scrapy介绍
Scrapy,Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本又提供了web2.0爬虫的支持。
scrapy data flow(流程图)
Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是事件驱动的,并且比较适合异步的代码。对于会阻塞线程的操作包含访问文件、数据库或者Web、产生新的进程并需要处理新进程的输出(如运行shell命令)、执行系统层次操作的代码(如等待系统队列),Twisted提供了允许执行上面的操作但不会阻塞代码执行的方法。
下面的图表显示了Scrapy架构组件,以及运行scrapy时的数据流程,图中红色箭头标出。
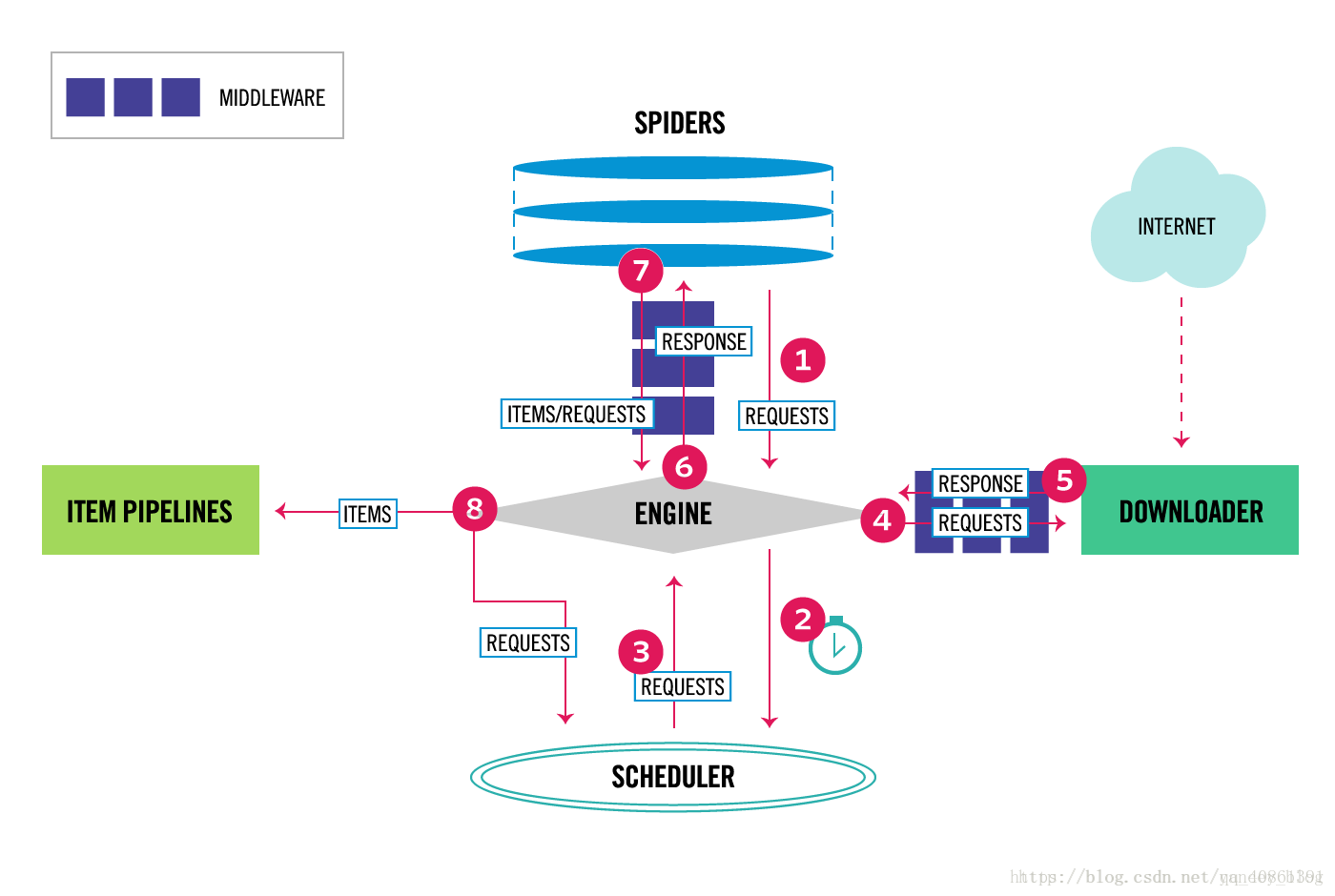
Scrapy数据流是由执行的核心引擎(engine)控制,流程是这样的:
- 爬虫引擎获得初始请求开始爬取
- 爬虫引擎开始请求调度程序,并准备对下一次的请求进行爬取。
- 爬虫调度器返回下一个请求给爬虫引擎。
- 引擎请求发送到下载器,通过下载中间件下载网络数据
- 一旦下载器完成页面下载,将下载结果返回给爬虫引擎。
- 引擎将下载器的响应通过中间件返回给爬虫进行处理。
- 爬虫处理响应,并通过中间件返回处理后的items,以及新的请求给引擎
- 引擎发送处理后的items到项目的管道,然后把处理结果返回给调度器,调度器计划处理下一个请求抓取
- 重复该过程,直到爬取完所有的url请求
上图展示了scrapy的所有组件工作流程,下面单独介绍各个组件:
爬虫引擎(ENGINE)
爬虫引擎负责控制各个组件之间的数据流,当某些操作触发事件后都是通过engine来处理。下载器
通过engine请求下载王叔数据并将结果响应给engine。调度器
调度接收来engine的请求并将请求放入队列中,并通过事件返回给engineSpider
Spider发出请求,并且处理engine返回给它下载器响应的数据,以items和规则内的数据请求(url)返回给engine管道项目(item pipeline)
