目录
一、正交化
单独调整,调整的参数不要互相影响在不同数据集上的表现

二、单一数字评估指标
建议:将问题设置为一个单实数评估指标(F1 score:P和R的调和平均)
查准率(Precision)和查全率(Recall)和 P-R曲线、ROC曲线
机器学习之查准率、查全率与P-R曲线,ROC曲线与AUC指标
数据发生倾斜时,准确率判断模型好坏就不那么准确了。比如风控模型中,99个正常用户和1个欺诈用户,用一个把所有用户都识别成正常用户的模型进行预测,那么该模型的准确率为99%,然而并没有什么用。所以要用另一个参数来衡量模型的好坏。


三、满足和优化指标

满足指标:必须需要达到的指标
优化指标:数据越好那么就越好
四、(设立 -- > 改变)训练集/开发集/测试集
训练集 和 开发集需要是 同一分布!

比例分配之前讲过

改变调整开发集和测试集

五、人的表现和改善模型



- 如果机器项目已经和人类水平相当,那么接下来的提升将很缓慢,这是很好理解的,越接近贝叶斯最有误差,就难以更进一步。
- 为了接近人类水平,往往可以通过人类指导的方式对模型进行修正,例如找出错误分类样本,通过人类分析除可能的原因以指导改进方向。
- 如果你的机器学习项目和人类水平相当,那么基本没有必要收集更多的数据以期望能够更进一步地提升模型水平。从上面的论述中有讲到到:贝叶斯最优估计体现了数据的极限,再收集更多的数据也不可能超过这个水平了。

贝叶斯误差就是最优的哪一个!!!就代表人类水平(hunman-level)


六、进行误差分析
上限分析,进行针对性处理 (处理的优先级!!!)

七、清除标注错误的数据


如果影响严重就需要去人工修正


八、快速搭建第一个系统并进行迭代
如果是已经比较成熟的技术的话,可以从一个比较复杂的项目上手
但是如果是一个新的问题,建议从一个简单的系统快速上手(快而不精)、误差分析,然后确定下一步的方向





九、在不同的分布上训练和测试

对于上面有一些问题:

- 算法只见过训练集的数据,没见过开发集数据
- 开发集数据来自不同的分布
这9%的误差到底是有多少是因为算法没有看过开发集里面的数据导致的呢?还是本身方差呢?
解决方案:设置 training-dev训练验证集
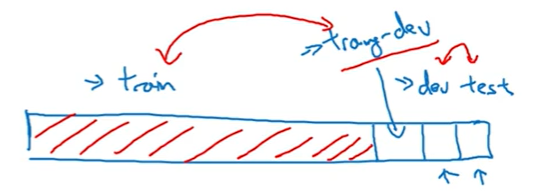



以后在做项目的时候,也需要这样考虑
十、数据不匹配问题(收集更多的数据)

人工合成技术

但是如果数据集过于相似,可能会存在过拟合的问题
十一、迁移学习
适用于:如果你迁移的目标没有很多的数据
如果重新训练神经网络中的所有参数,那这个在图象识别数据的初期训练阶段,有时候称为预训练(pre-training)
如果更新所有的权重,然后用别的数据上进行训练,称为微调(fine tuning)
等于预训练先快速部署一个模型(已经训练过的), 微调就是在这个基础上做一些修改, 用新数据去训练改的这几层 达到快速应用的目的 ,不用再重头训练一个新模型



![]()
十二、多任务学习



十三、端到端学习
忽略所有的阶段,直接用神经网络,从输入到输出


但是还是遇到很多食物,还是无法做到端到端的,一个是能力不足,另一个是多阶段的做法更加有优势
什么时候用端到端?
需要很大的数据,有足够的数据能够做到直接学到从x映射到y的复杂的函数
作业









