Python版本:python3.+
运行环境:Mac OS
IDE:pycharm
一 、前言
最近也是才自学的scrapy,所以也算是才入门,这篇博客也是为了记录自己所学所思,如有错误,望指正。
二 、初识Scrapy
1、 什么是Scrapy
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
简单地说,Scrapy是一个爬虫框架,它能爬取网站的数据。
2、 我能用Scrapy干什么
先来说说普通的网络爬虫,比如使用requests进行获取网上的信息,比如:小说、图片、视频、商品价格、股市信息… 而Scrapy,能让这个获取信息的行为更加高效
3、 Scrapy是怎么干活的
先来看一下Scrapy的架构:
下图是官方给的图
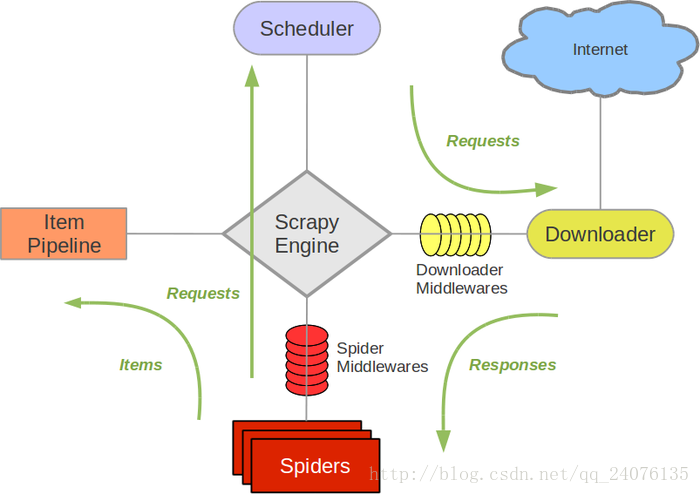
其中包括的组件有
1. Scrapy Engin
这是Scrapy框架的核心,类似于电脑的cpu,所有的数据流都是在Scrapy Engin 的分配下被发送到正确的组件
2. 调度器(Scheduler)
调度器是从引擎接受requests并将他们入队,以便之后引擎请求他们时提供给引擎。类似于cache,将requests请求以队列的形式暂时存储在调度器中。
3. 下载器(Downloader)
下载器负责获取页面数据并提供给引擎,而后提供给spider。 下载器会从Internet获取请求的url的页面数据并以response的形式返回给Spider。
4. Spiders
Spiders是用于分析response,把需要的数据、url提取出来。其中,数据能保存在item中。如果想继续访问获取的url,则可以将该url,以requests请求的方式发送到scheduler中,以等待执行。
5. Item Pipeline
Item Pipeline负责处理被spider提取出来的item。典型的处理有清理、 验证及持久化(例如存取到数据库中)。
========以下模块先有个印象即可==========
6. 下载器中间件(Downloader Middlewares)
下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
7. Spider中间件(Spider Middlewares)
Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
刚开始看到这些组件的概念,对Scrapy的运行流程还是似懂非懂,但是从数据流的角度再进行分析,对Scrapy就能有一个大致的印象了。
数据流(Data flow)
Scrapy中的数据流由执行引擎控制,其过程如下:
- 引擎刚启动时,会调用
start_requests这个Spider方法,向该方法发送的url是从start_urls列表中获取的。 该方法只会在引擎刚启动时执行,start_urls列表则是需要自己设定的。 - 引擎从
Spider中获取到第一个要爬取的URL并在调度器(Scheduler)以requests调度。 - 引擎向调度器请求下一个要爬取的
URL。 - 调度器返回下一个要爬取的
URL给引擎,引擎将URL通过下载中间件(请求(requests)方向)转发给下载器(Downloader)。 - 一旦页面下载完毕,下载器生成一个该页面的
Response,并将其通过下载中间件(返回(response)方向)发送给引擎。 - 引擎从
下载器中接收到Response并通过Spider中间件(输入方向)发送给Spider处理。 Spider处理Response并返回爬取到的Item及(跟进的)新的requests给引擎。- 引擎将(Spider返回的)爬取到的
Item给Item Pipeline,将(Spider返回的)requests给调度器。 - (从第二步)重复直到调度器中没有更多地
requests,引擎关闭该网站。
官方文档链接:
http://scrapy-chs.readthedocs.io/zh_CN/1.0/topics/architecture.html
三 、Scrapy的安装
安装前提: 已成功安装python3
安装方法 :
- Mac OS:
在终端键入命令pip3 install scrapy - Windows:
见博客 Python3网络爬虫(五):Python3安装Scrapy
四 、小结
用Scrapy写出一个高效的多进程爬虫是很方便的,百行代码不到,就能写出一个入门的scrapy的爬虫。而且scrapy有很高的自由度,自己能重构其中间件(middleware)步骤。
随笔
可能是我学习方法的问题,每次学新的知识,光看官方文档总是看的云里雾里,不得要领;看别的博主写的博客,常常会步骤写着写,然后中间就会跳个一两步,我当时看了很久,脑子的想法就是 ? ? ?。我希望能通过把学的知识写下来,能重构我的学习模式和学习能力 =w= 。