Storm架构详解
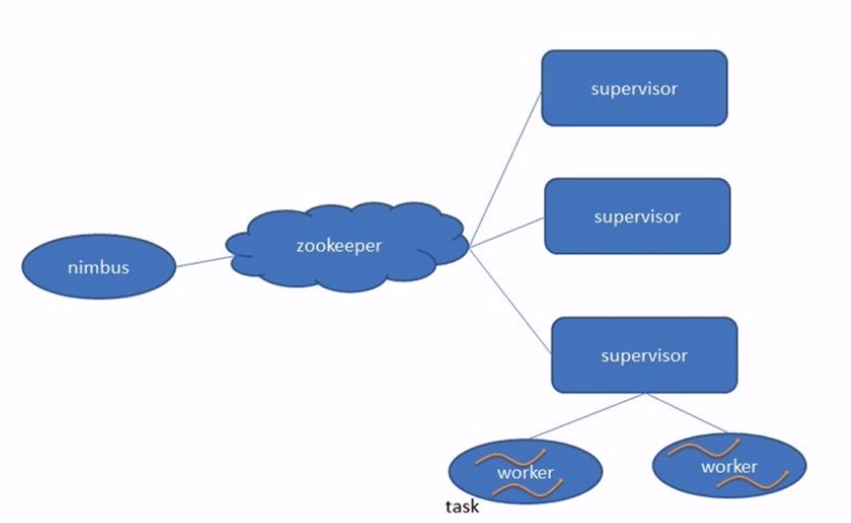
Storm架构
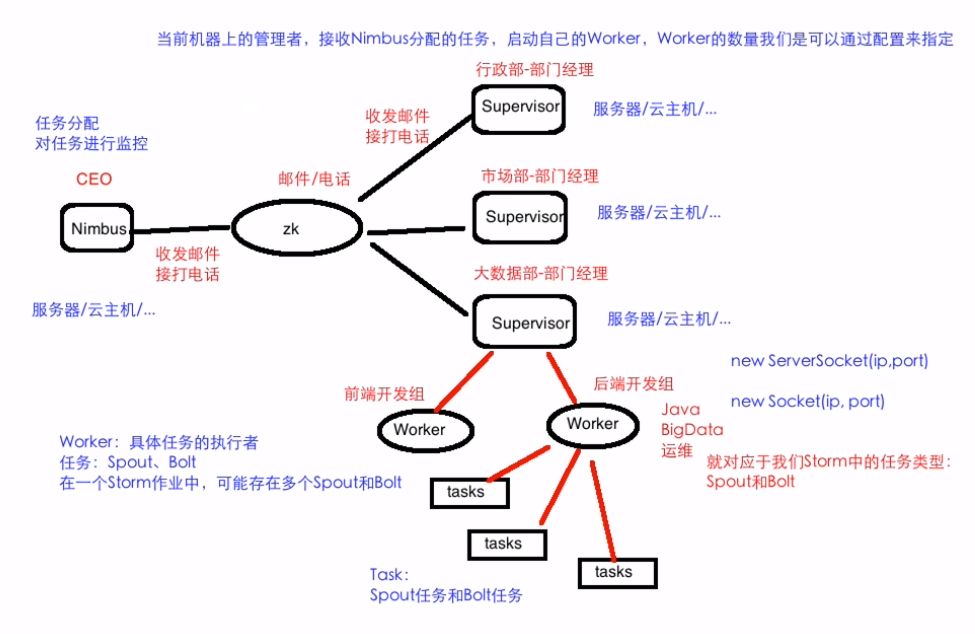
类似于Hadoop的架构,主从(Master/Slave)
Nimbus: 主
集群的主节点,负责任务(task)的指派和分发、资源的分配
Supervisor: 从
可以启动多个Worker,具体几个呢?可以通过配置来指定(后面笔记整理)
一个Topo可以运行在多个Worker之上,也可以通过配置来指定
集群的从节点,(负责干活的),负责执行任务的具体部分
启动和停止自己管理的Worker进程
无状态,在他们上面的信息(元数据)会存储在ZK中
Worker: 运行具体组件逻辑(Spout/Bolt)的进程
task:
Spout和Bolt
Worker中每一个Spout和Bolt的线程称为一个Task
executor: spout和bolt可能会共享一个线程
(并行度笔记会有对worker、task、executor的整理)
架构图解
Storm单机部署
官方链接
http://storm.apache.org/releases/1.2.2/Setting-up-a-Storm-cluster.html
Storm部署的前置条件
jdk7+
python2.6.6+(python3.x也是可以的;但是有些测试用例是会出错的)
Storm部署
下载
解压到~/app
添加到系统环境变量:~/.bash_profile
export STORM_HOME=/home/hadoop/app/apache-storm-1.1.1
export PATH=$STORM_HOME/bin:$PATH
使其生效: source ~/.bash_profile
目录结构
bin
examples
conf
lib
Storm启动
$STORM_HOME/bin/storm 如何使用 执行storm就能看到很多详细的命令
dev-zookeeper 启动zk(storm自带zk)
storm dev-zookeeper -->前台启动
nohup sh storm dev-zookeeper & -->后台启动
jps : dev_zookeeper
nimbus 启动主节点
nohup sh storm nimbus &
supervisor 启动从节点
nohup sh storm supervisor &
ui 启动UI界面
nohup sh storm ui & //默认8080端口
logviewer 启动日志查看服务
nohup sh storm logviewer &
storm的ui

supervisor 启动后

注意事项
1) 为什么是4个slot (默认)
2) 为什么有2个Nimbus(1.X之后就解决了单点故障问题;所以会默认有两个nimbus)
改写Storm作业并提交到Storm单节点集群运行
官方链接:
http://storm.apache.org/releases/1.2.2/Running-topologies-on-a-production-cluster.html
主要是main方法里的
