一、利用Scrapy框架抓取数据
1.1 Scrapy吸引人的地方在于它是一个框架。
任何人都可以根据需求方便的修改。它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本又提供了web2.0爬虫的支持。
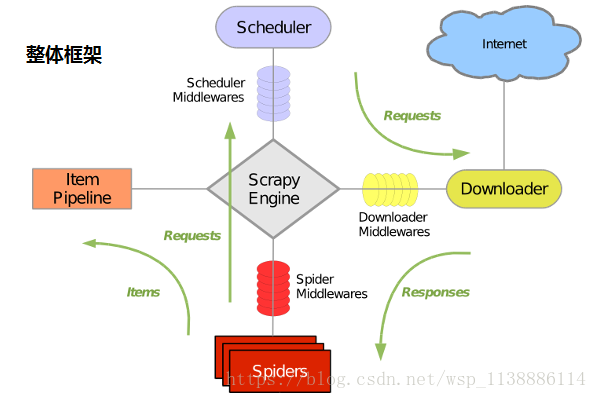
1.2、Scrapy主要包括了以下组件:
引擎(Scrapy) 用来处理整个系统的数据流处理, 触发事务(框架核心) 调度器(Scheduler) 用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回。 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 下载器(Downloader) 用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的) 用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 项目管道(Pipeline) 负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。 当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。 下载器中间件(Downloader Middlewares) 位于Scrapy引擎和下载器之间的框架, 主要是处理Scrapy引擎与下载器之间的请求及响应。 爬虫中间件(Spider Middlewares) 介于Scrapy引擎和爬虫之间的框架, 主要工作是处理蜘蛛的响应输入和请求输出。 调度中间件(Scheduler Middewares) 介于Scrapy引擎和调度之间的中间件, 从Scrapy引擎发送到调度的请求和响应。1.3、Scrapy运行流程大概如下:
◆ 引擎从调度器中取出一个链接(URL)用于接下来的抓取 ◆ 引擎把URL封装成一个请求(Request)传给下载器 ◆ 下载器把资源下载下来,并封装成应答包(Response) ◆ 爬虫解析Response ◆ 解析出实体(Item),则交给实体管道进行进一步的处理 ◆ 解析出的是链接(URL),则把URL交给调度器等待抓取1.4 安装模块(可以在Anaconda环境中执行)
依次执行下列命令安装
pip install lxmllxml是个非常有用的python库,它可以灵活高效地解析xml, 与BeautifulSoup、requests结合,是编写爬虫的标准姿势。
pip install zope.interfacePython支持多继承,但是不支持接口,zope.inteface是其三方的接口实现库, 在twisted中有大量使用
pip install twisted若安装出错:error: Microsoft Visual C++ 14.0 is required. 安装 vc_redist15.x86.exe 一个Twisted程序由reactor发起的主循环和一些回调函数组成。当事件发生了, 比如一个client连接到了server,这时候服务器端的事件会被触发执行。
pip install pyOpenSSL生成网络安全需要的CA和证书
pip install pywin32若安装出错 执行安装:Twisted-18.4.0-cp36-cp36m-win32.whl pywin32是一个Python库,为python提供访问Windows API的扩展, 提供了齐全的windows常量、接口、线程以及COM机制等等 若安装出错 下载地址:https://sourceforge.net/projects/pywin32/files/pywin32/ 下载后双击安装 若之后仍显示cannot import name '_win32stdio‘ 则cmd中运行pip install pypiwin32
pip install scrapyscrapy不同于简单的单线程爬虫,采用scrapy框架写python爬虫需要生成许多个文件, 这一件类似于java里面的web框架,许多工作都可以通过一些配置文件来完成。1.5 创建项目
实战:Scrapy结合CSS+xpath:爬取梦幻西游音乐
scrapy 不同于简单的单线程爬虫,采用scrapy 框架写python爬虫需要生成许多个文件, 这一件类似于java里面的web框架,许多工作都可以通过一些配置文件来完成。命令:
scrapy startproject Preject_name
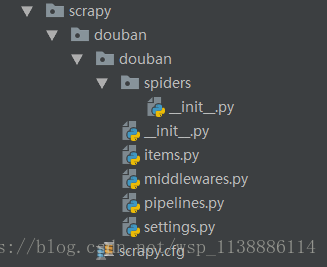
项目创建好后目录结构如下:
scrapy.cfg: 项目的配置文件 scrapyTest1/:项目的Python模块,将会从这里引用代码 scrapyTest1 /items.py:项目的items文件 用来存放抓取内容容器的文件 scrapyTest1 /pipelines.py:负责处理爬虫从网页中抽取的实体,持久化实体、验证实体的有效性、清除不需要的信息 scrapyTest1 /settings.py: 项目的设置文件 scrapyTest1 /spiders/: 存储爬虫的目录
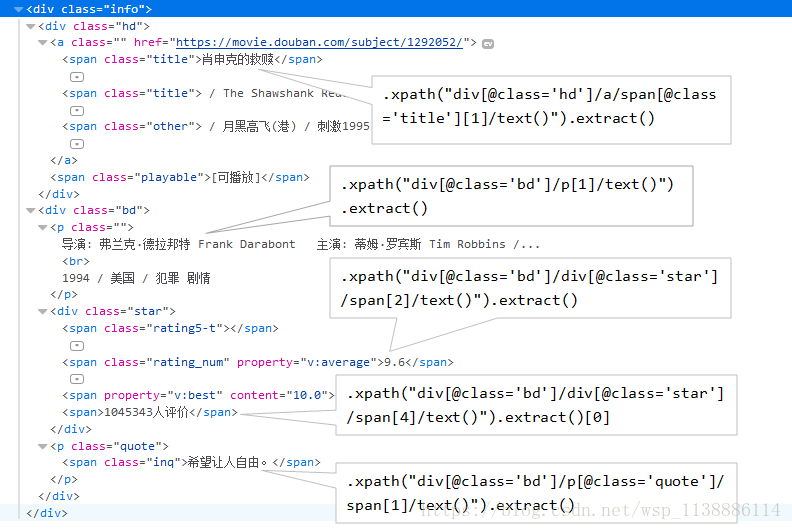
