【文章来源】
事件提取的Zero-Shot迁移学习:https://arxiv.org/pdf/1707.01066.pdf
摘要
大多数先前的事件提取研究严重依赖于从带注释的事件提及中派生的特征,因此不能应用于没有注释工作的新事件类型。在这项工作中,我们重新审视事件提取并将其建模为接地问题。我们设计了一个可转移的神经结构,使用结构和组合神经网络将事件提及和类型联合映射到共享语义空间,其中每个事件提及的类型可以由最接近的所有候选类型确定。通过利用(1)一组现有事件类型和(2)现有事件本体的可用手动注释,我们的框架可以应用于新的事件类型,而不需要额外的注释。现有事件类型(例如,ACE,ERE)和新事件类型(例如,FrameNet)的实验证明了我们的方法的有效性。在没有任何针对23种新事件类型的手动注释的情况下,我们的Zero-Shot框架实现了与从500个事件提及的注释训练的状态监督模型相当的性能。
1 简介
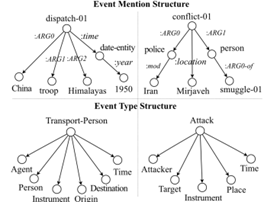
事件提取的目标是从非结构化数据中提取事件触发器和参数。图1中显示了一个示例。在事件提取方面取得进展的主要障碍是传统监督方法的可移植性差以及可用事件注释的覆盖范围有限。处理新的事件类型意味着从头开始,而无法重复使用旧事件类型的注释。主要原因是这些方法将事件提取建模为分类问题,编码特性仅通过测量测试事件提及和注释事件提及编码的丰富特性之间的相似性来实现。在这些模型中,事件类型(例如,Transport-Person)或参数角色(例如,Destination)被简单地视为原子符号(即,Transport-Person)。因此,对3000多种事件类型中的每一种重复高成本注释过程是不可行的。
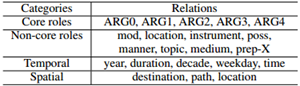
实际上,最近开发了许多丰富的事件本体,包括FrameNet(Baker和Sato,2003),VerbNet(Kipper等,2008),Propbank(Palmer等,2005)和OntoNotes(Pradhan等,2007),其中每个事件类型都与一组预定义的参数角色相关联。我们观察到事件提及和类型都可以用结构表示,其中事件提示结构由触发器和候选参数构成,事件类型结构由事件类型和预定义角色组成。考虑两个例句:
E1. The Government of China has ruled Tibet since 1951 after dispatching troops to the Himalayan region in 1950.
E2. Iranian state television stated that the conflict between the Iranian police and the drug smugglers took place near the town of mirjaveh.

如图1所示,E1包括由调度触发的Transport Person事件提及,E2包括由冲突触发的Attack事件提及。对于每个事件提及,我们应用抽象意义表示(AMR)(Banarescu等人,2013)来识别候选参数并构造事件提示结构。同时,这两种事件类型也可以用来自ERE(实体关系事件)(Song等人,2015)的结构来表示,如图2所示。我们可以看到,除了将触发器与其类型相关联的词汇语义之外,它们的结构也往往相似:一个Transport Person事件通常涉及一个Person而不是一个Artifact作为病人,而一个Attack事件涉及一个人或位置作为攻击者。这种观察类似于“事件结构的语义可以以系统的和可预测的方式被概括和映射到事件提及结构”的理论(Pustejovsky, 1991)。受这一理论的启发,我们重新审视事件提取任务,并将其建模为“基础”问题,方法是将每个提及映射到本体中其语义最接近的事件类型。
