官方链接
http://storm.apache.org/releases/1.2.2/Understanding-the-parallelism-of-a-Storm-topology.html
并行度概念详解

一个topology可以由多个worker来组成,一个woker进程之服务一个topology,在一个woker进程上可能会运行一到多个executor,这些executor专门来处理多个组件(spouts和bolts),一个正在运行测topology由storm集群中多个进程构成。
一个executor是由一个worker线程产生的,它能够运行一到多个task在多个组件(spouts和bolts)上。
task执行实际的数据处理——在代码中实现的每个spout或bolt在集群中执行相同数量的task。在topology的整个生命周期中,组件的tasd数量总是相同的,但是组件的executor(threads)数量可以随着时间的推移而手动调整。这意味着threads<=tasks
一个worker进程执行的是一个topo的子集
一个worker进程会启动1..n个executor线程来执行一个topo的component
一个运行的topo就是由集群中多台物理机上的多个worker进程组成
executor是一个被worker进程启动的单独线程,每个executor只会运行1个topo的一个component
task是最终运行spout或者bolt代码的最小执行单元
默认:
一个supervisor节点最多启动4个worker进程
每一个topo默认占用一个worker进程
每个worker进程会启动一个executor
每个executor启动一个task
这些配置的优先关系:(一般配置topology-specific configuration代码里)
defaults.yaml < storm.yaml < topology-specific configuration < internal component-specific configuration < external component-specific configuration.
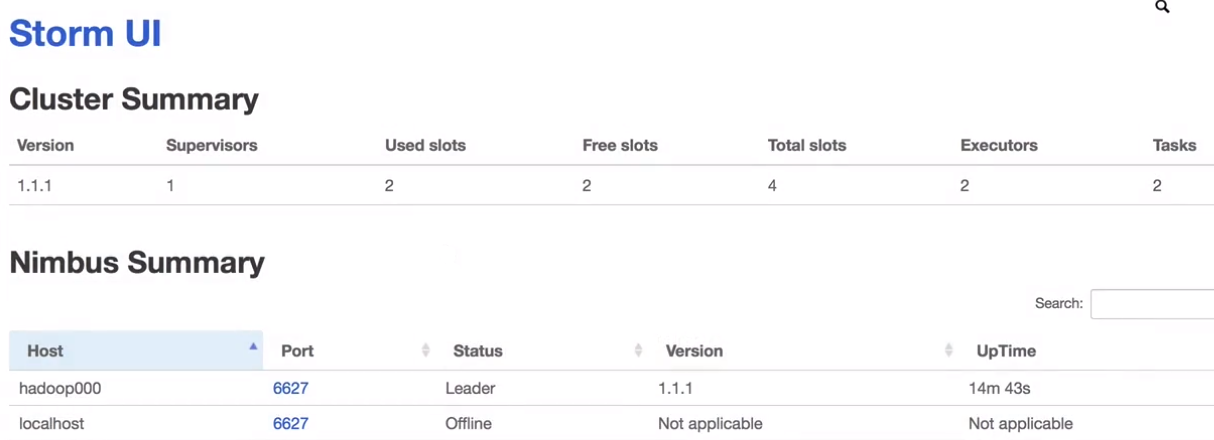
Storm作业运行UI页面上的参数详解
运行job是之前求和的作业


Total slots:4
四个就是配置文件里默认的ports(图中绿色部分)
Executors: 3 ??? spout + bolt = 2 why 3?
acker 导致的
并行度设置
worker数量的设置
import org.apache.storm.Config;
import org.apache.storm.StormSubmitter;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import org.apache.storm.utils.Utils;
import java.util.Map;
/**
* 使用Storm实现积累求和的操作
*/
public class ClusterSumStormWorkersTopology {
*******************中间代码省略*****************
public static void main(String[] args) {
// TopologyBuilder根据Spout和Bolt来构建出Topology
// Storm中任何一个作业都是通过Topology的方式进行提交的
// Topology中需要指定Spout和Bolt的执行顺序
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("DataSourceSpout", new DataSourceSpout());
builder.setBolt("SumBolt", new SumBolt()).shuffleGrouping("DataSourceSpout");
// 代码提交到Storm集群上运行
String topoName = ClusterSumStormWorkersTopology.class.getSimpleName();
try {
//设置workers为2;ack为0
Config config = new Config();
config.setNumWorkers(2);
config.setNumAckers(0);
StormSubmitter.submitTopology(topoName,config, builder.createTopology());
} catch (Exception e) {
e.printStackTrace();
}
}
}
重新打包上传服务器观察ui界面

executor数量的设置
import org.apache.storm.Config;
import org.apache.storm.StormSubmitter;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import org.apache.storm.utils.Utils;
import java.util.Map;
/**
* 使用Storm实现积累求和的操作
*/
public class ClusterSumStormExecutorsTopology {
=====中间代码省略=====
public static void main(String[] args) {
// TopologyBuilder根据Spout和Bolt来构建出Topology
// Storm中任何一个作业都是通过Topology的方式进行提交的
// Topology中需要指定Spout和Bolt的执行顺序
//Spout和Bolt都设置为2
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("DataSourceSpout", new DataSourceSpout(), 2);
builder.setBolt("SumBolt", new SumBolt(), 2).shuffleGrouping("DataSourceSpout");
// 代码提交到Storm集群上运行
String topoName = ClusterSumStormExecutorsTopology.class.getSimpleName();
try {
Config config = new Config();
config.setNumWorkers(2);
config.setNumAckers(0);
StormSubmitter.submitTopology(topoName,config, builder.createTopology());
} catch (Exception e) {
e.printStackTrace();
}
}
}
重新打包上传服务器观察ui界面


