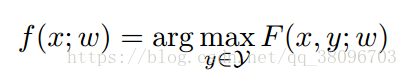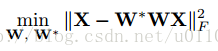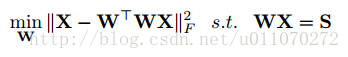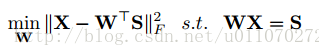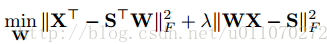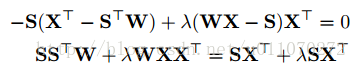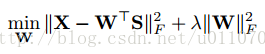Zero-Shot learning
在传统的分类模型中,为了解决多分类问题(例如三个类别:猫、狗和猪),就需要提供大量的猫、狗和猪的图片用以模型训练,然后给定一张新的图片,就能判定属于猫、狗或猪的其中哪一类。但是对于之前训练图片未出现的类别(例如牛),这个模型便无法将牛识别出来,而ZSL就是为了解决这种问题。在ZSL中,某一类别在训练样本中未出现,但是我们知道这个类别的特征,然后通过语料知识库,便可以将这个类别识别出来。因此,在 ZSL 任务中,在训练集中见过的类别和测试集中没见过的类别是不相交的。
通常而言,见过和没见过的类别都要提供类别描述信息(比如用户定义的属性标注、类别的文本描述、类别名的词向量等);某些描述信息是各个类别共有的。这些描述信息通常被称为辅助信息或语义表征。
Zero-Shot learning的典型模型
1、直接属性预测模型(DAP)和间接属性预测模型(IAP)。
《Learning To Detect Unseen Object Classes by Between-Class Attribute Transfer》
DAP可以理解为一个三层模型:第一层是原始输入层,例如一张电子图片(可以用像素的方式进行描述);第二层是p维特征空间,每一维代表一个特征(例如是否有尾巴、是否有毛等等);第三层是输出层,输出模型对输出样本的类别判断。在第一层和第二层中间,训练p个分类器,用于对一张图片判断是否符合p维特征空间各个维度所对应的特征;在第二层和第三层间,有一个语料知识库,用于保存p维特征空间和输出y的对应关系
简单来讲,就是对输入的每一个属性训练一个分类器,然后将训练得出的模型用于属性的预测,测试时,对测试样本的属性进行预测,再从属性向量空间里面找到和测试样本最接近的类别。
缺点:
- 算法引入了中间层,核心在于尽可能得判定好每幅图像所对应的特征,而不是直接去预测出类别;因此DAP模型在判定属性时可能会做得很好,但是在预测类别时却不一定;
- 无法利用新的样本逐步改善分类器的功能;
- 无法利用额外的属性信息(如Wordnet等)
2、ALE模型
《Label-Embedding for Attribute-Based Classification》
在分类问题中,每个类别被映射到属性空间中,即每个类别可用一个属性向量来表示(例如:熊猫—>(黑眼圈,爱吃竹子,猫科动物......))。ALE模型即学习一个函数F,该函数用于衡量每一幅图像和每个属性向量之间的匹配度. ALE模型确保对于每幅图像,和分类正确的类别的相容性比和其他类别的匹配度高。
定义f(x; w)为预测函数,定义F(x, y; w)为输入x和类别y之间的匹配度。则当给定一个需要预测类别的数据x时,预测函数f所做的便是从所有类别y中,找到一个类别y使得F(x, y; w)的值最大。
在属性空间Attribute Feature space上来学习映射矩阵W实现分类,样本x的映射特征
标签y的映射特征为
标签进行特征映射y^=ϕ(x)
简言之,即使用图像样本的特征与图像类别标签的属性向量来训练得到W。
借鉴WSABIE算法,计算对应每个类别的得分,从其他所有不是正确类的得分中找出最大得分,逐样本累加得到损失函数,使用SGD训练更新参数。
3、SAE模型
《Semantic Autoencoder for Zero-Shot learning》
代码:https://github.com/Elyorcv/SAE
主要是关于利用语义自编码器实现zero-shot learning的工作。一定程度上解决了训练集和测试集的领域漂移(domain shift)问题。整个算法最核心的地方是在自编码器进行编码和解码时,使用了原始数据作为约束,即编码后的数据能够尽可能恢复为原来的数据。该方法在6个数据集上的zero-shot learning结果都为目前最好。该方法还能解决监督聚类问题(supervised clustering problem),并也能取得目前最好的效果。
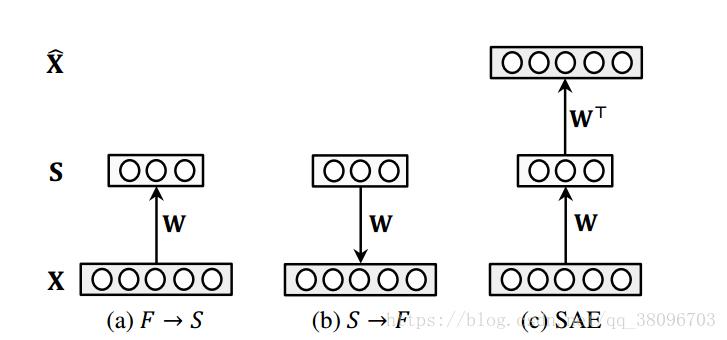