这种想法的一种可能的实现是Zero-Shot学习(ZSL),其已经成功地用于视觉对象分类(Frome等人,2013; Norouzi等人,2013; Socher等人,2013a)。将ZSL应用于视觉任务的主要思想是分别在多维向量空间中表示图像和类型标签,然后学习回归模型,从图像语义空间映射到基于注释图像的类型标签语义空间,用于看到标签。该回归模型可以进一步用于预测任何给定图像的看不见的标签。
在本文中,我们将ZSL应用于事件提取。给定事件本体,其中每个事件类型都定义为具有丰富的结构(例如,参数角色),我们将带有注释事件提及的事件类型称为可见类型,而将没有注释的事件类型称为看不见的事件类型。我们的目标是有效地将事件的知识从看到的类型转移到看不见的类型,因此我们可以提取本体中定义的任何类型的事件提及。我们设计了一个可转移的神经结构,通过最小化每个事件提及与其相应类型之间的距离,共同学习并将事件提及和类型的结构表示映射到共享语义空间。对于具有看不见类型的事件提及,它们的结构将使用相同的框架投射到相同的语义空间中,并分配具有最高相似值的类型。这种新观点有两个吸引人的好处,它们也体现了我们的贡献:
- 此映射/排名功能是“通用的”并且与事件类型无关,因此我们可以将资源从现有类型转移到新类型,而无需任何额外的注释工作;
- 许多现有的事件本体涵盖了更广泛的事件类型,这使我们能够将事件提取的范围从几十种类型扩展到数千种类型。
2 方法
2.1 概述
事件提取旨在提取触发器和参数。图3显示了我们触发器类型化方法的整体架构,而参数类型遵循相同的管道。

给定句子s,我们首先根据AMR解析识别候选触发器和参数(Wang et al。,2015b)。一个例子如图1所示。对于每个触发器t,例如dispatch-01,我们使用AMR构建一个结构St,如图3所示。每个结构由一组元组组成,例如<dispatch-01, :ARG0, China>。我们使用矩阵来表示每个AMR关系,用每个元组的两个概念组成其语义,并将所有元组表示提供给CNN以生成事件提取结构表示VSt。
给定目标事件本体,对于每个类型y,例如Transport Person,我们通过合并其预定义角色来构造类型结构Sy,并使用张量来表示任何类型和参数之间的隐式关系。我们用每个元组的张量组成类型和参数角色的语义,例如<Transport Person, Destination>。我们使用相同的CNN生成事件类型结构表示VSy。通过使用VSt和VSy最小化dispatch-01和Transport Person之间的语义距离,我们将事件提及和事件类型的表示联合映射到共享语义空间,其中每个提及最接近其注释类型。
在训练之后,组合功能和CNN可以进一步用于将任何新事件提及(例如,donate-01)投射到语义空间中并找到其最接近的事件类型(例如,Donation)。
2.2 候选触发和争论
鉴定与Huang等人(2016)相似,我们基于AMR解析识别候选触发器和参数(Wang et al., 2015b),并使用相同的词义消歧(WSD)工具(Zhong and Ng,2010)对词义进行消歧,并将每个词义链接到OntoNotes,如图1所示。
给定一个句子,我们认为所有可以映射到OntoNotes的名词和动词概念都被WSD视为候选事件触发器。此外,可以与FrameNet中的动词或名义词汇单位匹配的概念也被视为候选触发器。对于每个候选触发器,其候选参数由AMR关系的子集指定,如表1所示。
2.3 结构构造
如图3所示,对于每个候选触发器t,我们基于其候选参数和AMR解析构造其事件提取结构St。对于目标事件本体的每个类型y,我们通过合并其预定义角色并将类型作为根来构造结构Sy。每个St或Sy由一组元组组成。对于每个事件提示结构,元组由两个AMR概念和一个AMR关系组成,而对于每个事件类型结构,元组由类型名称和参数角色名称组成。在这里,我们提出了两种方法,将关系的语义合并到每个元组的两个单词中。