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.generated.AlreadyAliveException;
import org.apache.storm.generated.AuthorizationException;
import org.apache.storm.generated.InvalidTopologyException;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import org.apache.storm.utils.Utils;
import java.util.Map;
/**
* 使用Storm实现积累求和的操作
*/
public class ClusterSumStormTopology {
***************************************************
**************main方法之前的代码和之前本地代码一样******
***************************************************
public static void main(String[] args) {
// TopologyBuilder根据Spout和Bolt来构建出Topology
// Storm中任何一个作业都是通过Topology的方式进行提交的
// Topology中需要指定Spout和Bolt的执行顺序
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("DataSourceSpout", new DataSourceSpout());
builder.setBolt("SumBolt", new SumBolt()).shuffleGrouping("DataSourceSpout");
// 代码提交到Storm集群上运行
String topoName = ClusterSumStormTopology.class.getSimpleName();
try {
StormSubmitter.submitTopology(topoName,new Config(), builder.createTopology());
} catch (Exception e) {
e.printStackTrace();
}
}
}
打包 mvn clean package -DskipTests
(如果按照官方打包;所有的包都会打进去;比较大)
将包放入服务器中
运行
Storm如何运行我们自己开发的应用程序呢?
给出的官方链接有详细讲解
Syntax: storm jar topology-jar-path class args0 args1 args2
storm jar /home/hadoop/lib/storm-1.0.jar com.imooc.bigdata.ClusterSumStormTopology
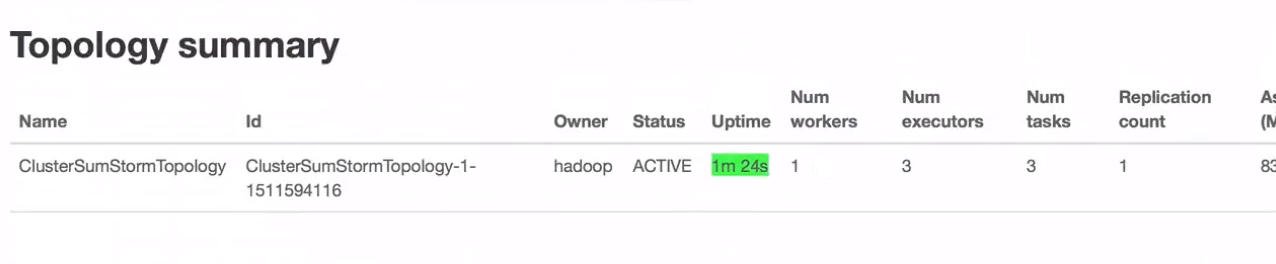

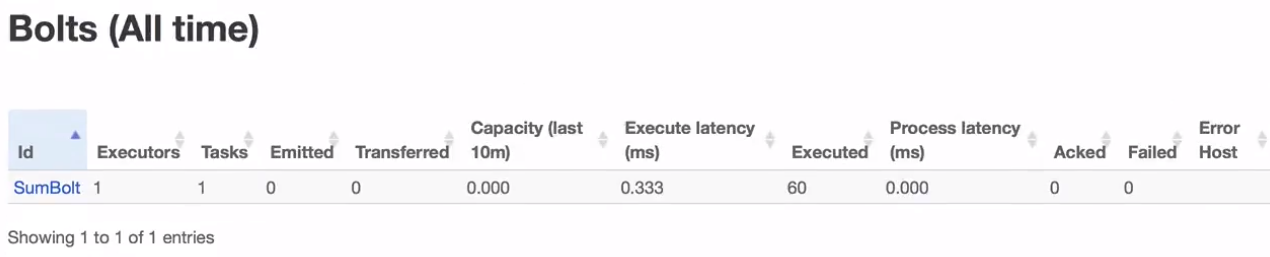
问题: 3个executor,那么页面就看到spout1个和bolt1个,那么还有一个去哪了?
