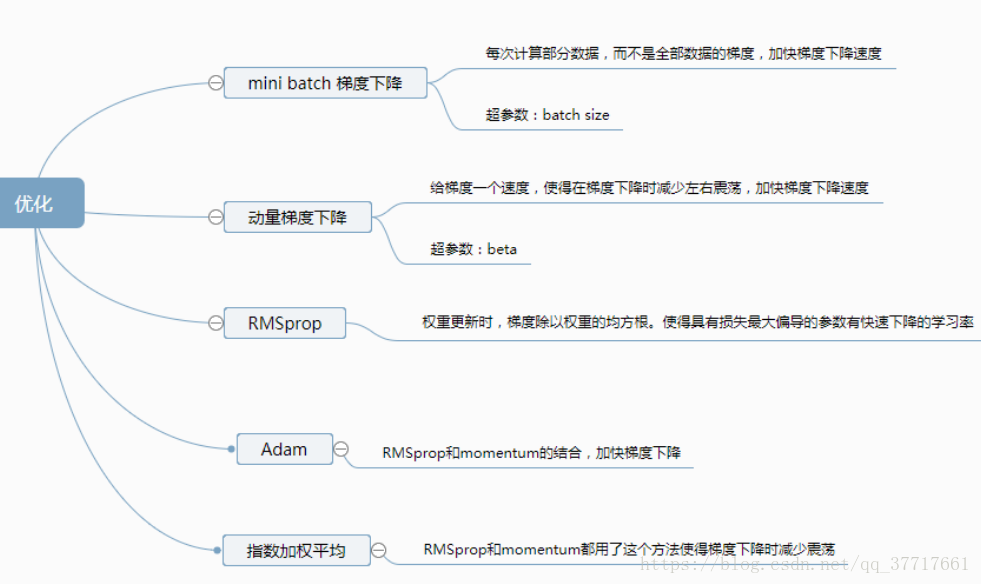
普通的梯度下降之所以比较慢,是因为:参数更新时用到的梯度相当于当前的加速度,如果下次更新的方向和当前相反,由于没有当前速度的限制,不用等速度降为0就可以立马转变方向,这样产生很多小震荡(感觉最优目标不明确的样子,白走了很多冤枉路)。我们希望的是加快横轴的速度(直逼目标),缓慢纵轴的速度(冤枉路)。

9.超参数调试处理、为超参数选择合适的范围
超参数调试处理(重要性从上往下):
1.α
2.β(momentum)、mini_batch size
3.num_layer、learning_rate_decay
4.β1、β2、ε (Adam,一般设0.9、0.999、10^(-8),可以不动)
在超参数选择的时候,一些超参数是在一个范围内进行均匀随机取值,如隐藏层神经元结点的个数、隐藏层的层数等。
在超参数范围中,随机取值可以提升你的搜索效率,但随机取值并不是在有效值范围内的随机均匀取值,而是选择合适的标尺。
假设你在搜索超参数 α 学习速率,假设你怀疑其值最小是 0.0001 ,或最大是 1,如果你画一条从 0.0001 到 1 的数轴,沿其随机均匀取值,那 90% 的数值将会落在 0.1 到 1 之间,结果就是 在 0.1 到 1 之间 应用了 90% 的资源,而在 0.0001 到 0.1 之间 只有 10%的搜索资源,这看上去不太对(不够精确),反而 用对数标尺搜索超参数的方式会更合理,因此这里不使用线性轴,分别依次取 0.0001、0.001、0.01、1,在对数轴上均匀随机取点,这样 在 0.0001 到 0.001 之间 就会有更多的搜索资源可用,还有在 0.001 到 0.01 之间等等。在Python中 你可以这样做,使 r = -4 * np.random.rand(),然后 随机取值 α=10^r,所以 第一行可以得出r∈[-4,0],那α会在10^(−4)和 10^(0) 之间。
另一个棘手的例子是给β取值,用于计算指数的加权平均值,假设你认为β是 0.9 到 0.999 之间的某个值,也许这就是你想搜索的范围,所以你要做的就是在 [-3,-1] 里随机均匀的给 r 取值,你设定了1−β=10^r 所以β=1−10^r,然后这就变成了你的超参数随机取值,在特定的选择范围内,希望用这种方式可以得到想要的结果,你在 0.9 到 0.99 区间探究的资源,和在 0.99 到 0.999 区间探究的一样多。
关于为什么我们要这样做 为什么用线性轴取值不是个好方法,这是因为当β接近 1 时,所得结果的灵敏度会变化 。即使β有微小的变化,如果β在 0.9 到 0.9005 之间取值,无关紧要 你的结果几乎不会变化,但β值如果在 0.999 到 0.9995 之间,这会对你的算法产生巨大影响 对吧?在这两种情况下 是根据大概 10 个值取平均,但这里它是指数的加权平均值,基于 1000 个值 现在是 2000 个值,因为这个公式1/(1−β),当β接近 1 时 β就会对细微的变化变得很敏感。
- 代码实现:
r = -4 * np.random.rand() # r in [-4,0]
learning_rate = 10 ** r # 10^{r}