学习判别性隐含属性实现零样本分类
摘要
零样本学习(ZSL)旨在将观察到的类中的知识迁移到看不见的类,基于这样的假设:已见和未见类共享一个共同的语义空间,其中最常用属性表示语义。 然而,很少有工作研究人类设计的语义属性是否足以识别不同的类别。 此外,属性通常彼此相关,独立地学习每个属性是不足够的。 在本文中,我们提出学习一个隐含属性空间,它不仅具有判别性,而且还具有语义保持性,用以执行ZSL任务。 具体地,利用字典学习框架将隐含属性空间与属性空间和相似性空间连接起来。在四个基准数据集上的大量实验表明了所提方法的有效性。
- 论文通过一个字典学习框架来学习隐含属性。然后连接隐含属性空间与属性空间和相似性空间实现判别性和语义保持性。
1. Introduction
随着数据规模的快速增长和分类方法的进步,在过去几年视觉识别取得了巨大的进步。然而,视觉识别的传统方法主要基于监督学习,其需要大量标记样本以获得高性能分类模型。众所周知,收集大量标记样本是困难的,特别是当所需标签是细粒度时,这阻碍了视觉识别的进一步发展。因此,开发能够识别具有很少或没有标记样本的类别的识别系统是重要且期望的,因此在过去几年中ZSL方法引起越来越多的关注。
受人类识别没见过的物体的能力的启发,ZSL旨在识别以前从未见过的类别[17,19]。 ZSL的一般假设是,已见和未见类共享一个共同的语义空间,样本和类原型被投影到该空间,以执行识别任务。就学习过程中利用的不同中间层表示而言,当前的ZSL方法可以分为四组。第一组是基于属性的方法,它利用属性来建立已见和未见类之间的关系[17,19,43,13]。例如,不同动物之间共享诸如黑色和毛茸茸等属性。属性跨类别的特性使得将知识从已见类迁移到未见类成为可能。第二组是基于文本的方法,它通过丰富的文本语料库自动挖掘不同类的关系[7,10,3,30]。这些方法减少了定义属性的人力,因此ZSL可以应用于大规模场景。第三个是基于类别相似性,它直接挖掘了已见和未见类之间的相似性,以桥接他们的关系[23,22,24,44]。相似性可以从分层类别结构或每个类的语义描述中导出。最后一组是结合不同的中间层表示来学习更强大的关系[11,12,19,15]。这些工作建立在一个共同的想法上,即不同的中间层表示可以捕获数据的补充信息,这可以用于减少已见和未见类之间的域差异。
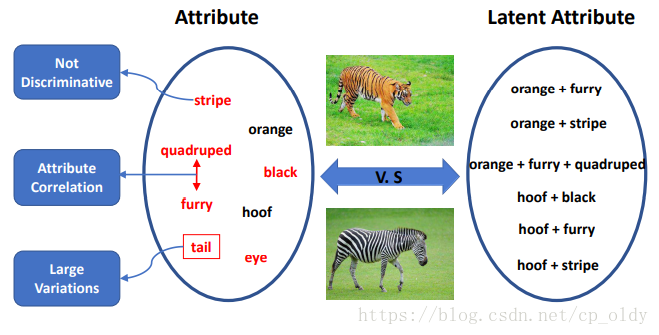
图1. 学习隐含属性的 动机。红色字体的属性没有判别力。带矩形框的属性具有很大的变化。双箭头连接的属性彼此相关。
在本文中,我们关注基于属性的方法。这类方法的传统过程主要集中在如何学习语义嵌入或用于执行识别任务的策略。然而,有三个方面在之前的工作中很少被考虑,如图1所示。第一,人类设计的语义属性是否具有足够的判别力以识别不同的类。第二,独立学习每个属性是否合理,因为属性通常彼此相关。第三,每个属性内的变化可能非常大,使得难以学习属性分类器。对于第一个方面,[43]提出学习判别性的类别级属性。但是,这些属性是在固定类别上学习的,并不关心语义含义。当新类出现时,类级表示必须重新学习。对于第二个方面,[14]将属性关系纳入学习过程。然而,这种关系是人为定义的,并且它们在现实世界中通常过于复杂而无法预先定义。对于第三方面,[15]利用域自适应方法来微调属性模型。但是,对于此类模型目标域样本是强制性的。
- 传统的方法主要考虑如何学习语义映射和利用什么策略执行识别任务。
- 学习隐含属性的三个动机:
1) 人类设计的属性是否具有足够的判别力?
