1.Introduction
1.1 Example
1.2 What is machine learning?
对机器学习的两种定义
1. Arthur Samuel (1959). Machine Learning: Field of study that gives computers the ability to learn without being explicitly programed.
2. Tom Mitchell(1998) Well-posed Learning Problem: A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E.(定义理解以spam为例:T表示对邮件进行分类,判断是否为垃圾邮件,E表示对邮件进行分类的结果,P表示对邮件分类的正确率。定义的意思是通过E,使得T更好,P就是这个指标,P增加)
1.3 Supervised Learning
1.3.1 Regression
Predict continuous valued output (price).预测一个连续值作为输出。比如知道房屋的面积,预测房价。
1.3.2 Classification
Discrete valued output(eg:0 or 1). 比如Breast cancer(malignant, benign)
1.4 Unsupervised Learning
给出一组数据,不给出相关数据的正确答案。找出这些数据内部存在的结构。无监督学习最为常见例子是聚类。根据事物间的相似度将它们归为一类。
2 Linear Regression with One Variable
2.1 Model and Cost Function
2.1.1 Model Representation
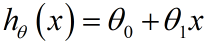 (2-1)
(2-1)
将要用到的符号说明:
x 表示输入(特征)
y 表示输出 (目标值)
m 表示训练集的样本数量
(x,y) 表示全部训练集数据
(x(i),y(i)) 表示训练集中第i个数据
h 表示假设函数,输入和输出之间的一种关系
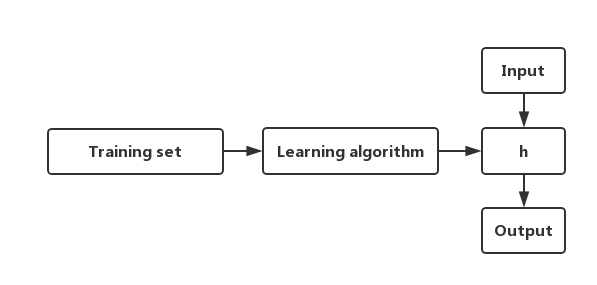
图 2.1 线性回归过程
学习算法利用训练集数据,拟合出假设函数h,输入经过假设函数拟合出输出。
2.1.2 Cost Function
代价函数是为了找到目的函数的最优解。因为在一个训练集中,有无数个模型,我们需要找到最拟合的这个训练集的函数,所以引入代价函数,用来找到那个最好的模型。常用的平方误差代价函数(或者是均方误差函数)如下式,其中1/2是为了求梯度下降方便,对代价函数求导会消掉1/2. 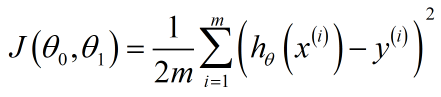 (2-2)
(2-2)
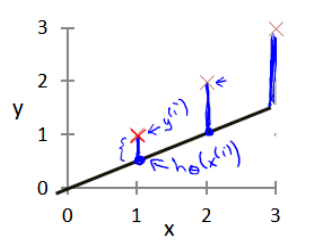
图2.2 建模误差
对于参数的选取,决定了模型的预测值与训练集中实际值的差距。(蓝线就是modeling error)。

图 2.3 代价函数图像
最优解即为代价函数的最小值,如图2.3所示,当θ1=1时,该代价函数有最小值,即最优解。