task数量的设置
import org.apache.storm.Config;
import org.apache.storm.StormSubmitter;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import org.apache.storm.utils.Utils;
import java.util.Map;
/**
* 使用Storm实现积累求和的操作
*/
================中间代码省略=======
public class ClusterSumStormTasksTopology {
public static void main(String[] args) {
// TopologyBuilder根据Spout和Bolt来构建出Topology
// Storm中任何一个作业都是通过Topology的方式进行提交的
// Topology中需要指定Spout和Bolt的执行顺序
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("DataSourceSpout", new DataSourceSpout(), 2);
builder.setBolt("SumBolt", new SumBolt(), 2)
.setNumTasks(4)//设置bolt的task数量
.shuffleGrouping("DataSourceSpout");
// 代码提交到Storm集群上运行
String topoName = ClusterSumStormTasksTopology.class.getSimpleName();
try {
Config config = new Config();
config.setNumWorkers(2);
config.setNumAckers(0);
StormSubmitter.submitTopology(topoName,config, builder.createTopology());
} catch (Exception e) {
e.printStackTrace();
}
}
}
重新打包上传服务器观察ui界面


acker的设置
import org.apache.storm.Config;
import org.apache.storm.StormSubmitter;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import org.apache.storm.utils.Utils;
import java.util.Map;
/**
* 使用Storm实现积累求和的操作
*/
public class ClusterSumStormAckerTopology {
=======代码省略============
public static void main(String[] args) {
// TopologyBuilder根据Spout和Bolt来构建出Topology
// Storm中任何一个作业都是通过Topology的方式进行提交的
// Topology中需要指定Spout和Bolt的执行顺序
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("DataSourceSpout", new DataSourceSpout(), 2);
builder.setBolt("SumBolt", new SumBolt(), 2)
.setNumTasks(4)
.shuffleGrouping("DataSourceSpout");
// 代码提交到Storm集群上运行
String topoName = ClusterSumStormAckerTopology.class.getSimpleName();
try {
Config config = new Config();
config.setNumWorkers(2);
StormSubmitter.submitTopology(topoName,config, builder.createTopology());
} catch (Exception e) {
e.printStackTrace();
}
}
}
重新打包上传服务器观察ui界面


并行度案例讲解及并行度动态调整
下图显示了一个简单的拓扑在运行时的样子。该拓扑由三个部分组成:一个称为BlueSpout的Spout和两个称为GreenBolt和YellowBolt的Bolt。这些组件是链接在一起的,这样BlueSpout就可以将它的输出发送给GreenBolt, GreenBolt再将它自己的输出发送给YellowBolt。
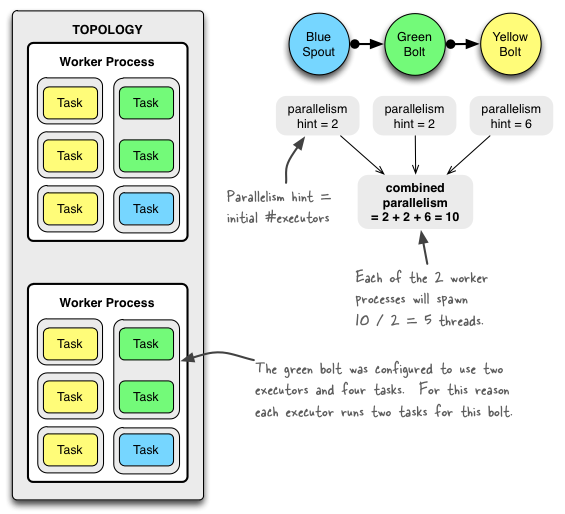
Config conf = new Config();
conf.setNumWorkers(2); // use two worker processes
topologyBuilder.setSpout("blue-spout", new BlueSpout(), 2); // set parallelism hint to 2
topologyBuilder.setBolt("green-bolt", new GreenBolt(), 2)
.setNumTasks(4)
.shuffleGrouping("blue-spout");
topologyBuilder.setBolt("yellow-bolt", new YellowBolt(), 6)
.shuffleGrouping("green-bolt");
StormSubmitter.submitTopology(
"mytopology",
conf,
topologyBuilder.createTopology()
);
Storm的一个很棒的特性是,您可以增加或减少工作进程和/或执行器的数量,而不需要重新启动集群或Topology。这样做的行为被称为动态调整。
您有两个选择来动态调整::
- 使用Storm web UI重新平衡拓扑。
- 如下面所述,使用CLI工具storm重新平衡。
下面是一个使用CLI工具的例子:
## Reconfigure the topology "mytopology" to use 5 worker processes,
## the spout "blue-spout" to use 3 executors and
## the bolt "yellow-bolt" to use 10 executors.
$ storm rebalance mytopology -n 5 -e blue-spout=3 -e yellow-bolt=10
命令行客户端的链接:
http://storm.apache.org/releases/1.2.2/Command-line-client.html
使用rebalance动态调整