Storm常用命令介绍

list
Syntax: storm list 或者在UI上查看
List the running topologies and their statuses.
如何停止作业
kill
Syntax: storm kill topology-name [-w wait-time-secs]
也可以再ui中点击停止
如何停止集群
hadoop: stop-all.sh
kill -9 pid,pid....
Storm集群部署规划
官方文档:
http://storm.apache.org/releases/1.2.2/Setting-up-a-Storm-cluster.html
Storm集群的部署规划
hadoop000 192.168.199.102
hadoop001 192.168.199.247
hadoop002 192.168.199.138
每台机器的host映射:/etc/hosts
192.168.199.102 hadoop000
192.168.199.247 hadoop001
192.168.199.138 hadoop002
//zk配置一般是奇数的
hadoop000: zk nimbus supervisor
hadoop001: zk supervisor
hadoop002: zk supervisor
如果配置主备
hadoop000: zk nimbus supervisor
hadoop001: zk nimbus supervisor
hadoop002: zk supervisor
安装包的分发: 从hadoop000机器做为出发点
scp xxxx hadoop@hadoop001:~/software
scp xxxx hadoop@hadoop002:~/software
jdk的安装
解压
配置到系统环境变量
验证
ZK分布式环境的安装//zoo.zfg
server.1=ctgexh01:2888:3888
server.2=ctgexh03:2888:3888
server.3=ctgexh04:2888:3888
hadoop000的dataDir目录: 文件myid的值1
hadoop001的dataDir目录: 文件myid的值2
hadoop002的dataDir目录: 文件myid的值3
在每个节点上启动zk: zkServer.sh start
在每个节点上查看当前机器zk的状态: zkServer.sh status
Storm集群
$STORM_HOME/conf/storm.yaml [storm-env.sh下的jdk环境变量也需要配置一下]
storm.zookeeper.servers:
- "hadoop000"
- "hadoop001"
- "hadoop002"
storm.local.dir: "/home/hadoop/app/tmp/storm" //注意冒号后要有空格
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
启动
hadoop000: nimbus supervisor(ui,logviewer)
hadoop001: supervisor(logviewer)
hadoop002: supervisor(logviewer)
nimbus 启动主节点 在bin目录下
nohup sh storm nimbus &
supervisor 启动从节点
nohup sh storm supervisor &
ui 启动UI界面
nohup sh storm ui &
logviewer 启动日志查看服务
nohup sh storm logviewer &
启动完所有的进程之后,查看
[hadoop@hadoop000 bin]$ jps
7424 QuorumPeerMain
8164 Supervisor
7769 nimbus
8380 logviewer
7949 core
[hadoop@hadoop001 bin]$ jps
3142 logviewer
2760 QuorumPeerMain
2971 Supervisor
[hadoop@hadoop002 bin]$ jps
3106 logviewer
2925 Supervisor
2719 QuorumPeerMain
运行作业后;进入storm.local.dir目录输入命令tree就可以看到运行作业的目录结构
storm jar /home/hadoop/lib/storm-1.0.jar com.imooc.bigdata.ClusterSumStormTopology
目录树
storm.local.dir
nimbus/inbox:stormjar-....jar //正在运行的Topology信息
supervisor/stormdist
ClusterSumStormTopology-1-1511599690
│ │ ├── stormcode.ser //序列化的 代码的
│ │ ├── stormconf.ser //配置文件的
│ │ └── stormjar.jar //jar包的