what is zero-shot learning
zero-shot learning 是为了能够识别在测试中出现,而在训练中未遇到过的数据类别。例如识别一张猫的图片,但在训练时没有训练到猫的图片和对应猫的标签。那么我们可以通过比较这张猫的图片和我们训练过程中的那些图片相近,进而找到这些相近图片的标签,再通过这些相近标签去找到猫的标签。(个人认为zero-shot learning应该属于迁移学习的一种。)
论文一 《DeViSE: A Deep Visual-Semantic Embedding Model》
该论文要解决的问题是如何将已有的图像分类模型应用到训练中未涉及到的图像分类中。例如在模型训练中,只训练了老虎,狗,飞机类别的图像,现需要将模型去识别猫的图像,该如何去做呢?
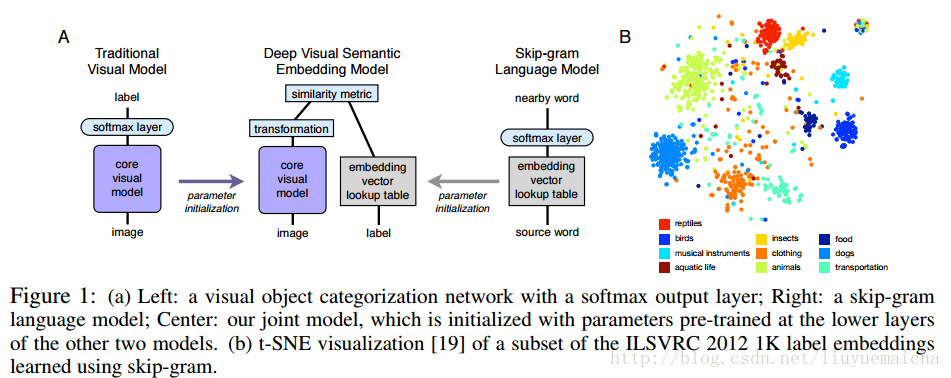
主要思想:该论文将图像的feature vector和NLP的semantic vector结合,进行zero-shot learning,具体看下图:
该结构图是论文的主要特色,author使用word2vec做NLP的vector,将CNN的最后一层softmax 替换为transformation(这里为linear transformation)做图像的feature vector, 这里要保证feature vector 和 label vector(word2vec)的dimension一致,最后做feature vector 和label vector的相似度计算。
论文的特色二是使用了hinge rank loss作为loss得计算,公式如下:
t_label表示label的vector(word2vec计算),v_image表示image的vector(去除softmax layer的cnn计算),M表示linear transformation,margin为超参数。
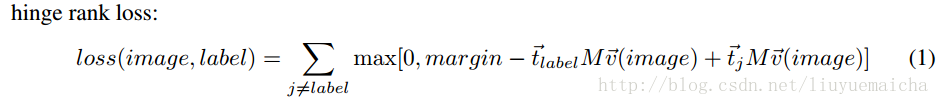
论文二《Zero-Shot Learning by Convex Combination of Semantic Embeddings》
论文二继承了论文一的主要思想(CNN+word2vec),但使用了更简单的方法,从而保留了整个CNN结构,且不需要linear transformation。
公式一:
其中x表示image,y表示image的类别,该公式表示image x在模型P_0(即CNN)下预测类别为y的概率。这里我们可以得到Top N的label y和对应的概率值,作为下面的计算。
公式二: 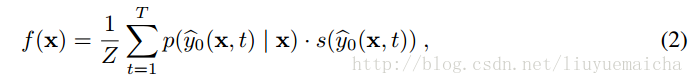
其中T表示Top N,p表示x分类为y的概率,s则为对应y的semantic vector 。Z为正规化因子,公式为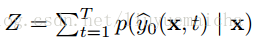
公式三: 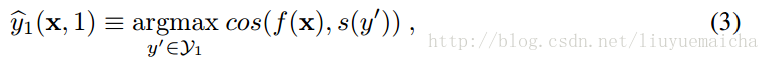
其中f(x)为公式2,s(y’)表示y’的semantic vector,cos表示计算余弦相似度。
该论文的最大亮点是通过标准CNN求得image x最接近的类别权重(概率),并通过 word2vec获得类别vector,进行叠加处理,再和测试类别进行相似度计算,进而预测image x的label。
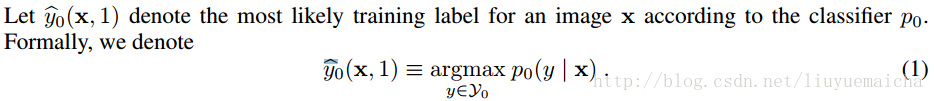
论文三 《Objects2action: Classifying and localizing actions without any video example》
东京时间:0:22:18.77,明天再续……
继续:
已知在Zero-shot learning中训练类集合Y与测试类集合Z是没有交集的,即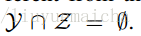
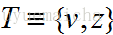
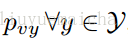
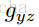
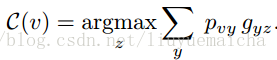
本paper是通过训练图像来对视频分类,所以对于视频测试集,需要将视频抽样取帧(10帧一抽样)。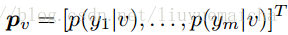
对于semantic embedding的计算,paper试验了两种方案:Average Word Vectors 和 Fisher Word Vectors.实验发现FWV要比AWV效果好。
整体架构:
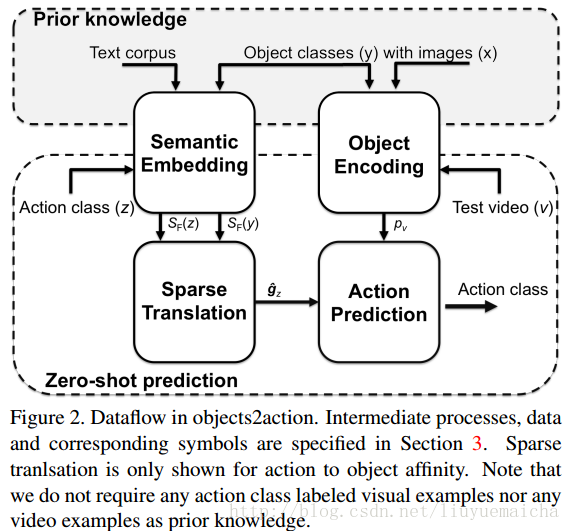
总结:
任何高大上的东西,深谙此道后,都是简洁清晰。初识Zero-shot learning时,本以为是多么的高大上,熟悉后原来是用了现有的理论,完成了一件不可思议的事情。