作者经过几周的python爬虫实践之后,深入学习了一下scrapy这个爬虫框架,现将一些基本知识和代码总结整理一下,以备后查。
1.scrapy的下载安装
普通方法就是用pip install scrapy( 不写明版本号会自动下载最新版本)下图安装被手动取消了,因为作者电脑里有了。。。。
作者由于还要用到python数据分析的一些包,numpy等等,所以偷懒直接安装了anaconda,没有基础的小伙伴也可以用这种方法,anaconda的下载,安装和普通软件相同,自带了一些常用的库,免去安装烦恼(好懒)
2.scrapy的命令行使用
这部分网上很多博客都有总结,不需要背,理解会用主要的命令(startproject crawl fetch list genspider.....)即可,下面列几条常用场景下的命令,注意下项目命令和全局命令的区别,就是字面意思的区别。
2.1startproject:这个命令是用来创建scrapy项目的,在控制台中进入希望创建代码的目录下,输入命令:scrapy startproject firstspider即可创建,创建完成之后的项目自动生成了items pipeline spider等文件和文件夹,这些文件的详细作用后面再谈。
2.2genspider:这个命令是用来创建爬虫文件的,进入firstspider文件夹可以看到,有一个spider文件夹,这个文件夹下存放的就是具体的爬虫,genspider命令会在spider文件夹下创建爬虫。进入创建完成的目录下 cd firstspider/firstspider; ; scrapy genspider -t basic spiderone 命令执行成功截图如下:
此处需说明一下,-t参数的作用是基于自带的爬虫模版创建自己的爬虫,原生模版有basic crawl xmlfeed csvfeed四种,可用scrapy genspider -l命令查看,四种模版的详解此处不做说明,小伙伴可以通过官方文档了解,我们一般选用basic或crawl即可。
2.3 list:这个命令没什么难度,作用是查看本scrapy项目下可用的爬虫有哪些,自己动手试一下,可以看到2.2中创建的spiderone
2.4 crawl:这个命令是启动爬虫的,我们创建了spiderone.py这个爬虫文件之后,根据功能需求编写代码之后可以用命令scrapy crawl spiderone开始执行
2.5 fetch用来显示爬去过程,是一个全局命令,不管有没有有项目都能运行。示例如下:scrapy fetch http://www.baidu.com
更多的命令可以用scrapy -h来看,值得注意的是,在项目文件夹中用scrapy -h看到的结果和在项目文件夹外看到的不一样,全局和项目命令的区别。
3.scrapy主要文件作用
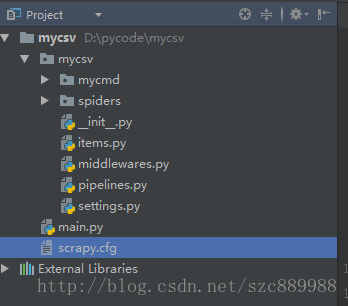
这是一个scrapy项目的基本结构,items.py这个文件的作用是保存爬下来的数据到item对象中,相当于是存储爬得的数据的容器,要存储几个字段,分别把这些字段field化即可,举例如下:
name = scrapy.Field()
email = scrapy.Field()
settings.py是项目一些配置选项的控制文件,如代理IP池,是否遵循被爬网站robot协议等,小伙伴在遇到具体需求时去了解。爬虫文件在spider文件夹下,main.py是笔者自建的文件,用来启动爬虫。之前说过crawl命令可以启动,但我们在pycharm编辑之后,想在pycharm中运行,所以就创建这么一个文件,作为驱动。main.py的内容如下
# coding:utf-8
from scrapy import cmdline
cmdline.execute("scrapy crawl spiderone".split())本质就是通过python的控制台接口调用crawl命令。
基本介绍就到这里,抽空再写一点实际应用到scrapy的爬虫代码,和自定义创建命令的方法。
个人学习心得,有误轻喷。