◆ 找到douban项目文件夹下的items.py文件明确需要抓取的目标 import scrapy from scrapy import Field,Item class DoubanItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() title=Field() # 电影名称 movieInfo=Field() # 电影介绍 star = Field() # 评分 critical = Field() # 评分人数 quote = Field() #经典的话 pass ◆ 在项目文件夹下的spiders文件夹下新建一个py文件,制作爬虫文件:doubanTest.py from scrapy.spiders import CrawlSpider from scrapy.http import Request from scrapy.selector import Selector from douban.items import DoubanItem # 导入items.py文件中的DoubanItem类 import re class Douban(CrawlSpider): # 继承自CrawlSpider name="doubanTest" # 爬虫文件的名称,与文件名一致,类似于Java中的类 start_urls=["http://movie.douban.com/top250"] def parse(self, response): # 定义解析器函数,获取文件内容 item=DoubanItem() # 通过item中的类DoubanItem实例化对象 selector=Selector(response) # 处理返回结果 Movies=selector.xpath('//div[@class="info"]') # 获取所有包含电影信息的div # 遍历每条div获取相应信息 for eachMovie in Movies: fullTitle=eachMovie.xpath("div[@class='hd']/a/span[@class='title'][1]/text()").extract() star=eachMovie.xpath("div[@class='bd']/div[@class='star']/span[2]/text()").extract() movieInfo = eachMovie.xpath("div[@class='bd']/p[1]/text()").extract() craticalStr=eachMovie.xpath("div[@class='bd']/div[@class='star']/span[4]/text()").extract()[0] critical=re.sub("\D","",craticalStr) # 使用空字符串代替"\D" quote=eachMovie.xpath("div[@class='bd']/p[@class='quote']/span[1]/text()").extract() if quote: # 部分电影不存在quote quote=quote[0] else: quote="无评论" 为第一步items要抓取的目标赋值 item["title"]=fullTitle item["movieInfo"]=movieInfo[0].strip() item["star"]=star item["critical"]=critical item["quote"]=quote yield item # 提交给item pipeline ◆ 在settings.py文件中添加headers,代理,保存文件位置、类型等 BOT_NAME = 'douban' SPIDER_MODULES = ['douban.spiders'] NEWSPIDER_MODULE = 'douban.spiders' USER_AGENT='Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_3) \ AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.54 Safari/536.5' FEED_URI=u'file///E:/Python_WorkSpace/Scrapy/douban/doubanFilm.csv' # 文件存放位置,绝对位置,注意使用"/" FEED_FORMAT='CSV' #保存文件格式 ◆ 在于items.py文件同级的文件夹创建主函数,运行爬虫文件,实现爬虫操作 from scrapy import cmdline cmdline.execute("scrapy crawl doubanTest".split()) # 注意执行文件的名称
二、 xpath选择器
举例: <?xml version="1.0" encoding="UTF-8"?> <bookstore> <book> <title lang="eng">Harry Potter</title> <price>29.99</price> </book> <book> <title lang="eng">Learning XML</title> <price>39.95</price> </book> </bookstore>XML 节点选择