2) 独立学习每个属性是否合理?
3) 每个属性内的变化可能非常大?
为了同时解决上述问题,我们提出学习隐含属性。具体而言,我们的方法自动探索不同属性的判别组合,其中每个组合被看作一个隐含属性。一方面,隐含属性需要有足够的辨别力,从而更可靠地对不同类别进行分类。另一方面,隐含属性应该是语义保留的,从而能够建立不同类之间的关系。此外,在隐含属性中也隐式地考虑了属性相关性。例如,毛茸茸经常与黑色和白色相关,因此单独学习毛茸茸是不利的。相比之下,我们的隐含属性能够找到毛茸茸+黑色和毛茸茸+白色的组合,因此每个隐含属性内的变化会小于每个属性内的变化。
- 隐含属性是不同属性的组合。具有两个特点:一,判别性;二,语义保持性。
为了学习隐含属性空间来执行ZSL任务,我们利用字典学习框架直接建模隐含属性空间,其中图像可以通过一些隐含属性的字典项重建。为了保留语义信息,利用线性变换来建立属性和隐含属性之间的关系,因此可以将隐含属性视为属性的不同组合。此外,为了使隐含属性具有辨别力,使用已见类分类器来对不同的类进行分类,其中概率输出可以看作与已见类的相似性。因此,我们可以将图像表示从隐含属性空间转换到相似空间。
- 如何直接建模隐含属性空间?
- 图形如何重建?
本文的其余部分安排如下:第2节讨论相关工作。第3节详细描述了我们提出的隐含属性字典(LAD)方法的制定和优化。第4节在四个基准ZSL数据集上对我们的方法进行了广泛的评估。第5节给出结论性意见。
2. Related Work
在本节中,我们将简要回顾有关属性和零样本学习的相关工作。
2.1 Attributes
属性是图像的一般描述,近年来在不同的计算机视觉任务中引起了很多关注,如图像描述[9],图像字幕[16],图像检索[35]和图像分类[41,21,27]。早期关于属性学习的工作通常将其视为二元分类问题并独立学习每个属性[9]。由于属性经常相互关联,[14]将属性关系纳入学习框架。此外,属性与类别相关,[21,1]提出联合学习属性和类标签。随着近年来深度学习越来越受欢迎,[8]对视觉属性与卷积网络的不同层之间的关系进行了分析。为了使属性具有判别性,[43,29]利用判别属性来进行分类任务。但是,这些属性没有语义含义。
2.2 Zero-Shot Learning
ZSL解决以前从没见过的类的识别问题。随着数据规模和图像标注的难度的增长,该应用近年来变得越来越流行。 ZSL,由[17]和[9]首先并行提出,由属性完成,它利用属性的跨类别特性来建立已见和未见类之间的关系。然后其他中间层语义描述被提出来解决这样的问题,例如词向量[7,10,3]和类相似性[23,22,24,44]。
