《Storm实战构建大数据实时计算》
《从零开始学Storm》 学习笔记
一致性事务
storm是一个分布式流处理系统,利用anchor和ack机制保证了所有tuple都被成功处理。如果出错了,则可以被重传,但是如何保证出错的tuple只被处理一次呢?Storm提供了一套事务性组件Transactional Topology,来解决这个问题。
设计1:强顺序流
每次处理一个tuple,在当前tuple被topolopy成功处理之前,不对下一个tuple进行处理。
例:从1开始,给每个tuple都顺序加上一个id,在处理tuple时,将处理成功的tuple-id记录在数据库中。下一个tuple来时,将处理成功的tuple-id跟数据库比较,如果相同则说明已经被处理,那么可以忽略它;如果不相同,则说明这个tuple没被处理过,将它的以及计算结果更新到数据库中。
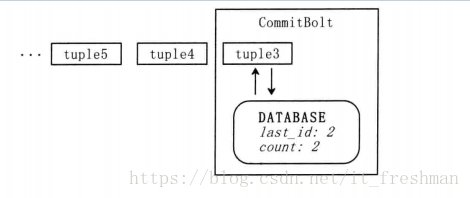
这种设计最为简单, 但是存在严重的问题,它每次只能处理一个tuple,效率十分低下。
设计2:强顺序batch流
每次处理一批batch .一个batch中的tuple可以被并行处理。
例:参照设计1,我们需要保证一个batch只被处理一次,数据库存储的是batch id.batch的中间计算结果先存在局部变量中,当batch中所有的tuple都被处理完之后,判断batch id,如果跟数据库中的id不同,则将中间计算结果更新到数据库中。
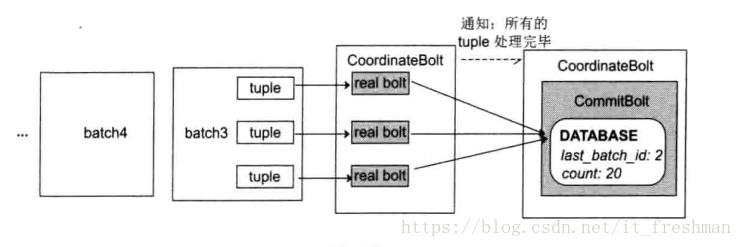
顺序性batch流也有局限性,每次只能处理一个batch,batch之间无法并行。
如何确定一个batch里面的tuple都处理完成了呢?
需要利用Strorm的CoordinatedBolt,CoordinatedBolt具体原理如下:
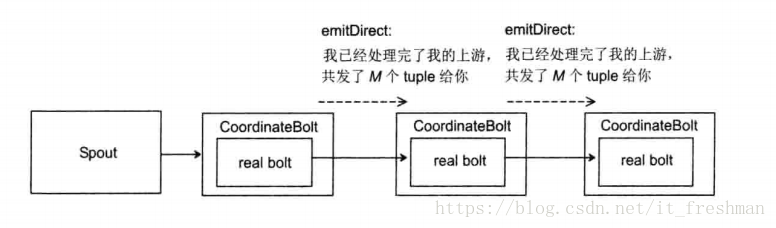
- 真正执行计算的Bolt外面封装了一个CoordinatedBolt,我们将真正执行任务的Bolt称为real bolt.
- 每个CoordinatedBolt记录两个值:有哪些task给我发送了tuple(根据topology的grouping信息),以及我要给哪些task发送消息(同样根据grouping信息)
- real bolt发出一个tuple后,其外层的CoordinatedBolt会记录下这个tuple发送给了那个task
- 等所有的tuple发送完成之后,CoordinatedBolt通过另外一个特殊的Stream以emitDirect的方式告诉所有发送过tuple的task,它发送了多少tuple给这个task.下游task会将这个数字和自己已经接收的tuple数量做对比。如果相等,则说明处理完了所有的tuple.
- 下游CoordinatedBolt会重复上面的步骤,通知其下游。
CoordinatedBolt主要用于如下两个场景:
- DRPC
- Transactional Topology
CoordinatedBolt对于业务是有侵入的,要使用CoordinatedBolt提供的功能,你必须要保证每个Bolt发送的每个tuple的第一个field是
request-id,这个request-id在DRPC中表示一个DRPC请求;在Transactional Topology表示一个Batch.
