scrapy的最通用的爬虫流程:UR2IM
U:URL
R2:Request 以及 Response
I:Item
M:More URL
在scrapy shell中打开服务器一个网页
cmd中执行:scrapy shell http://www.baidu.com (可以使用exit()退出)

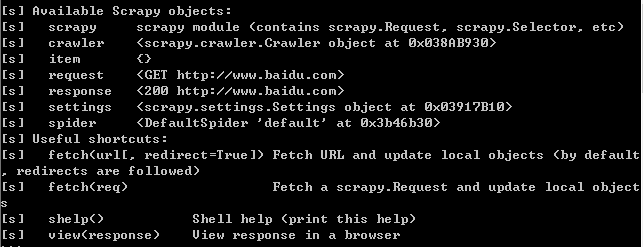
此时,scrapy执行一个默认的GET请求,并得到一个状态码为200的响应
可以使用response.body打印页面源码(或部分字符)
例:response.body[:50]

同时,也可使用response.xpath(' ')来测试XPath表达式的效果
例:response.xpath('//*[@id="su"]') 获取百度一下按钮处的源码
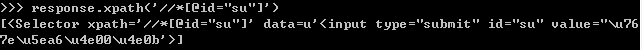
response.xpath('//*[@id="su"]').xpath('.//@value') 获取上述局部源码中的value属性值
注:.//@value是相对XPath表达式;用于获取selector的得到的局部源码中的信息

response.xpath('//*[@id="su"]').xpath('.//@value').extract() 获取上述结果中的源码(源码不等于selector,等于data值)

下一步操作是:从响应中将数据抽取到Item的字段中(通常使用/text()获取文本字段)
通常,我们使用//*[@id="su"][1]这种形式。
目的:为防止结尾某些细微之处的嵌套信息没有注意到