零样本识别的一种直观方法是训练不同的属性分类器,并通过属性预测结果和未见类描述来识别图像[17,19]。考虑到属性分类器的不可靠性,[13]提出了一种随机森林方法来进行更强大的预测,[41,21,40]对属性和类之间的关系进行建模,以改进属性预测结果。为了利用语义流形上丰富的内在结构,[12]提出了语义流形距离来识别未见类样本。另一种广泛使用的方法是标签嵌入,它将图像和标签投影到一个共同的语义空间,并通过最近邻方法执行分类任务[1,2,26,44,19,42]。为了将ZSL扩展到大规模设置,使用神经网络来学习更复杂的非线性嵌入[25,10,37,3]。其他一些工作使用迁移学习技术将知识从已见类迁移到未见类[33,32,31,37,24,15]。最近,[45]提出捕捉相似空间中已见和未见类之间的隐含关系。[5]提出通过共享语义空间和特征空间之间的表示来直接合成未见类的分类器。[4]提出了一种度量学习方法来解决ZSL问题。 [6]将传统的ZSL问题扩展到广义的ZSL问题,其中在测试过程中也考虑了已见类。
ZSL的另一个流行假设是在问题设置中未见类的样本是可用的[11,19,15,46]。为了利用不同语义描述之间的补充信息,[11]提出了一种多视图嵌入方法,其中使用已见和未见类样本构建图模型,以减少已见和未见类之间的域差异。 [19]提出了一种半监督框架来直接学习没见过的分类器,其中语义信息可以作为辅助信息被合并。 [15]利用领域自适应方法来解决已见和未见类之间的域漂移问题。受到一个类别中样本的聚类属性的启发,[46]利用结构化预测方法识别未见类的样本。重要的是我们的方法不在这样的设置中。
3. Proposed Approach
我们提出了一个ZSL隐含属性字典(LAD)学习过程。设计目标函数有一些动机。首先,隐含属性应该保留语义信息,因此能够关联已见和未见类。 其次,隐含属性空间中的表示应该是有判别性的,以识别不同的类。 基于这些考虑,提出的LAD框架,如图2所示。
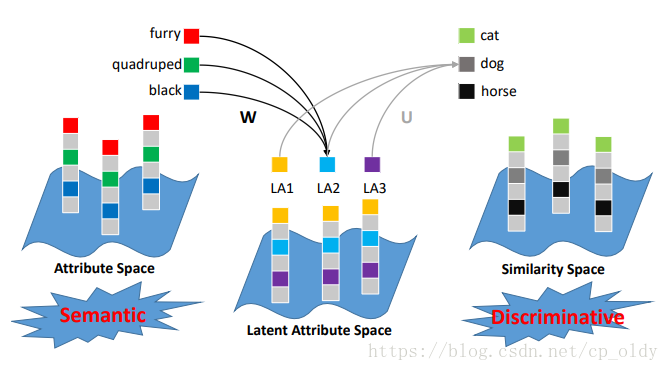
图2. ZSL的隐含属性字典学习框架。 提出的隐含属性空间与属性空间和相似性空间都关联。属性空间使隐含属性保持语义,而相似性空间使隐含属性具有判别性。
3.1 Problem Formulation
假设有属于 个已见类的 个标记样本 ,和属于 个未见类的 个未标记样本 。每个样本 表示成一个 维的特征向量。然后我们有 和 ,其中 , 。 和 是已见和未见类的样本的类标签。 在零样本识别设置中,已见和未见类是不交叠的:即 。 和 是已见和未见类的样本的 维的语义表示(即,属性标注),其中 和 。关于已见类的样本的语义信息 是提供的,而未见类的样本的是未知的。给定类别的语义描述 , ZSL的目标是预测 。
- 是样本特征表示, , 已知, 已知
- 是样本语义表示, , 已知, 未知
- 是样本类别标签, , 已知, 未知
- 是类别语义表示, , 已知
3.2 Latent Attribute Dictionary Learning
执行ZSL任务的关键问题是找到一个可以建立已见和未见类之间关系的公共空间。 传统方法选择属性空间来执行识别任务。 例如,[15]提出直接学习属性字典:
其中 表示F范数, 是学到的字典 的 第列,而 是重建系数。通过强制 为 ,学到的字典可以看看作属性的表示。 但是,这种约束太强。 如果我们放松语义约束,目标函数可以表示为:
