Storm 好像传统的滚梯,来了数据就处理
Hadoop好像是电梯,批量处理数据
Spark streaming 微批处理介于滚梯和电梯之间
Storm 特征
storm 是个实时的,分布式的以及高容错的计算框架
1 storm 常驻内存
2 storm几乎不经过硬盘,在内存中处理
下面通过官方拓扑图理解下

看图说话
1 水龙头 spout 数据的源头
2 水滴 tuple 中文 元组 相当于关系型数据库里的一行数据 es里的doc java里的object
在storm里代表storm架构处理数据的最小单位
3 水滴加闪电 在storm 里 代表一个bolt(雷电) (component元件) 一个处理单元
spout vs bolt 1 vs n
4 从图中我们还可以知道这是一个DAG图,directed acyclic grapth 有向无环图
Storm架构 (主从)
1 Nimbus (老板) 相当于hadoop的namenode
任务分配,资源调度
2 Supervisor (监工) 相当于hadoop的datanode
指派老板分配下来的任务,通过开启关闭工作进程的方式
3 worker (工人) 具体干活的进程
数据传输
结点间通讯采用技术
1 ZMQ
twitter早期产品 zero message queue 开源的消息传递框架 后来发现有bug不用了
2 Netty
netty是一种基于nio的网络框架,更加高效,storm0.9后使用Netty,其实也是一种消息队列
高可靠性
1 异常处理
2 消息可靠性保障机制 ACKER机制
可维护性
Storm ui 图形化监控接口
Storm 流式处理
异步的实时分析
例:计算PV、UV、访问热点 以及 某些数据的聚合、加和、平均等
客户端提交数据之后,计算完成结果存储到Redis、HBase、MySQL或者其他MQ当中,
客户端并不关心最终结果是多少。

同步是实时分析

客户端提交数据请求之后,立刻取得计算结果并返回给客户端,推荐系统
Storm 和 MapReduce区别
Storm:进程、线程常驻内存运行,数据不进入磁盘,数据通过网络传递。
MapReduce:为TB、PB级别数据设计的批处理计算框架。

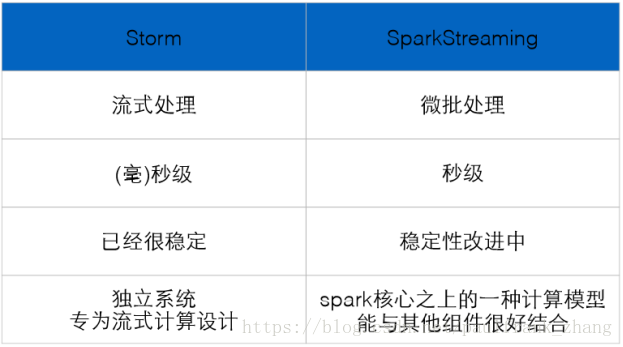
Storm 和 Spark Streaming 区别
Storm:纯流式处理
专门为流式处理设计
数据传输模式更为简单,很多地方也更为高效
并不是不能做批处理,它也可以来做微批处理,来提高吞吐
Spark Streaming:微批处理
将RDD做的很小来用小的批处理来接近流式处理
基于内存和DAG可以把处理任务做的很快
未完待续!!!!!