事件提及结构 在事件提及结构中,对于每个元组。我们使用矩阵来表示每个AMR关系,并将AMR关系λ的语义组合为两个概念
和
:
![]()
其中是字
和
的向量表示。d是每个单词向量的维度大小。 [; ]表示两个向量的串联。
是AMR关系λ的矩阵表示。Vu是元组u的组成表示,其由
和
的两个更新的向量表示
组成,通过结合λ的语义。
事件类型结构 对于每个元组在事件类型结构中的,其中y表示事件类型,r表示参数角色,遵循Socher等人(2013b),我们假设任何类型和参数对之间存在隐式和“通用”关系,并使用单个强大的张量来表示隐式关系:
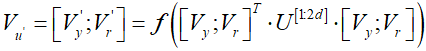
其中Vy和Vr是y和r的向量表示。是3阶张量。
是元组
的组成表示,其由y和r的两个更新的向量表示
,
组成,通过结合它们的隐式关系
的语义。
2.4 联合事件提及和类型标签嵌入
CNN善于捕获各种自然语言处理任务中的句子级别信息。在这项工作中,我们使用它来生成结构级表示。对于每个事件提及结构和每个事件类型结构
,它们分别包含h和p元组,我们应用一个权重共享CNN到每个输入结构,共同学习事件提及和类型结构表示,稍后将用于学习零射击事件提取的排名功能。
输入层是一系列元组,其中元组的顺序在结构中从上到下。每个元组由一个d×2维向量表示,因此每个提及结构和每个类型结构分别表示为维度d×2h *和d×2p *的特征映射,其中h *和p *是元组的最大数量。用于事件提及和类型结构。我们使用右边的零填充来使所有输入结构的体积保持一致。
卷积层带有h *元组的St:作为一个例子。St的输入矩阵是维数d×2h *的特征映射。我们将ci作为特征映射中n个连续列的级联嵌入,其中n是滤波器宽度,0 <i <2h* + n。卷积运算涉及滤波器
,它应用于每个滑动窗口ci:
![]()
其中是新的特征表示,而
是偏置向量。我们将滤波器宽度设置为2并将步长设为2以进行卷积功能,使用两个输入列对每个元组进行操作。
Max-Pooling:所有元组表示用于通过max-pooling生成输入序列的表示。
学习:对于每个事件提及t,我们将正确的类型命名为positive,将目标事件本体中的所有其他类型命名为negative。为了训练组合功能和CNN,我们首先考虑以下铰链排名损失:
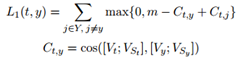
其中y是t的正事件类型。Y是事件本体的类型集。[Vt;VSt]表示t和st的表示的串联。j是来自Y的t的负事件类型。m是边际。Ct,y表示t和y之间的余弦相似度。
铰链损耗通常用于零射击视觉对象分类任务。然而,在我们的实验中,它倾向于过度拟合所见的类型。虽然聪明的数据增加可以帮助缓解过度拟合,但我们提出了两种策略:(1)我们在训练过程中添加“负面”事件提及。这里提到的“负面”事件意味着所提到的类型中没有正面事件类型,即它属于其他类型。(2)我们设计了一个新的损失函数如下:
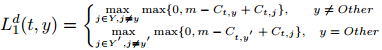
其中Y是事件本体的类型集。 Y'是看到的类型集。y是带注释的类型。y'是在事件提及t的所有事件类型中排名最高的类型,而t属于其他。
通过最小化L1d,我们可以学习优化模型,该模型可以组成结构表示并将事件提及和类型映射到共享语义空间,其中正类型在每个提及中排名最高。
2.5 联合事件论证和角色嵌入
对于每次提及,我们根据参数路径的语义相似性将每个候选参数映射到特定的角色。以E1为例。 基于dispatch-01→ARG0之间的语义相似性,中国与Agent匹配dispatch-01→ARG0→China 且Transport-Person→Agent。给定触发器t和候选参数a,我们首先提取路径,它连接t和a并由p元组组成。每个预定义角色r也通过结合触发类型Sr = hy表示为结构。我们应用相同的框架将Sa和Sr中包含的元组序列转换为权重共享CNN,以对a的所有可能角色进行排名。