节点是通过沿着路径或者 step 来选取的。
表达式 描述 nodename 选取此节点的所有子节点。 / 从根节点选取。 // 当前节点选择文档中的节点,而不考虑它们的位置。 . 选取当前节点。 .. 选取当前节点的父节点。 @ 选取属性。
路径表达式 结果 bookstore 选取 bookstore 元素的所有子节点。 /bookstore 选取根元素 bookstore。 注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! bookstore/book 选取属于 bookstore 的子元素的所有 book 元素。 //book 选取所有 book 子元素,而不管它们在文档中的位置。 bookstore//book 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。 //@lang 选取名为 lang 的所有属性。 谓语用来查找某个特定的节点或者包含某个指定的值的节点。
路径表达式 结果 /bookstore/book[1] 选取属于 bookstore 子元素的第一个 book 元素。 /bookstore/book[last()] 选取属于 bookstore 子元素的最后一个 book 元素。 /bookstore/book[last()-1] 选取属于 bookstore 子元素的倒数第二个 book 元素。 /bookstore/book[position()<3] 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 //title[@lang] 选取所有拥有名为 lang 的属性的 title 元素。 //title[@lang=’eng’] 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 /bookstore/book[price>35.00] 选取 bookstore 元素的所有 book 元素,且 price 元素的值须大于 35.00。 /bookstore/book[price>35.00]/title 选取 bookstore 元素中的 book 元素的所有 title 元素,且 price 元素的值须大于 35.00。 XPath 通配符可用来选取未知的 XML 元素。
通配符 描述 通配符 描述 * 匹配任何元素节点。 /bookstore/* 选取 bookstore 元素的所有子元素。 @* 匹配任何属性节点。 //* 选取文档中的所有元素。 node() 匹配任何类型的节点。 //title[@*] 选取所有带有属性的 title 元素。 使用
"|"运算符,您可以选取若干个路径。
路径表达式 结果 //book/title //book/price //title //price /bookstore/book/title //price
三、 CSS选择器
CSS选择器用于选择你想要的元素的样式的模式。
选择器 示例 示例说明 CSS .class .intro 选择所有class=”intro”的元素 1 #id firstname 选择所有id=”firstname”的元素 1 * * 选择所有元素 2 element p 选择所有元素 1 element,element div,p 选择所有元素和元素 1 element element div p 选择元素内的所有元素 1 element>element div>p 选择所有父级是 元素的 元素 2 element+element div+p 选择所有紧接着元素之后的元素 2 [attribute] [target] 选择所有带有target属性元素 2 [attribute=value] [target=-blank] 选择所有使用target=”-blank”的元素 2 [attribute~=value] [title~=flower] 选择标题属性包含单词”flower”的所有元素 2 [attribute |=language] [lang|=en] 选择一个lang属性的起始值=”EN”的所有元素 2 :link a:link 选择所有未访问链接 1 :visited a:visited 选择所有访问过的链接 1 :active a:active 选择活动链接 1 :hover a:hover 选择鼠标在链接上面时 1 :focus input:focus 选择具有焦点的输入元素 2 :first-letter p:first-letter 选择每一个元素的第一个字母 1 :first-line p:first-line 选择每一个元素的第一行 1 :first-child p:first-child 指定只有当元素是其父级的第一个子级的样式。 