训练/开发/测试集划分 (Train/Dev/Test Distribution)
设立训练集,开发集和测试集的方式大大影响了你或者你的团队在建立机器学习应用方面取得进展的速度。同样的团队,即使是大公司里的团队,在设立这些数据集的方式,真的会让团队的进展变慢而不是加快,我们看看应该如何设立这些数据集,让你的团队效率最大化。

在这个视频中,我想集中讨论如何设立开发集和测试集,开发(dev)集也叫做开发集(development set),有时称为保留交叉验证集(hold out cross validation set)。然后,机器学习中的工作流程是,你尝试很多思路,用训练集训练不同的模型,然后使用开发集来评估不同的思路,然后选择一个,然后不断迭代去改善开发集的性能,直到最后你可以得到一个令你满意的成本,然后你再用测试集去评估。
现在,举个例子,你要开发一个猫分类器,然后你在这些区域里运营,美国、英国、其他欧洲国家,南美洲、印度、中国,其他亚洲国家和澳大利亚,那么你应该如何设立开发集和测试集呢?
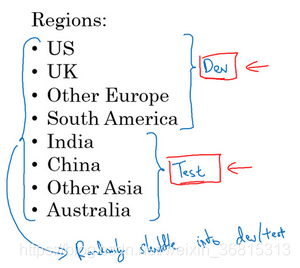
其中一种做法是,你可以选择其中4个区域,我打算使用这四个(前四个),但也可以是随机选的区域,然后说,来自这四个区域的数据构成开发集。然后其他四个区域,我打算用这四个(后四个),也可以随机选择4个,这些数据构成测试集。
事实证明,这个想法非常糟糕,因为这个例子中,你的开发集和测试集来自不同的分布。我建议你们不要这样,而是让你的开发集和测试集来自同一分布。我的意思是这样,你们要记住,我想就是设立你的开发集加上一个单实数评估指标,这就是像是定下目标,然后告诉你的团队,那就是你要瞄准的靶心,因为你一旦建立了这样的开发集和指标,团队就可以快速迭代,尝试不同的想法,跑实验,可以很快地使用开发集和指标去评估不同分类器,然后尝试选出最好的那个。所以,机器学习团队一般都很擅长使用不同方法去逼近目标,然后不断迭代,不断逼近靶心。所以,针对开发集上的指标优化。
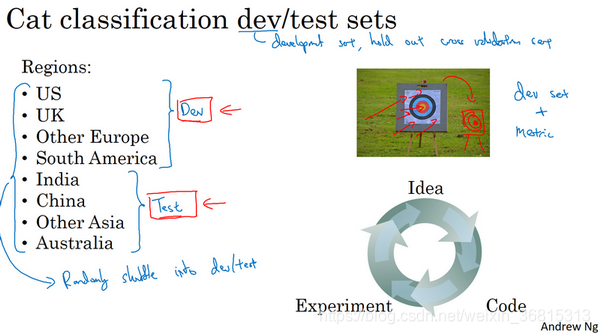
然后在左边的例子中,设立开发集和测试集时存在一个问题,你的团队可能会花上几个月时间在开发集上迭代优化,结果发现,当你们最终在测试集上测试系统时,来自这四个国家或者说下面这四个地区的数据(即测试集数据)和开发集里的数据可能差异很大,所以你可能会收获"意外惊喜",并发现,花了那么多个月的时间去针对开发集优化,在测试集上的表现却不佳。所以,如果你的开发集和测试集来自不同的分布,就像你设了一个目标,让你的团队花几个月尝试逼近靶心,结果在几个月工作之后发现,你说“等等”,测试的时候,“我要把目标移到这里”,然后团队可能会说"好吧,为什么你让我们花那么多个月的时间去逼近那个靶心,然后突然间你可以把靶心移到不同的位置?"。
所以,为了避免这种情况,我建议的是你将所有数据随机洗牌,放入开发集和测试集,所以开发集和测试集都有来自八个地区的数据,并且开发集和测试集都来自同一分布,这分布就是你的所有数据混在一起。
这里有另一个例子,这是个真实的故事,但有一些细节变了。所以我知道有一个机器学习团队,花了好几个月在开发集上优化,开发集里面有中等收入邮政编码的贷款审批数据。那么具体的机器学习问题是,输入 为贷款申请,你是否可以预测输出 , 是他们有没有还贷能力?所以这系统能帮助银行判断是否批准贷款。所以开发集来自贷款申请,这些贷款申请来自中等收入邮政编码,zip code就是美国的邮政编码。但是在这上面训练了几个月之后,团队突然决定要在,低收入邮政编码数据上测试一下。当然了,这个分布数据里面中等收入和低收入邮政编码数据是很不一样的,而且他们花了大量时间针对前面那组数据优化分类器,导致系统在后面那组数据中效果很差。所以这个特定团队实际上浪费了3个月的时间,不得不退回去重新做很多工作。
课程PPT