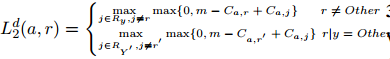
其中和
是为触发器类型y和所有看到的类型y'预定义的参数角色集。r是注释的角色,r'是参数角色,当a或y被注释为Other时,它在a中排名最高。
在我们的实验中,我们分别对不同大小的“负”训练数据进行采样,分别用于触发和参数标记。在3.2节中,我们描述了负面训练实例是如何产生的。采用流水线结构,分别对触发标记和参数标记模型进行训练。
2.6 Zero-Shot分类
在测试过程中,给定一个新的事件提及t',我们计算它的提及结构表示为和所有事件类型结构表示为
,同步使用从可见类型训练的相同参数。我们根据所有事件类型的相似度得分对其进行排序,并提到t'。事件类型集合中t'的最高预测,记为
,由:
![]()
此外表示为t'预测的第k个最可能事件类型。我们将研究基于topk预测事件类型的事件提取性能。
在为提到的t'确定类型y'之后,对于每个候选参数,我们采用相同的排序函数从为y'定义的角色集中找到最合适的角色。
3 实验
3.1 Hyper-Parameters
我们使用一个2014年8月11日的英语维基百科转储来学习基于连续的Skip-gram模型的触发意义和参数嵌入(Mikolov et al., 2013)。表2显示了我们用来训练模型的超参数。

3.1 ACE事件分类
我们首先使用ACE事件模式作为目标事件本体,并假设触发器和参数的边界。在33种ACE事件类型中,我们从ACE05数据中选择前N个最受欢迎的事件类型作为“看见”类型,并使用90%的事件注释用于培训,10%用于开发。N分别设定为1,3,5,10。我们测试了剩余的23种看不见的类型的注释的零射击分类性能。表3显示了我们在每个实验设置中选择进行培训的类型。

从Huang et al.(2016)基于ACE05 training sentence开发的系统输出中抽取属于他人的负面事件提及和论点,基于语义表示将所有候选触发器和论点分组为集群,并为每个集群分配一个类型/角色名称。我们从集群(例如,Build,Threaten)中抽取负面事件提及,这些事件无法映射到ACE事件类型。我们从与这些负面事件提及相关的参数中抽取负面参数。表4显示了训练,开发和测试数据集的统计数据。

为了在我们的方法中显示结构相似性的有效性,我们设计了一个基线,WSD-Embedding,它使用我们预先训练的词义嵌入直接将事件提及和参数提交给候选类型和角色。表5显示结构相似性比触发和参数分类的词汇相似性更有效。此外,随着训练中看到的类型数量的增加,传输模型的性能也会提高。

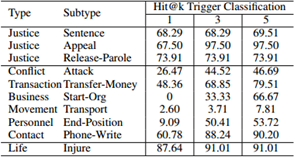
我们进一步评估我们的转移方法在类似和不同看不见的类型上的表现。 ACE中定义的33个子类型属于8种粗粒度主要类型,例如Life,Justice。每个子类型属于一个主类型。属于相同主类型的子类型往往具有相似的结构。例如,Trial-Hearing和Charge-Indict具有相同的参数角色集。为了训练我们的转移模型,我们选择4种正义的子类型:逮捕监狱,定罪,指控,指控,执行。为了测试,我们选择了另外3种正义的子类型:句子,上诉,释放 - 假释。此外,我们还从其他七种主要类型中的每一种中选择一种子类型进行比较。表6显示,在测试新的看不见的类型时,与看到的类型越相似,就可以获得更好的性能。
3.3 ACE事件识别和分类