2 :before p:before 在每个元素之前插入内容 2 :after p:after 在每个元素之后插入内容 2 :lang(language) p:lang(it) 选择一个lang属性的起始值=”it”的所有元素 2 element1~*element2* p~ul 选择p元素之后的每一个ul元素 3 [attribute^=value] a[src^=”https”] 选择每一个src属性的值以”https”开头的元素 3 [attribute$=value] a[src$=”.pdf”] 选择每一个src属性的值以”.pdf”结尾的元素 3 [attribute*=value] a[src*=”runoob”] 选择每一个src属性的值包含子字符串”runoob”的元素 3 :first-of-type p:first-of-type 选择每个p元素是其父级的第一个p元素 3 :last-of-type p:last-of-type 选择每个p元素是其父级的最后一个p元素 3 :only-of-type p:only-of-type 选择每个p元素是其父级的唯一p元素 3 :only-child p:only-child 选择每个p元素是其父级的唯一子元素 3 :nth-child(n) p:nth-child(2) 选择每个p元素是其父级的第二个子元素 3 :nth-last-child(n) p:nth-last-child(2) 选择每个p元素的是其父级的第二个子元素,从最后一个子项计数 3 :nth-of-type(n) p:nth-of-type(2) 选择每个p元素是其父级的第二个p元素 3 :nth-last-of-type(n) p:nth-last-of-type(2) 选择每个p元素的是其父级的第二个p元素,从最后一个子项计数 3 :last-child p:last-child 选择每个p元素是其父级的最后一个子级。 3 :root :root 选择文档的根元素 3 :empty p:empty 选择每个没有任何子级的p元素(包括文本节点) 3 :target news:target 选择当前活动的#news元素(包含该锚名称的点击的URL) 3 :enabled input:enabled 选择每一个已启用的输入元素 3 :disabled input:disabled 选择每一个禁用的输入元素 3 :checked input:checked 选择每个选中的输入元素 3 :not(selector) :not(p) 选择每个并非p元素的元素 3 ::selection ::selection 匹配元素中被用户选中或处于高亮状态的部分 3 :out-of-range :out-of-range 匹配值在指定区间之外的input元素 3 :in-range :in-range 匹配值在指定区间之内的input元素 3 :read-write :read-write 用于匹配可读及可写的元素 3 :read-only :read-only 用于匹配设置 “readonly”(只读) 属性的元素 3 :optional :optional 用于匹配可选的输入元素 3 :required :required 用于匹配设置了 “required” 属性的元素 3 :valid :valid 用于匹配输入值为合法的元素 3 :invalid :invalid 用于匹配输入值为非法的元素
四、PhantomJS & Selenium
PhantomJS: 了解详情
官网:http://phantomjs.org/download.html (支持Windows/Linux/Mac OS)
Selenium
官网:http://selenium-python.readthedocs.io/index.html
官网下载安装或者:
执行命令:pip install selenium
前提1:安装chrome浏览器,注意更新版本
前提2:下载Chromedrive,放在chrome.exe目录下,并配置环境变量
示例1:from selenium import webdriver url = 'https://www.baidu.com' driver = webdriver.Chrome() driver.maximize_window() driver.get(url)示例2:
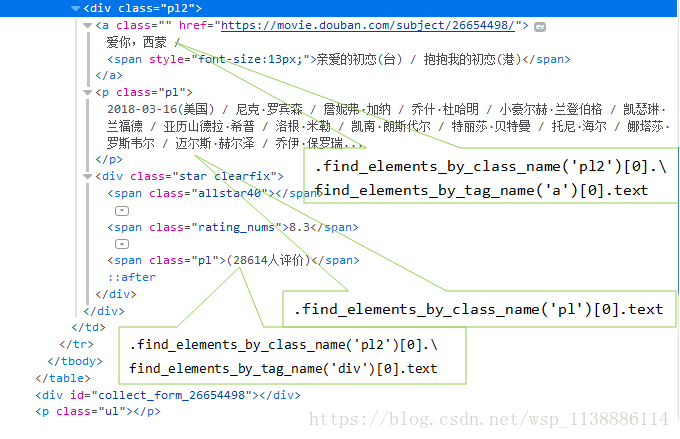
from selenium import webdriver url = 'https://movie.douban.com/chart' driver = webdriver.Chrome() driver.get(url) tables = driver.find_elements_by_tag_name('table') tables.pop(0) for i,v in enumerate(tables): film_name = v.find_elements_by_class_name('pl2')[0].\ find_elements_by_tag_name('a')[0].text actor = v.find_elements_by_class_name('pl')[0].text comment = v.find_elements_by_class_name('pl2')[0]. \ find_elements_by_tag_name('div')[0].text print(film_name) print('-----------------1--------------------') print(actor) print('-----------------2-------------------') print(comment)