作者使用了一个十分基础的自编码器对原始样本进行编码,其结构如图1所示,其中X为样本,S为自编码器的隐层,x^为由隐层还原为样本的表示。需要注意的是隐藏层S层为属性层,它不仅仅是原样本的另一种表示,它同时也有着清晰的语义。
贡献
(1)提出了一种新的用于zero-shot learning语义自编码模型;(2)提出了模型对应的高效的学习算法;(3)算法具有扩展性,可以用于监督聚类问题(supervised clustering问题)。实验证明,该算法在多个数据集上能取得最好效果。映射领域漂移(Projection domain shift)
对于zero-shot learning问题,由于训练模型时,对于测试数据类别是不可见的,因此,当训练集和测试集的类别相差很大的时候,比如一个里面全是动物,另一个全是家具,在这种情况下,传统zero-shot learning的效果将受到很大的影响。算法内容
语义自编码器
上文已经提到了作者所使用的自编码器,它只有一层隐层,且隐层的维数要小于输入层的维度。设输入层到隐层的映射为W,隐层到输出层的映射为W*,W和W*是对称的,即有W*等于W的转置。由于我们希望输入和输出尽可能相似,则可设目标函数为:
传统的自编码器是非监督学习的,但在此问题中,我们希望中间层能够有语义的含义,能表示类标或者表示样本属性。即,加入约束WX=S,其中S是X对应的事先定义好的语义向量,换句话说,每个样本x都可以表示为一个向量s,这个s是事先定义好的。当加入这样一个约束之后,就可以使得原本非监督学习的自编码器变为监督学习的自编码器,使得自编码器的中间层表示在合理的空间内。此时目标函数可以表示为:
目标函数最优化求解
原目标函数可以表示为:
目标函数中,有WX=S,直接使用这样的约束太强了,可以想象,需要自编码器的中间层完全等于事先定义好的值,这样的条件实在是太苛刻了。因此,可以将原式写成:
这样同时将约束写入了目标函数中,也不需要拉格朗日法进行求解了,只需要简单的步骤就可以进行求解。我们注意到上式是个标准二次型(standard quadratic formulation)的形式,利用矩阵迹的运算进行改写(Tr(X)=Tr(X转置),Tr(W转置乘S)=Tr(S转置W))
直接求导,让导等于0,可得:
这个式子可以写成Sylvester equation的形式,可以使用Bartels-Stewart算法[1]进行求解。在matlab中有现成的函数,代码如图2所示。最终就可以求得映射函数W。
图2 matlab代码
Zero-shot learning
有了求映射矩阵W的方法,即可以将样本映射到对应的属性空间中,即可预测测试样本的类别。如果读者很清楚zero-shot learning的概念和基本方法的话,就应该很容易理解了,为了照顾新手,这里还是说一些具体实现。在实现zero-shot learning时,我们先将数据集分为训练集和测试集,且两个数据集的数据类别之间是没有交集的。利用一些先验知识得到每种类别的属性向量表示,通过上文的方法,利用训练集训练出映射矩阵W,这样就可以对测试集中的样本进行类别的预测。在此工作中,需要检验两个方面,一个是中间层的准确度,第二是输出层的准确度。只需要利用映射矩阵W得到测试样本的中间层表示和输出表示,与ground truth进行比较,就可以了。
如果我们抛开自编码器的结构,将问题考虑为普通的学习映射矩阵的问题,即:输入为X,属性层为S,希望学习一个映射W,使得S=WX。一般的想法就是构建如下目标函数,并且加入L2-norm作为约束。
在论文[2]中,希望能够使得属性层S能够映射回样本X,则有
可以看出,本文算法的目标函数是上述两种方法的结合,只是去除了L2-norm项。因为本文算法中隐式包含了这个约束,能够控制它的值处于一个较为合理的范围。
监督聚类(supervised clustering)
简单来说就是通过训练集训练出映射W,利用W将测试集的样本表示为属性层的表示形式,注意这里的属性层是二值化的,并且将其表示为one-hot的形式,这样就可以用属性层来表示类别了。之后再进行kmeans聚类,得到测试集合的聚类结果。
4、LDF模型
Discriminative Learning of Latent Features for Zero-Shot Recognition
通常而言,见过和没见过的类别都要提供类别描述信息(比如用户定义的属性标注、类别的文本描述、类别名的词向量等);某些描述信息是各个类别共有的。这些描述信息通常被称为辅助信息或语义表征。在本研究中,我们关注的是使用属性的 ZSL 的学习。
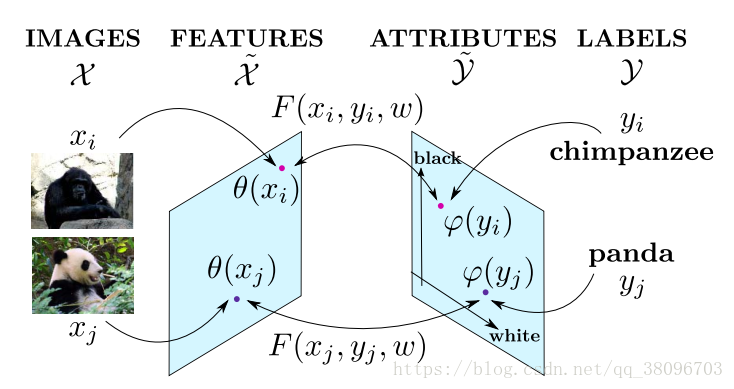
如图 1 所示,典型 ZSL 方法的一个通用假设是:存在一个共有的嵌入空间,其中有一个映射函数