公式2中的第二项使得 和属性表示 相似,从而保证学到的基描述属性字典项。
虽然属性在识别任务中被广泛使用,但有两件事应该考虑。 首先,用户定义的属性对于判别并不总是一样重要,因此我们可能不太希望直接学习每个属性。 其次,属性之间存在相关性,因此独立学习每个属性也不合适。为了解决这些问题,我们提出学习隐含属性。具体来说,我们使用字典学习框架直接建模隐含属性空间。为了保留语义信息,利用线性变换矩阵 来建立隐含属性和属性之间的关系,如图2所示:
其中 是 的第 列。从公式3可以推断出,隐含属性可以看作语义属性的线性组合,这将隐含地组合强相关属性。
为了使识别任务更有效,隐含属性应该具有判别性。换句话说,我们希望找到最具辨别力的属性组合来分类不同的类别。因此,我们利用已见类分类器使隐含属性更具辨别力。具体来说,学习一个从隐含属性空间到已见类的线性映射 ,如图2所示:
其中 和 是一个one-hot向量,表示了样本 的类标签。这里 的列向量 构成了相似性空间 ,其中每个维度表示与一个已见类的相似性。 可以看作隐含属性空间中的已见类分类器。公式4的第三项旨在使隐含属性表示足以区分不同类别。它隐式地将同一类中的样本拉到一起,并使来自不同类的样本彼此远离。
总之,本文方法学习的隐含属性不仅可以区分不同的类,还可以保留语义。如图2所示,得到的隐含属性空间与两种语义空间相连。首先,利用线性变换矩阵 将隐含属性空间与语义属性空间关联。通过 ,我们可以用隐含属性恢复属性表示,从而使隐含属性具有语义含义。其次,隐含属性空间中的类别分类器 可以看作隐含属性空间和相似性空间之间的连接。这种约束鼓励隐含属性具有辨别力。
3.3 Optimization
显然,公式4对于 同时不是凸的,但是对每一个分别是凸的。 因此,我们采用交替优化的方法来求解它。 具体来说,我们在以下子问题之间交替:
(1) 固定 , , 并更新隐含属性表示 。子问题可以表述为:
其中
是单位矩阵。强制公式5的导数为0, 的闭形式解是
(2) 固定 , , 并更新隐含属性字典 。子问题可以表述为:
这个问题可以通过拉格朗日对偶优化。因此公式7的解析解是
其中 是由所有拉格朗日对偶变量构造的对角矩阵。
(3) 固定 , , 并更新嵌入 。子问题可以表述为:
这个问题可以用与公式7相同的方式求解。 的解析解是
其中 是由所有拉格朗日对偶变量构造的对角矩阵。
(4) 固定 , , 并更新嵌入 。子问题可以表述为:
这个问题可以用与公式7相同的方式求解。 的解析解是
其中 是由所有拉格朗日对偶变量构造的对角矩阵。
算法1总结了完整的算法。在我们的实验中,优化过程总是在经过数十次迭代后收敛,通常小于50次。
————————————————————
算法 1 ZSL隐含属性字典学习
____________________________________
输入: , , ,
输出: , , , and
1:随机初始化 , , .
2:执行循环直到收敛
3: 用公式6更新 .
4: 用公式8更新 .
5: 用公式10更新 .
6: 用公式12更新 .
