开发集和测试集的大小 (Size of Dev and Test Sets)
在上一个视频中你们知道了你的开发集和测试集为什么必须来自同一分布,但它们规模应该多大?在深度学习时代,设立开发集和测试集的方针也在变化,我们来看看一些最佳做法。
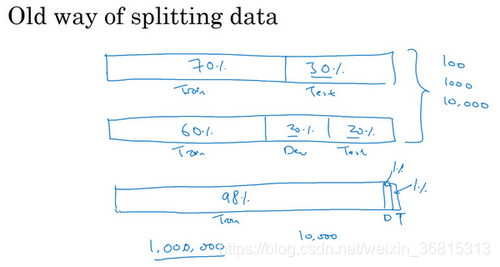
你可能听说过一条经验法则,在机器学习中,把你取得的全部数据用70/30比例分成训练集和测试集。或者如果你必须设立训练集、开发集和测试集,你会这么分60%训练集,20%开发集,20%测试集。在机器学习的早期,这样分是相当合理的,特别是以前的数据集大小要小得多。所以如果你总共有100个样本,这样70/30或者60/20/20分的经验法则是相当合理的。如果你有几千个样本或者有一万个样本,这些做法也还是合理的。
但在现代机器学习中,我们更习惯操作规模大得多的数据集,比如说你有1百万个训练样本,这样分可能更合理,98%作为训练集,1%开发集,1%测试集,我们用 和 缩写来表示开发集和测试集。因为如果你有1百万个样本,那么1%就是10,000个样本,这对于开发集和测试集来说可能已经够了。所以在现代深度学习时代,有时我们拥有大得多的数据集,所以使用小于20%的比例或者小于30%比例的数据作为开发集和测试集也是合理的。而且因为深度学习算法对数据的胃口很大,我们可以看到那些有海量数据集的问题,有更高比例的数据划分到训练集里,那么测试集呢?
要记住,测试集的目的是完成系统开发之后,测试集可以帮你评估投产系统的性能。方针就是,令你的测试集足够大,能够以高置信度评估系统整体性能。所以除非你需要对最终投产系统有一个很精确的指标,一般来说测试集不需要上百万个例子。对于你的应用程序,也许你想,有10,000个例子就能给你足够的置信度来给出性能指标了,也许100,000个之类的可能就够了,这数目可能远远小于比如说整体数据集的30%,取决于你有多少数据。
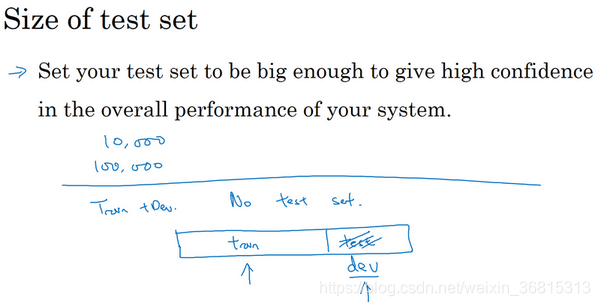
对于某些应用,你也许不需要对系统性能有置信度很高的评估,也许你只需要训练集和开发集。我认为,不单独分出一个测试集也是可以的。事实上,有时在实践中有些人会只分成训练集和测试集,他们实际上在测试集上迭代,所以这里没有测试集,他们有的是训练集和开发集,但没有测试集。如果你真的在调试这个集,这个开发集或这个测试集,这最好称为开发集。
不过在机器学习的历史里,不是每个人都把术语定义分得很清的,有时人们说的开发集,其实应该看作测试集。但如果你只要有数据去训练,有数据去调试就够了。你打算不管测试集,直接部署最终系统,所以不用太担心它的实际表现,我觉得这也是很好的,就将它们称为训练集、开发集就好。然后说清楚你没有测试集,这是不是有点不正常?我绝对不建议在搭建系统时省略测试集,因为有个单独的测试集比较令我安心。因为你可以使用这组不带偏差的数据来测量系统的性能。但如果你的开发集非常大,这样你就不会对开发集过拟合得太厉害,这种情况,只有训练集和测试集也不是完全不合理的。不过我一般不建议这么做。
总结一下,在大数据时代旧的经验规则,这个70/30不再适用了。现在流行的是把大量数据分到训练集,然后少量数据分到开发集和测试集,特别是当你有一个非常大的数据集时。以前的经验法则其实是为了确保开发集足够大,能够达到它的目的,就是帮你评估不同的想法,然后选出 还是 更好。测试集的目的是评估你最终的成本偏差,你只需要设立足够大的测试集,可以用来这么评估就行了,可能只需要远远小于总体数据量的30%。
所以我希望本视频能给你们一点指导和建议,让你们知道如何在深度学习时代设立开发和测试集。接下来,有时候在研究机器学习的问题途中,你可能需要更改评估指标,或者改动你的开发集和测试集,我们会讲什么时候需要这样做。
课程板书