考虑到ACE05语料库包含迄今为止最丰富的事件提取注释,为了在大量不可见类型上评估我们可转换的神经结构,当我们在有限的注释类型上进行训练时,我们构建了一个新的事件本体,它结合了33种ACE事件类型和参数角色,以及来自FrameNet的1,161帧,除了最通用的帧,如实体,Locale。一些ACE事件类型很容易与帧对齐,例如,Die与Death对齐。相反,有些帧被更准确地视为ACE类型的继承者,例如继承自Attack的Suicide-Attack。我们手动将所选帧映射到ACE类型。我们将我们的方法与以下监督方法进行比较:
- LSTM:基于分布式语义特征的长期短期记忆神经网络(Hochreiter和Schmidhuber,1997),类似于(Feng et al。,2016)。
- 联合:基于符号语义特征的结构化感知器模型(Li et al。,2013)。
对于我们的方法,我们遵循3.2节中的实验设置D,但是针对我们新事件本体中的1191个事件类型。为了评估,我们从剩余的ACE05数据中抽取150个句子,其中包含23种测试类型的129个注释事件提及。对于LSTM和Joint方法,我们使用整个ACE05注释数据进行33种ACE事件类型的训练,除了保留的150个评估句子。
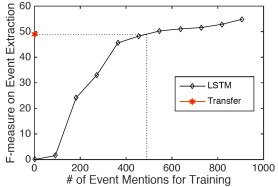
我们根据2.2节中的方法确定候选触发器和参数,并将每个候选触发器和参数映射到目标事件本体。我们评估了分类为23种ACE测试类型的事件。表7显示了性能。为了进一步证明我们框架的零射击学习能力以及保存人类注释工作的重要性,我们使用有监督的LSTM方法进行比较,因为它在ACE事件提取方面取得了最先进的性能(Feng et al。 ,2016)。 LSTM的训练数据包含3,464个句子,其中包括针对23种测试事件类型的905个注释事件提及。我们将这些事件注释分为10倍,并在LSTM的训练数据中相继增加10%。图4显示了学习曲线。在其训练集中没有对23种测试事件类型进行任何注释提及时,我们的转移学习方法实现了与LSTM相当的性能,LSTM通过500个带有500个注释事件提及的句子进行训练。

在分析使用ACE类型注释但错误分类为不正确类型或框架的触发器时,我们发现大多数错误发生在同一场景下定义的类型中。 例如,在下面的句子中“艾比是一个真正的水出生(3公斤—正常),而且在头部加冕之后我被拖出水池”,出生是不是应该出生的事件,我们的方法是生因为出生和分娩都是定义Birth-Scenario和预定义的角色非常相似。对于参数分类,我们的方法在很大程度上依赖于参数路径和参数概念的语义,而许多参数角色(如实体,组织)的信息量不足以与参数概念匹配。
3.4 新类型事件提取
在3.3节中,当我们使用1194个事件类型作为目标本体时,我们进一步评估了我们的方法在非ace类型上的性能。从3.3节的测试结果中,我们随机抽取了200个非ace类型的事件提及,并请语言专家手工评估。对于每个提到,注释器可以看到它的触发器、参数、源句、框架和我们的方法分配的角色,以及FrameNet1框架的定义和示例。注释器通过判断类型和参数角色是否正确来标记真或假。表8显示了性能。

我们的方法可以发现许多在ACE中没有注释的新事件。例如,在“15人死于自杀式炸弹爆炸学生巴士,以色列在加沙回击”这句话中,爆炸被正确地认定为爆炸事件。然而,许多触发器被映射到正确的场景,但是被分配了不正确的类型。例如,在判决中“但安瓦尔的律师表示,他们正在重新申请保释,等待进一步上诉”。,申请被确定为一个触发点,并映射到与保释相关的正确场景,但被错误归类为保释决策事件。我们发现,为了确定事件提及的类型,除了事件提及和类型结构之间的一致语义外,触发器的感觉也应该与事件类型的定义一致。
3.5 AMR的影响
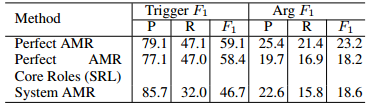
