Strom特点:
- 时效性高,低延迟
- 逐条处理数据
- 没持久化层,支持多语言
- 本地模式,可模拟集群所有功能
- 使用原语(spout和bolts)类似于MapReduce 中的Map和Reduce
Storm 启动就没有结束,除非手动kill掉,storm的数据一直在内存中流转,Hadoop适用磁盘作为中间交换的介质
Storm :
- 以Tuple为单位组成一条有向无界的流数据
- Topology,类似MapReduce中的job
-
- 由spouts和bolts组成的图,通过stream grouping将spouts和bolts连接起来
- 任何一个spouts都是一个task 都是一个线程
- Topology执行任务时,storm jar 负责连接到Nimbus(相当于JobTracker)
Spout线程:
消息来源,包括可靠行消息(可靠性消息如果没有处理成功,可重新发送一个tuple,spout可监控消息发送的处理的成功失败),不可靠性消息
主要是nextTuple
Bolt 线程:
消息处理逻辑,可以发射多个数据流,主方法为execute(以tuple为输入,处理具体的tuple,OutPutCollector的ack,确认)
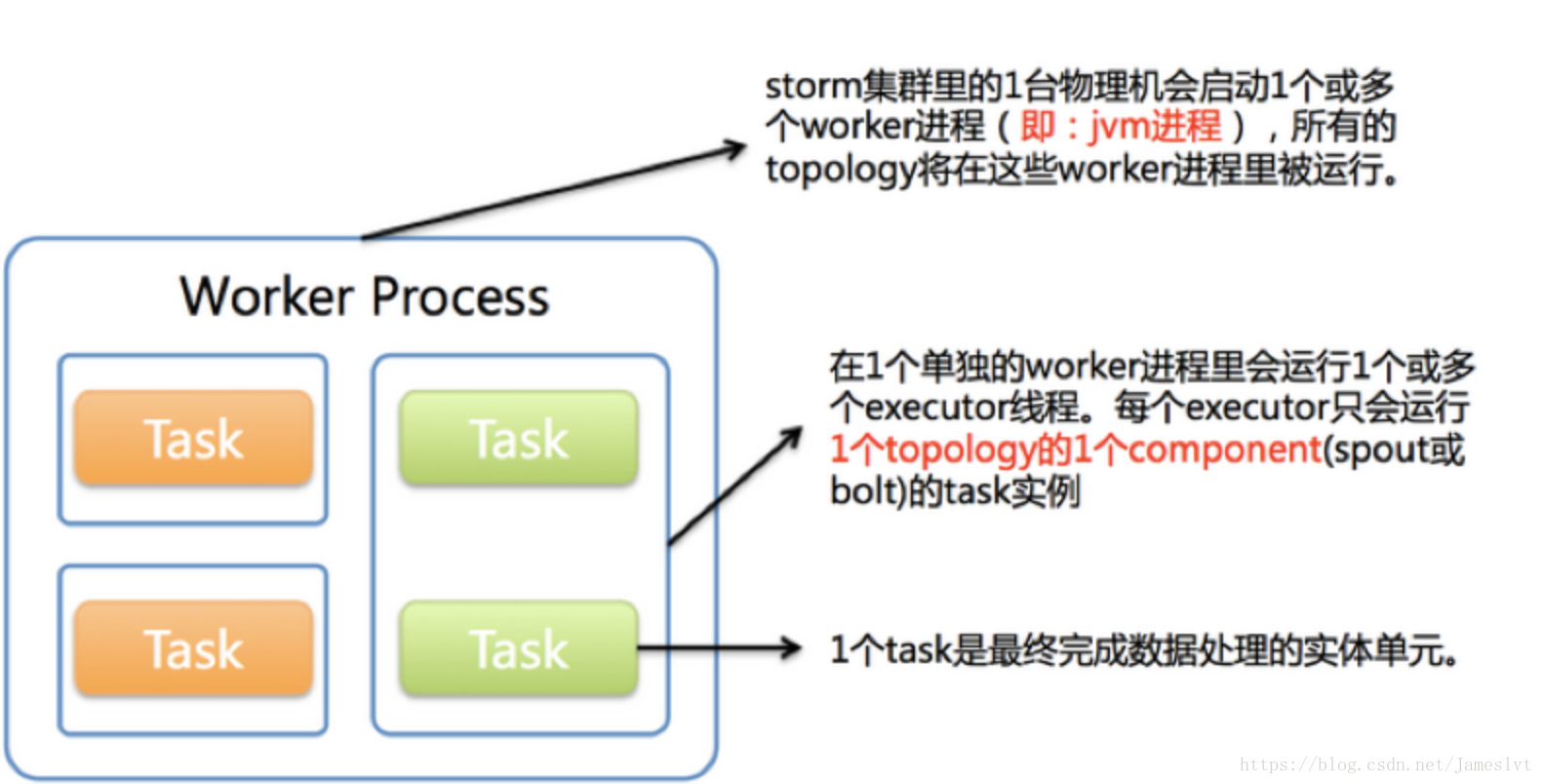
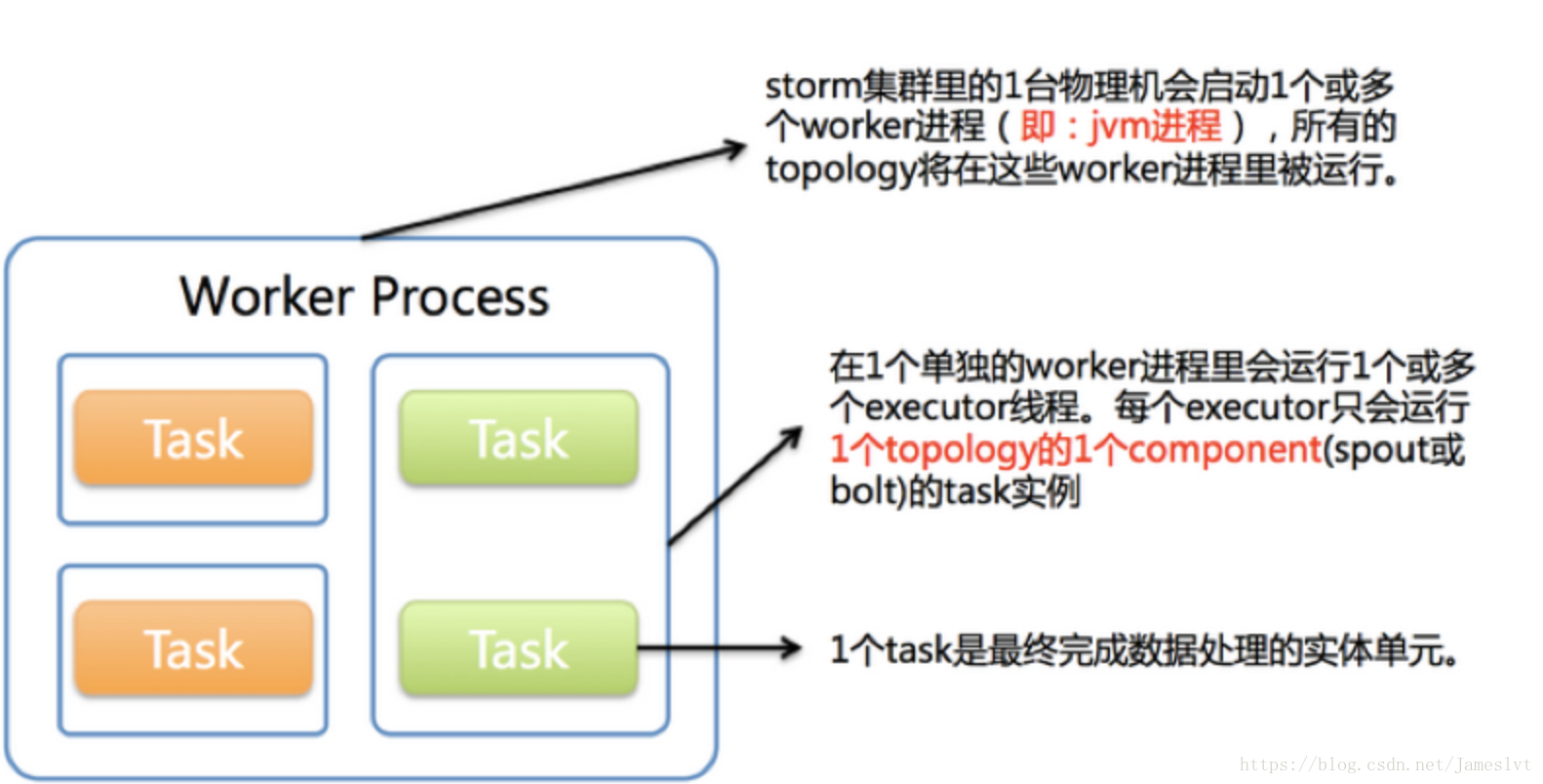
spout 和bolt 线程叫做task ,很多个task共享同一个executor线程,每个spout和bolt都会被当作很多task在集群中执行,每个executor都会被当作一个线程,在一个executor线程上会执行很多个task,标准来说,executor是真真实实线程,task是executor处理一个或多个实例对象,那么这个任务就是spout和bolt ,task本质就是一个节点类的实例对象
set_num_task 来配置一个executor 同时处理多少个task