7:结束循环
————————————————————
3.4 ZSL Recognition
由于我们的隐含属性空间与属性空间和相似空间相关联,我们可以在多空间中执行ZSL。
隐含属性空间中的识别。 为了在隐含属性空间中执行ZSL,我们必须获得测试样本的隐含属性表示和未见类原型。给定一个测试样本及其特征向量 ,我们可以通过公式13得到它的隐含属性表示 :
其中 是从训练数据中学习的隐含属性字典。 是正则化项的权重。 对于未见类原型,我们通过变换矩阵 将它们的属性表示投影到隐含属性空间。然后可以计算测试样本和未见类之间的距离。 最后,我们使用余弦距离通过最近邻方法执行ZSL识别。
相似空间中的识别。如上所述,我们可以使用 将隐含属性表示 变换到相似性空间,其中每个维度表示与一个已见类的相似性。因此,每一张图像都可以由一个相似性向量 表示。此外,我们还可以通过将类属性向量映射到已见类比例的直方图表示来获得未见类原型的相似性表示,和[44]中所做类似。因此,可以执行最近邻方法以将测试样本分类为未见类。
属性空间中的识别。我们可以通过隐含属性表示 来恢复图像 的属性表示:
因此,每张图像的属性都可以获得。然后我们可以通过属性表示将测试图像分类到一个未见类。
结合多个空间。由于不同的空间可能包含一个未见类的补充信息,我们可以组合不同的空间来执行ZSL任务。在本文中,我们简单地连接图像的不同向量表示以形成最终表示,并且对于未见类原型执行相同的处理。然后可以通过上面提出的相同方法执行ZSL任务。
3.5 Discussion
和其他工作的区别。我们的方法主要受JLSE [45]和JSLA [29]的启发。 JLSE提出了隐含相似性空间来建立特征空间和相似性空间之间的关系,而我们利用相似性空间使我们的隐含属性更具辨别力。 JSLA提出分别学习用户定义的属性和判别属性,其中背景信息也被建模。但是,它不是为ZSL任务设计的,因为在ZSL设置中无法使用背景信息。相比而言,我们从ZSL任务中存在的实际问题出发,将语义和判别信息合并到隐含属性中,以便更有效地识别。
进一步提升。我们的方法基于线性模型。众所周知,基于深度学习的非线性模型会更强大。因此,我们使用深度网络来提取图像表示并在很大程度上确保有利的性能。相信直接通过深层模型学习语义转换将有助于提高性能,这仍然是未来工作的一个有前途的方向。
4. Experiments
在本节中,我们评估了方法在四个基准数据集上的性能,并分析了方法的有效性。
4.1 Datasets and Settings
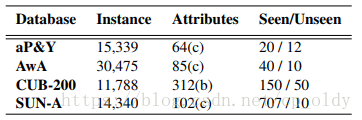
