scrapy是python最有名的爬虫框架之一,可以很方便的进行web抓取,并且提供了很强的定制型,这里记录简单学习的过程和在实际应用中会遇到的一些常见问题
一、安装
在安装scrapy之前有一些依赖需要安装,否则可能会安装失败,scrapy的选择器依赖于lxml,还有Twisted网络引擎,以下是windows安装:
Scrapy的安装:
1. scrapy需要安装第三方库文件,lxml和Twisted
2. 下载地址:https://www.lfd.uci.edu/~gohlke/pythonlibs/
3.下载好文件之后,在DOS命令下pip install 文件的位置(lxlm)
安装完成就可以安装:pip install scrapy
还需要安装 win32(启动蜘蛛的时候会提示安装,根据python版本来的我 32位)pip install pypiwin32
二、基本使用
1. 初始化scrapy项目
我们可以使用命令行初始化一个项目,(注意创建的路径就是你在命令行下的根目录)

初始化完成后会产生以下文件
scrapy.cfg: 项目的配置文件 tutorial/: 该项目的python模块, 在这里添加代码 items.py: 项目中的item文件 pipelines.py: 项目中的pipelines文件. settings.py: 项目全局设置文件. spiders/ 爬虫模块目录 |
2. scrapy的处理流程
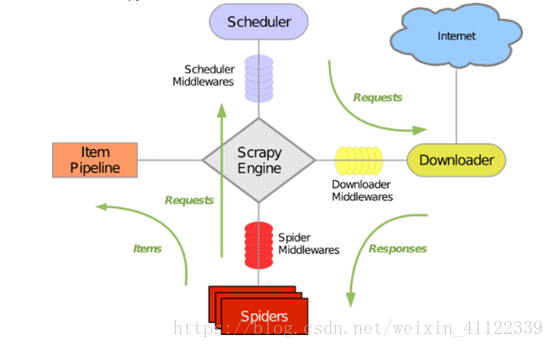
Scrapy运行流程(专业)
1 引擎访问spider,询问需要处理的URL链接,spider收到请求,将需要处理的URL告诉引擎,然后将URL给引擎处理。
2 引擎通知调度器,调度器得到通知将URL排序入队,并加以处理。
3 引擎通知调度器,调度器将处理好的request返回给引擎
4 引擎接收到request后告诉下载器,按照setting中配置的顺序下载这个request的请求
5 下载器收到请求,将下载好后的东西返回给引擎。如果下载失败,下载器会通知引擎,引擎再通知调度器,调度器收到消息后会记录这个下载失败的request。
6 引擎得到下载好的东西后,通知spider(这里responses默认是交给def parse()函数处理)
7 Spider收到通知后,处理接收的数据
8 Spider处理完数据后返回给引擎两个结果:一个是需要跟进的URL,另一个是获取到的item数据。
9 引擎将接收到的item数据交给管道处理,将需要跟进的URL交给调度器处理。重复循环直到获取完需要的全部信息。
简化描述scrapy的组成
spiders:爬虫模块,负责配置需要爬取的数据和爬取规则,以及解析结构化数据
items:定义我们需要的结构化数据,使用相当于dict
pipelines:管道模块,处理spider模块分析好的结构化数据,如保存入库等
middlewares:中间件,相当于钩子,可以对爬取前后做预处理,如修改请求header,url过滤等
看一个列子:
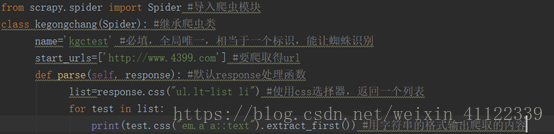
我们可以在dos下执行以下两条命令:
1,Scrapy runspider 要执行的模块名.py -o 要存储的名称.json&.csv&.xml
这个命令是把爬取的内容存储到一个固定文件里,并输入在控制台中
2,scrapy crawl 蜘蛛名
这个命令是把爬取的内容输出到控制台下
三、Scrapy类
如上面的DmozSpider类,爬虫类继承自scrapy.Spider,用于构造Request对象给Scheduler
1. 常用属性与方法
属性
name:爬虫的名字,必须唯一(如果在控制台使用的话,必须配置)
start_urls:爬虫初始爬取的链接列表
parse:response结果处理函数
方法
parse:response到达spider的时候默认调用,如果在Request对象配置了callback函数,则不会调用,parse方法可以迭代返回Item或Request对象,如果返回Request对象,则会进行增量爬取
2. Request与Response对象
每个请求都是一个Request对象,Request对象定义了请求的相关信息(url, method, headers, body, cookie, priority)和回调的相关信息(meta, callback, dont_filter, errback),通常由spider迭代返回
其中meta相当于附加变量,可以在请求完成后通过response.meta访问
请求完成后,会通过Response对象发送给spider处理,常用属性有(url, status, headers, body, request, meta,)