work是进程,work里面有多个executor
StreamGrouping:
-Shuffle Grouping: 随机分组 负载均衡
-Fields Groping :按指定的filed分组
-All Grouping :广播分组
-Global Grouping:全局分组
Storm 可以做的事:
流式计算:
过滤,组装
持续计算
分布式RPC
Nimbus和Supervisor 所有协调工作都是通过Zookeeper来完成
Nimbus和Supervisor进程都是快速失败(fail-fast)和无状态的,所有的状态要么在Zookeeper上,要么在本地
executor中有多个task ,并不是每个task同时运行,只会选择一个执行,然后进行轮转进行,默认情况只有一个task
task是spout和bolt执行的最小单元
executor的数目
executor是真正的并行度(事实上的并行度)。(task数目是想要设置的并行度)
executor初始数目=spout数目+bolt数目+acker数目 (这些加起来也就是task数目。)
spout数目,bolt数目,acker数目运行时是不会变化的,但是executor数目可以变化
Worker
与
Task
关系
Strom 容错:
架构容错:
Zookeeper 存储Nimbus和Supervisor数据
节点宕机
Nimbus/Supervisor宕机
Worker 出错
数据容错:
可靠性指Storm会告知用户每个消息单元是否在指定时间完全被处理
Ack机制,本质是一个或多个task(特殊的task,而且非常轻量,执行的线程),采用简单的异或原理,假如一个tuple没有ack,就会出现备份的ack,假如备份的ack(采用一致性hash的方式)全挂,就会被当作超时处理
心跳形式有两种:一种是由worker来汇报(executor),第二种是由supervisor来汇报(自己状态)