数据集。我们在四个基准ZSL数据集上进行实验,以验证方法的有效性,即aPascal & aYahoo (aP&Y)[9],Animal with Attributes(AwA)[17],Caltech-UCSD Birds-200-2011(CUB-200) )[39]和SUN Attribute(SUN-A)[28]。这些数据集的统计数据如表1所示。(a)aP&Y由两个属性数据集组成:aPascal包含12,695张图像,aYahoo包含2,644张图像。每张图像提供64维属性向量。aPascal有20个对象类,aYahoo有12个对象类,它们是不相交的。对于ZSL任务,aPascal数据集中的类别用作已见类,而aYahoo中的类别用作未见类。(b)AwA是一个动物数据集,包含50种动物类别,30,475张图像。每个类都有85个属性注释。 ZSL的标准分割是使用40个类作为已见类,其他10个类作为未见类。 c)CUB-200是用于细粒度识别的鸟类数据集。它包含200个类,11,788张图像,每张图像提供312个二进制属性。遵循与[1]相同的设置,我们将150个类别视为已见类,其他50个视为看不见的类。 (d)SUN-A用于高级场景理解和细粒度场景识别,包含717个类,收集了14,340张图像。每张图像有102个实值属性注释,它们由投票过程产生的。遵循[13],我们选择一样的10个类作为未见类。
参数设置。对于所有数据集,我们利用imagenet-vgg-verydeep-19预训练模型提取4096维CNN特征[36]。我们使用多类准确度作为评价指标。AwA的字典大小选择为300,其他三个数据集的字典大小选择为500到800。其他参数α和β使用五折交叉验证获得。γ和λ也可以调整,为简单起见我们将它们设置为1。更多细节可以在补充材料中找到。
4.2 Effectiveness of the Proposed Framework
提出的隐含属性空间与属性空间和相似空间相关联,这使得它不仅具有语义保持性,而且还具有判别性以区分不同的类。为了证明每个组件的有效性,我们比较了五种不同的方法,在数据集aP&Y上的实验结果如图3所示。(1)仅在属性空间(A)中的识别,通过直接学习属性字典,如公式2所述。(2)仅在相似性空间(S)中的识别,通过去除公式4中的语义约束(即第二项)。(3)在隐含属性空间中的识别且无判别性约束(LA-),通过去除公式4中的判别性约束(即第三项)。(4)在隐含属性空间中的识别且有判别性约束(LA)的,如公式4所述。(5)结合隐含属性空间和相似性空间的识别(LAS),如3.4节所述。
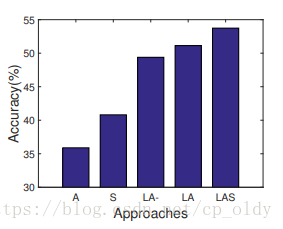
图3. aP&Y上五种方法的比较
通过比较 A, S 和 LA- 的性能,我们可以推断出隐含属性在ZSL任务中更为成功。此外,通过在目标函数中强加判别性约束,识别精度得到改善,如 LA 的性能所示。还有,隐含属性和已见类相似性的组合也改善了最终识别性能,如 LAS 的结果所示。
4.3 Benchmark Comparisons and Evaluations
