调试处理
关于超参数的重要性:
,
默认值经常为0.9,关于Adam算法通常默认是
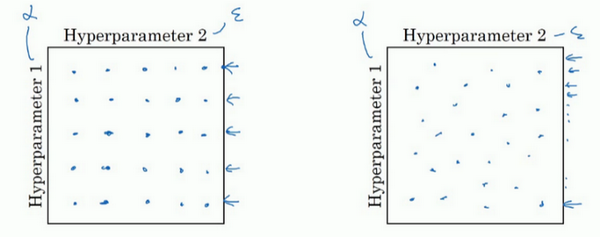
在尝试超参数时,建议随机选择点,如图二,因为我们很难提前知道哪个超参数重要,而某些超参数的确比其它的重要。比如说有两个参数,极限来看,如果一个参数根本不重要,而另外一个参数按照图示只尝试了5次,相比而言,随机取数效果要更好,因为可以尝试25个不同的值。
超参数的取值的规则是由粗糙到精细,逐步细化
为超参数选择合适的范围
超参数应该选择的标尺:
以学习率为例,如果你认为超参数在0.0001到1之间,均匀取值的话你会发现0.1到1占据了90%,而0.0001到0.1只占了10%,这显然不合理。我们可以应用python的随机函数
r = -4*np.random.rand(),取得
然后我们在每个均匀区间内为上述超参数取值。总结一下,就是对所取得数取对数,例如
,取对数后获取的区间
,就是我们随机的标尺的区间。
同样理解在给
取值时从0.9到0.999,考虑这个问题我们可以看
,在0.001到0.1间,因为我们要在
随机取r值,那么
,然后就变成了在特定的区间内均匀取值。之所以按照标尺来取值,对于
而言,越靠近1,带来的影响越大,平均天数可近似看做
,当
接近1时,就会对细微的变化变得敏感。
超参数调试的实践
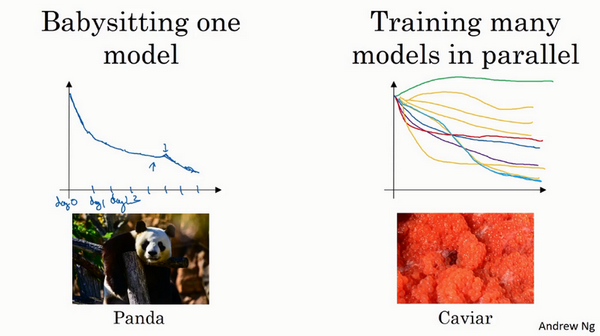
一种方式是pandas,在计算资源不足的情况下,照看一种模型,每天做调试。
另一种方式是同时实验多种模型,多个模型平行实验,当具有充足的计算资源时建议选择此方法。
归一化网络的激活函数
是指对函数的输入,做减去均值除以方差,类似于之前介绍的在做数据预处理时,可以将学习问题的轮廓变得额更圆便于梯度下降。
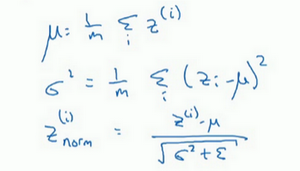
关于从
还是从激活值a做均一化,尚有争议,本文建议从
做归一化。
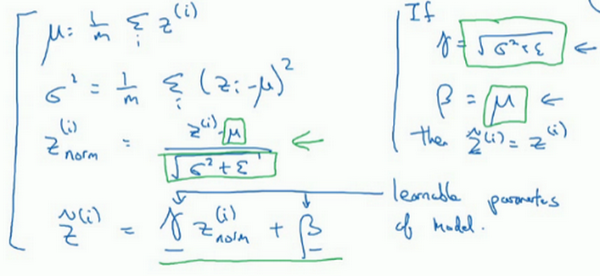
当我们对
值做标准化后,均值为0方差为1,我们不会想让隐藏单元总是标准分布,因为可能不同分布会有其他的意义,因为我们对
做处理,新的
是我们要学习的参数,事实上,
分别等于标准化时的方差和均值时,新的
值就等于标准化的
。因为,当对
赋予不同的值,就可以构造其他的不同分布。
注意:
不同于Momentum中的超参数。
注意:归一化是对一个mini batch进行操作,单位是一个神经层,
和b的维度相同
。
将batch norm拟合到神经网络中
应用batch norm后的传播图,在反向传播时,我们会更新
的参数,可以利用梯度下降、Momentum、Adam等方法。
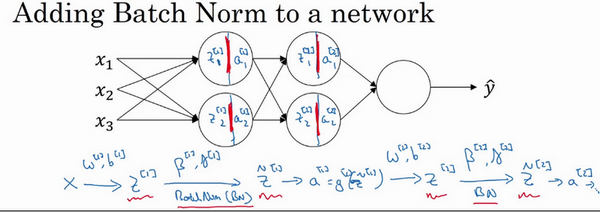
在tensorflow,我们可以方便的调用tf.nn.batch_normalization来实现归一化
在batch归一化后,b的值应该去掉,因为均一化会使得数据具有相同的均值,而b便不再具有意义,通过缩放的参数
取代了b的作用
batch norm为什么效果显著
第一点,类似于数据预处理,可以让特征在相同的范围学习
第二点,使权重比你的网络更滞后。举个列子,类似于从训练的无色猫到测试的有色猫,batch norm相当于做了一个映射,通过指定每一层输入的分布,限制了前一层的表达性,但增加了后续学习的健壮性(最后一层是否应用batch norm?),减弱了前后层的联系,增强了每一层的学习独立。
第三点,batch norm同时有轻微的正则化效果,因为batch norm实在一个mini batch进行的,会有一定的噪声,通过均值和方差来进行缩放的,和dropout类似,它往每个激活层增加了噪音,使得学习过程不依赖于任何一个隐藏单元。因而会有这样一种情况,当你应用一个较大的mini batch时,减少了噪音,因而减少了正则化效果,这是dropout一个奇怪的性质。
测试时的batch norm
测试时,我们可能不能将一个mini batch 的大数量样本同时处理,我们需要其他方式估算均值和方差,这里用到指数加权平均。
通过训练集每一个mini btach的(每一层的均值和方差)的滑动平均值,利用最后一个mini batch的均值和方差到测试集上,这一点可以利用tenssorflow的滑动平均模块实现。
本文参考:
第三周 超参数调试、Batch正则化和程序框架