设计3:Storm设计
Storm的设计,把batch的处理分为两个阶段:
- a. 处理阶段(Process Phase):处理阶段,可以并行处理batch
- b.提交阶段(Commit Phase):在提交阶段,Batch之间顺序是严格有序的。(第一个batch提交前,第二个batch不允许提交)
处理阶段和提交阶段和在一起被称为一个“事务”,包含“事务”处理逻辑的拓扑称为“事务拓扑”。如果一个batch在处理阶段或提交阶段有任何错误,则整个事务必须重新执行。
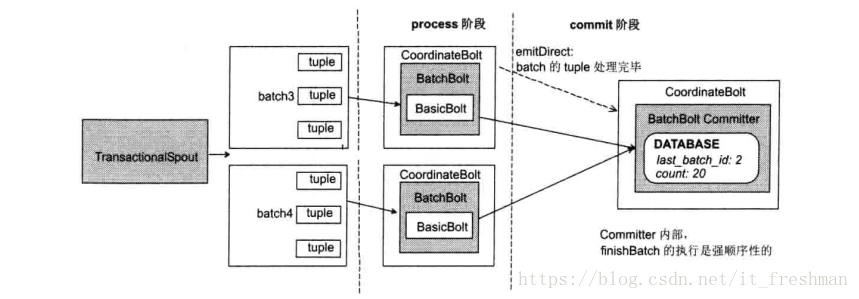
事务拓扑设计细节
如果使用事务拓扑,Storm会自动处理如下事情:
- 管理状态:Storm在Zookeeper中保存执行事务拓扑的所有状态,状态包括事务id,每个batch中的元数据等。
- 协调事务:Storm管理所有需要决策的事情。如:在适当的时候处理或提交适当的事务。
- 故障检测:当一个batch处理失败,Storm会在适当的时候重发batch,不必做任何的ack或anchor工作,storm为你管理一切。
- 封装批处理API: Storm在普通bolt上封装API,支持元组的批处理,当任务已收到特定事务的所有元组,Storm协调所有工作。Storm为每个事务清理产生的中间数据。
事务Bolt
在事务拓扑中存在3种类型的Bolt.
- BasicBolt: 它不能处理Batch,只能在
execute处理单个输入元组,并在处理完成之后,发射新的元组。 - BatchBolt: 它可以处理元组Batch.Batch中的每个元组都会调用
execute方法,当Batch处理完成时(即接收到所有元组),会调用finishBatch方法 - 标记为
Committer的BatchBolt: 和普通的BatchBolt的区别是调用finishBatch的时机,它只有在提交阶段才会调用finishBatch。当前Batch所有前置Batch提交之后,本Batch才可以提交,期间它会不听重试。
使BatchBolt变为Committer BatchBolt方法
- 实现ICommitter接口
2.TransactionalTopologyBuilder.setCommitterBolt(String id, IBatchBolt bolt) 将普通BatchBolt转换为Committer BatchBolt。
Bolt特性:
- Acking:使用事务拓扑时,不必考虑Acking和Achoring机制,Storm会管理底层操作。
- 事务失败:它提供了一个不同的机制处理一个Batch的失败,重发该失败Batch,并抛出一个FailedException异常。
事务Spout
TransactionalSpout接口完全不同于普通的Spout接口,TransactionalSpout实现发射处理一批元组,并保证相同事务id总是发射相同元组的Batch.
- 事务Spout是一个包含
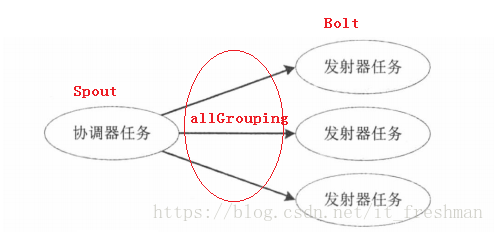
协调器Spout(并行度1)和发射器Bolt(并行度P)的子拓扑。
- 协调器是一个普通的Spout,并行度为1.不断发送Batch中的元组。
- 发射器是一个并行度为P的Bolt,使用一个广播分组连接到协调器
batch-emit流(元组的发射是幂等的) - 当协调器决定进入事务处理阶段,它发射包含
TransactionAttempt和事务元数据元组到batch流 - 由于是广播分组,每一个发射器任务都会接收到通知,来进行
finishBatch的尝试。 - 如果处理阶段成功,且该batch之前的所有batch都已经提交,协调器会发射包含
TransactionAttempt的元组到commit流。 - 所有提交Bolt使用广播订阅commit流,当提交发生时都会收到一个通知,来进行
finishBatch的尝试。 - 由于根元组是协调器创建的,所以Storm自动管理整个拓扑必要的acking和anchoring是通过协调器的ack和fail实现的。
public class TransactionalGlobalCount {
//略......
public static void main(String[] args) throws InterruptedException {
/**DATA : 从内存中读取数据并对数据来源进行分区
* PARTITION_TAKE_PER_BATCH 每批分组中从每个分区发射的最大元组数量
*/
MemoryTransactionalSpout spout = new MemoryTransactionalSpout(DATA, new Fields("word"),PARTITION_TAKE_PER_BATCH);
/**
* id: 用来在zookeeper中,保存当前topology的进度,如果这个topology重启, 则可以继续之前的进度执行。
* spoutId
* TransactionalSpout: 一个Transactional topology有且仅能只有一个TransactionalSpout
* TransactionalSpout的并行度
*/
TransactionalTopologyBuilder builder = new TransactionalTopologyBuilder("global-count", "spout", spout, 3);
builder.setBolt("partial-count", new BatchCount()).noneGrouping("spout");
builder.setBolt("sum", new UpdateGlobalCount()).globalGrouping("partial-count");
LocalCluster cluster = new LocalCluster();
Config config = new Config();
config.setDebug(true);
//一次允许的活跃batch数量
// config.setMaxSpoutPending(3);
cluster.submitTopology("global-count-topology", config, builder.buildTopology());
Thread.sleep(20000);
cluster.shutdown();
}
}