在这部分中,我们与几种流行方法进行了比较。我们的设置与[44]相同。表2给出了四个数据集上的实验结果,其中空白表示对应方法在其原始论文中未在数据集上进行测试。在这里,对于我们的LAD方法,我们报告了两个变体LA和LAS的结果,如4.2节所述。重要的是要指出前三种方法是在直推式ZSL设置中,其中使用了未见类样本的信息,而我们的方法和其他竞争方法都是在传统的ZSL设置下。从该表中,我们可以看到本文的方法在三个数据集上实现了最佳性能,这表明了本文方法的有效性。注意,’*’表示对应的方法和我们使用的特征不同,其中[11,15]使用OverFeat [34]特征,[2,5,6]使用GoogleNet [38]特征功能。
从表2中可以看出,本文方法在CUB-200数据集上的性能有很大的提升。这归功于隐含属性字典的良好重构特性。该数据集是为细粒度识别任务设计的,其样本变化不是很大。因此,在已见类的样本上学习的词典可以很好地重构未见类的样本。借助隐含属性的判别特性,可以进一步提高对未见类样本的识别性能。我们在AwA上的结果略低于JSLA [29]。原因可能在于类级属性注释,这无法覆盖每个类内部的图像的变化。字典的重构准确率可能因此被有限的属性表示所影响。
4.4 Semantic-Preserving Property
与之前学习没有语义含义的判别属性的方法不同[43],我们的隐含属性是语义保留的。这可以通过以下两个方面来体现。
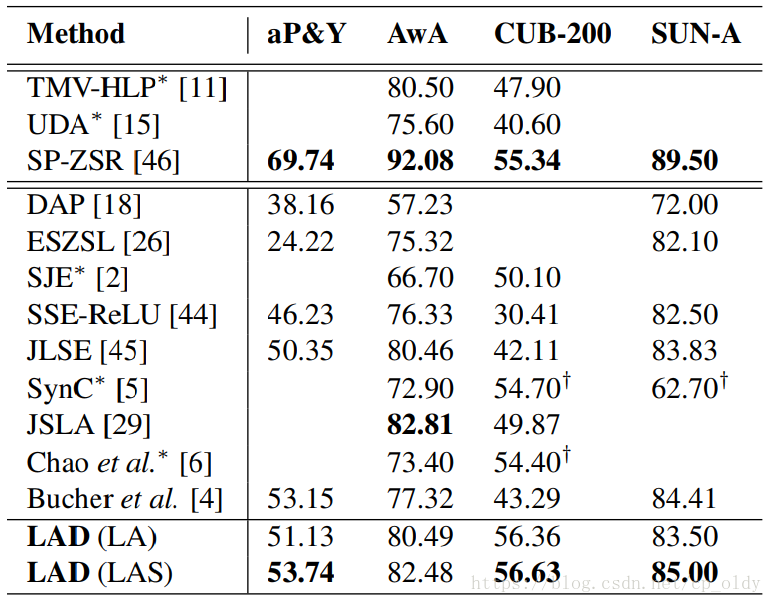
首先,我们可以通过图像的隐含属性表示来恢复图像的属性,如公式14所示。为了测试恢复的属性好不好,我们在AwA上执行属性预测任务。具体而言,我们通过原始数据集提供的阈值对属性进行二值化,并通过曲线下面积(AUC)何亮性能。图4显示了未见的属性预测结果。空白表示在未见类中没有这样的属性。我们可以断定,大多数从隐含属性中恢复的属性都具有相对较好的性能,这证明了隐含属性的语义保持性。通过我们的方法恢复的属性的平均AUC是0.729,这与其他属性预测结果可以比肩[29]。由于我们的方法的主要目的不是属性预测,因此不进行进一步的详细比较。
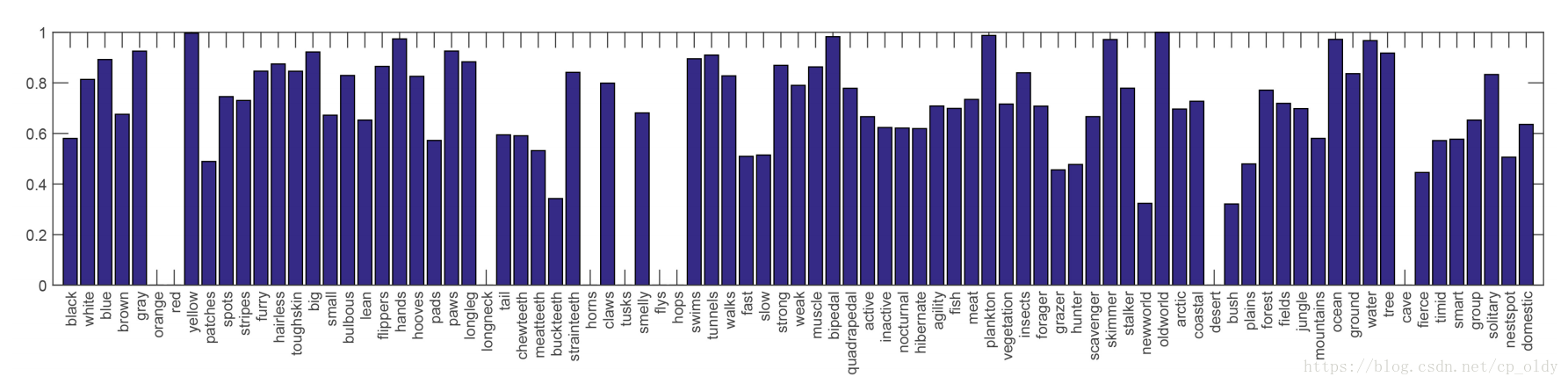
图4. 在AwA数据集上的AUC属性预测结果
其次,隐含属性可以看作属性的不同组合。为了直观地了解组合是什么,我们对一些隐含属性词典进行了可视化。具体而言,给定一个隐含属性字典项目,我们显示在该字典项上具有最大和最小对应关系的图像。图5显示了使用AwA数据集上的未见类样本的可视化结果。此外,在图5中我们还显示了对一个隐含属性最大和最小激活的属性。可以观察到,与隐含属性具有高度对应关系的图像和属性组合也一致。例如,海豹与隐含属性“LA1”的绿色块中的属性高度相关,并且与红色块中的属性几乎没有关联。我们可以断定一个特定的隐含属性可以对一些高度相关的属性进行分组,因此每个隐含属性内的变化变得更小。希望隐含属性仅在少量属性上具有强激活。虽然我们没有显式强加这种稀疏性约束,但在我们的实验研究中发现组合系数大多是稀疏的。由于空间有限,详细的统计结果和分析在补充材料中提供。