,定义这个函数的目的是对于见过或没见过的类别,衡量图像特征 φ(x) 和语义表征 ψ(y) 之间的相容性(compatibility)。W 是所要学习的视觉-语义映射矩阵。现有的 ZSL 方法主要侧重于引入线性或非线性的建模方法,使用各种目标和设计不同的特定正则化项来学习该视觉-语义映射,更具体而言就是为 ZSL 学习 W。

图 1:经典 ZSL 方法的目标是寻找一个嵌入了图像特征 φ(x) 和语义表征 ψ(y) 的嵌入空间
到目前为止,映射矩阵 W 的学习(尽管对 ZSL 很重要)的主要推动力是视觉空间和语义空间之间对齐损失的最小化。但是,ZSL 的最终目标是分类未见过的类别。因此,视觉特征 φ(x) 和语义表征 ψ(y) 应该可以被区分开以识别不同的目标。不幸的是,这个问题在 ZSL 领域一直都被忽视了,几乎所有方法都遵循着同一范式:1)通过人工设计或使用预训练的 CNN 模型来提取图像特征;2)使用人类设计的属性作为语义表征。这种范式存在一些缺陷。
第一,图像特征 φ(x) 要么是人工设计的,要么就是来自预训练的 CNN 模型,所以对零样本识别任务而言可能不具有足够的表征能力。尽管来自预训练 CNN 模型的特征是学习到的,然而却受限于一个固定的图像集(比如 ImageNet),这对于特定 ZSL 任务而言并不是最优的。
第二,用户定义的属性 ψ(y) 是语义描述型的,但却并不详尽,因此限制了其在分类上的鉴别作用。也许在 ZSL 数据集中存在一些预定义属性没有反映出来的鉴别性的视觉线索,比如河马的大嘴巴。另一方面,如图 1 所示,「大」、「强壮」和「大地」等被标注的属性是很多目标类别都共有的。这是不同类别之间的知识迁移所需的,尤其是从见过的类别迁移到没见过的类别时。但是,如果两个类别(比如豹和虎)之间共有的(用户定义的)属性太多,它们在属性向量空间中将难以区分。
第三,现有 ZSL 方法中的低层面特征提取和嵌入空间构建是分开处理的,并且通常是独立进行的。因此,现有研究中很少在统一框架中考虑这两个组分。
为了解决这些缺陷,我们提出了一种端到端的模型,可以同时在视觉空间和语义空间中学习用于 ZSL 的隐含的鉴别性特征(LDF)。具体而言,我们的贡献包括:
一种级联式缩放机制,可用于学习以目标为中心的区域的特征。我们的模型可以自动识别图像中最具鉴别性的区域,然后在一个级联式的网络结构中将其放大以便学习。通过这种方式,我们的模型可以专注于从以目标为焦点的区域中学习特征。一种用于联合学习隐含属性和用户定义的属性的框架。我们将隐含属性的学习问题形式化为了一个类别排序问题,以确保所学习到的属性是鉴别性的。同时,在我们模型中,鉴别性区域的发掘和隐含属性的建模是联合学习的,这两者会互相协助以实现进一步的提升。一种用于 ZSL 的端到端网络结构。所获得的图像特征可以调整得与语义空间更加兼容,该空间中既包含用户定义的属性,也包含隐含的鉴别性属性。
我们的方法
我们提出的方法的框架如图 2 所示。注意,原则上该框架包含多个图像尺度,但为描述清楚,这里仅给出了有 2 个图像尺度的情况作为示例。在每个图像尺度中,网络都由三个不同组分构成:1)图像特征网络(FNet),用于提取图像表征;2)缩放网络(ZNet),用于定位最具鉴别性的区域,然后将其放大;3)嵌入网络(ENet),用于构建视觉信息和语义信息关联在一起的嵌入空间。对于第一个尺度,FNet 的输入是原始尺寸的图像,ZNet 负责生成放大后的区域。然后到第二个尺度,放大后的图像区域成为 FNet 的输入,以获得更具鉴别性的图像特征。