在我们的工作中,我们使用AMR解析输出来构造事件结构。为了评估AMR解析器(Wang et al., 2015a)对事件提取的影响,我们选择了ERE语料库中具有完美AMR注释s2的子集。我们选择了前6种最流行的事件类型(逮捕型、执行型、死亡型、满足型、判决型、起诉型),其中有548种手动标注类型。我们以ERE训练句子为基础,从系统生成的不同类型的集群中抽取500个负面事件提及(Huang et al.,2016)。我们将带注释的事件合并为可见类型和负面事件提及,使用90%用于培训,10%用于开发。为了评估,我们从剩下的ERE子集中选择200个句子,其中包含128个攻击事件提及和40个罪犯事件提及。表9分别给出了基于完美AMR和系统AMR的事件提取性能。使用相同的数据集,我们使用不同的语义解析输出进一步评估我们的方法的性能。我们通过只保留AMR注释中的核心角色(例如:ARG0,:ARG1)来比较AMR和语义角色标记(SRL)输出(Palmer et al., 2010)。如表9所示,与SRL输出相比,细粒度的AMR语义关系(如:location、:instrument)似乎更有助于推断参数角色。
4 相关工作
以往的事件提取方法大多基于符号特征的监督学习(Ji和Grishman, 2008;Miwa et al., 2009;Liao and Grishman, 2010;Liu et al., 2010;Hong等人,2011;McClosky等人,2011;Riedel和McCallum, 2011;陈和吴,2012;李et al .,2013;或者分布特征(Chen et al., 2015;阮Grishman, 2015;冯等人,2016;Nguyen等人,2016)从大量的训练数据中,将事件类型和参数角色作为符号。这样的工作可以为给定的类型实现高质量,但不能在没有注释的情况下应用于新类型。相比之下,我们提供了一个新的视角来看待事件提取,并利用事件类型的丰富语义将其建模为一个“基础”任务。
其他IE范例如开放IE (Etzioni et al., 2005;Banko等人,2007年,2008年;Etzioni等人,2011;Ritter et al., 2012),先发制人的IE (Shinyama and Sekine, 2006),按需的IE (Sekine, 2006),自由的IE (Huang et al., 2016, 2017),和基于语义框架的事件发现(Kim et al., 2013)可以发现很多事件,没有预定义的事件模式。事件类型和参数角色由一组类似的事件推断。这些范例严重依赖于信息冗余,所以当输入仅包含几个句子时就无法工作。我们的工作可以从任意大小的给定语料库中发现事件,并且可以与这些范例互补,因为它可以将每个事件集群作为一个丰富的预定义事件本体。
零射击学习在视觉目标分类中得到了广泛的应用(Frome et al., 2013;Norouzi et al., 2013;Socher等人,2013a),细粒姓名标签(Ma等人,2016;Qu等人,2016)和关系提取(Verga等人,2016)。
与这些任务不同的是,事件提取中看到的类型是有限的。最流行的事件模式(如ACE)只定义了33种事件类型,而大多数可视化对象训练集包含超过1000种类型。因此,由于过拟合的原因,所提出的零炮点视觉目标分类方法不能直接应用于事件提取。因此,我们通过创建“负面”训练实例来设计一个新的损失函数,以避免过度拟合。
5 结论与未来工作
在这项工作中,我们重新审视事件提取任务,并将其建模为一个接地问题。我们提出了一种可转移的神经体系结构,它利用现有的人类构建的事件模式和针对一小部分可见类型的手工注释,并将知识从现有类型转移到不可见类型的提取,以提高事件提取的可伸缩性,并节省人力。在没有任何注释的情况下,我们的方法可以与从大量标记数据中训练出来的最先进的监督模型达到类似的性能。将来,我们将通过合并事件定义和参数描述来扩展我们的框架,以提高事件提取性能。