图5.隐含属性字典可视化,使用AwA上的未见类的样本。 ‘LA’是隐含属性。 绿色块显示具有最大激活的属性,红色块显示具有最小激活的属性。 前三个图片是从对隐含属性具有最大激活的图像中随机选择的,后三个是从具有最小激活的图像中选择的。
4.5 Discriminative Property
从公式4中的目标函数,可以看出在隐含属性空间中学习已见类的分类器可以实现判别性约束。每个图像的已见类分类器的概率输出可以看作在相似性空间中的向量表示,其中每个维度表示与一个已见类的相似性。图6显示了与aP&Y上的一些未见类样本相对应的前五个最相似的已见类,其概率输出是通过softmax函数获得的。 可以看出,大多数相似性是人类可理解的。例如,狼与猫最相似,而滑水艇与摩托车最相似。
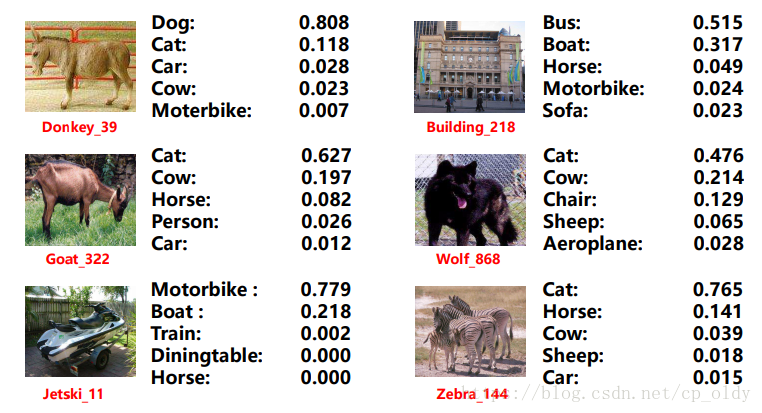
图6. aP&Y上未见类的样本的相似性表示。 显式了前五个相似的类。
5. Conclusion
在本文中,我们提出了一种新的ZSL方法,它通过隐含属性字典学习(LAD)来完成。我们的方法在四个数据集上显示了有效性。 我们将LAD的优秀性能归功于三个方面。 首先,我们提出的隐含属性空间与属性空间相关联,因此它保留了语义信息。 因此可以在隐含属性空间中执行ZSL任务。 其次,隐含属性空间与相似性空间相关联。 这使得隐含属性空间具有判别力以识别不同的类别。 第三,隐含属性可以看作语义属性的不同组合,这隐式地处理了属性相关性问题。
为了执行ZSL任务,我们还需要未见类的原型的相似性表示。这可以通过[44]提出的方法获得,如3.4节所述。图7显示了在aP&Y上未见类到已见类的相似性,其中值被标准化。 可以推断,大多数相似性也符合人类知识。 由于相似性抓住了一些未见类的信息,我们也可以使用这种语义信息来执行ZSL任务。 然而,由于已见类的数量有限,因此一些相似性并不那么可理解,例如bag的相似性表示。
图7. aP&Y上未见类的原型的相似性表示。 每列表示一个未见类与已见类的相似性。
如上所述,为了使隐含属性具有判别性,我们利用已见类分类器将隐含属性空间连接到相似性空间。为了探究隐含属性是否具有辨别力,通过我们的方法学习的隐含属性表示来可视化AwA中未见类的样本。具体来说,我们使用t-SNE [20]将每个未见类样本学到的隐含属性表示投影到二维平面。图8显示了可视化结果。我们可以看到同一类的图像被分组在一起,而来自不同类的图像被分开,这表明隐含属性对于识别任务是有判别性的。一个非常有趣的发现是视觉上相似的类具有较小的距离。例如,猪的聚类接近河马的聚类,座头鲸的聚类靠近海豹的聚类。这再次表明隐含属性保留了语义信息。

图8. AwA上未见类样本的可视化,使用隐含属性表示。 每种颜色代表一个类,每个点代表一张图像。