图 2:我们提出的隐含鉴别性特征(LDF)学习模型的框架。从粗略到精细到图像表征被同时投射到用户定义的属性和隐含属性中。用户定义的属性通常是不同类别共有的,而隐含属性是为区分而通过调整类别间或类别中的距离而学习到的。
实验
我们提出的 LDF 模型在两个有代表性的 ZSL 基准上进行了评估,即:Animals with Attributes(AwA)和 Caltech-UCSD Birds 200-2011(CUB)。

表 1:使用 VGG19 和 GoogLeNet(括号中的数字)的深度特征在两个数据集上的 ZSL 结果(MCA,%)

表 2:在每个图像尺度上的详细 ZSL 结果(%)

表 3:只使用 UA 特征或 LA 特征所得到的 ZSL 结果(%)

表 4:对于 ZNet 和 ENet,联合训练和分开训练之间的结果比较
Zero-Shot Learing问题数据集分享
AwA: http://pan.baidu.com/s/1nvPzsXb
CUB: http://pan.baidu.com/s/1nv3KCYH
aPaY: http://pan.baidu.com/s/1hseSzVe
SUN: http://pan.baidu.com/s/1gfAc33X
ImageNet2: http://pan.baidu.com/s/1pLfZYQ3
参考博客:https://blog.csdn.net/m0_37167788/article/details/79102918
https://blog.csdn.net/u011070272/article/details/73498526