负责处理engine返回spider解析后的数据,并且将数据持久化,例如将数据存入数据库或者文件。- 下载中间件
下载中间件是engine和下载器交互组件,以钩子(插件)的形式存在,可以代替接收请求、处理数据的下载以及将结果响应给engine。 - spider中间件
spider中间件是engine和spider之间的交互组件,以钩子(插件)的形式存在,可以代替处理response以及返回给engine items及新的请求集。
如何创建scrapy环境和项目
# 创建虚拟的环境
virtualenv --no-site-packages 环境名
# 进入虚拟环境文件夹
cd 虚拟环境文件夹
# 运行虚拟环境
cd Scrapits
activate
# 可以更新pip
python -m pip install -U pip
# 在虚拟环境里 windows下安装Twisted-18.4.0-cp36-cp36m-win32.wh
pip insttall E:\Twisted-18.4.0-cp36-cp36m-win32.wh
# 在虚拟环境中安装scrapy
pip install scrapy
# 创建自己的项目,(可以单独创建项目文件夹) 在虚拟环境中切换到创建的文件下
scrapy startproject 项目名字
# 创建spider(蜘蛛)
scrapy genspider 蜘蛛名字 允许访问的地址
例如:
scrapy genspider movie movie.douban.com
scrapy项目结构
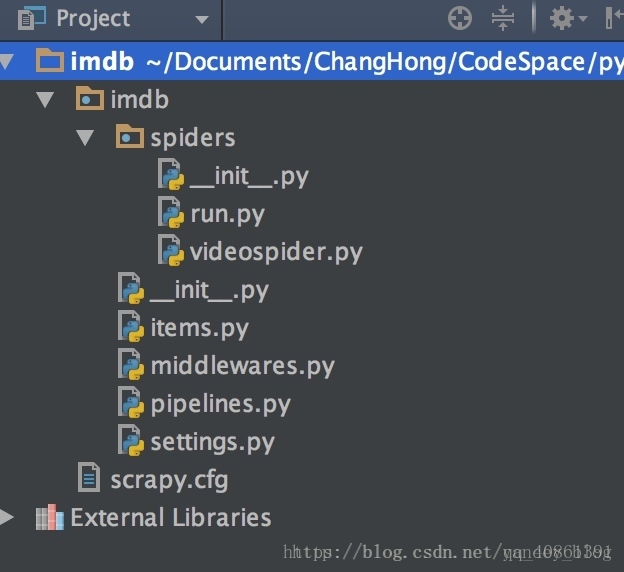
- items.py 负责数据模型的建立
- middlewares.py 中间件
- pipelines.py 负责对spider返回数据的处理。
- settings.py 负责对整个爬虫的配置。
- spiders目录 负责存放继承自scrapy的爬虫类。
- scrapy.cfg scrapy基础配置