storm_day01学习笔记
1、目标
- 1、熟悉storm的相关概念
- 2、掌握搭建一个storm集群
- 3、掌握编写简单的storm应用程序
- 4、掌握storm的并行度设置
- 5、掌握storm的数据分发策略
- 6、掌握storm与kafka整合
2、storm概述
2.1 storm是什么
storm是由twitter公司开源,捐献apache基金会,是一个实时处理框架。
storm特点:来一条数据就处理一条,实时性比较高
sparkStreaming:并不是来一条数据就处理一条,以某一时间间隔的批量处理。实时性比较低,延迟比较高。
大数据技术分类:
(1)存储
hadoop--->HDFS HBASE
(2)计算
1、离线计算
mapreduce、hive、spark
2、实时计算
kafka+storm/sparkStreaming
辅助框架:flume日志收集、azkaban调度框架、sqoop数据的导入导出
编程模型简单
在大数据处理方面相信大家对hadoop已经耳熟能详,基于Google Map/Reduce来实现的Hadoop为开发者提供了map、reduce原语,使并行批处理程序变得非常地简单和优美。同样,Storm也为大数据的实时计算提供了一些简单优美的原语,这大大降低了开发并行实时处理的任务的复杂性,帮助你快速、高效的开发应用。可扩展
在Storm集群中真正运行topology的主要有三个实体:工作进程、线程和任务。Storm集群中的每台机器上都可以运行多个工作进程,每个工作进程又可创建多个线程,每个线程可以执行多个任务,任务是真正进行数据处理的实体,我们开发的spout、bolt就是作为一个或者多个任务的方式执行的。
因此,计算任务在多个线程、进程和服务器之间并行进行,支持灵活的水平扩展。高可靠性
Storm可以保证spout发出的每条消息都能被“完全处理”,这也是直接区别于其他实时系统的地方,如S4。
请注意,spout发出的消息后续可能会触发产生成千上万条消息,可以形象的理解为一棵消息树,其中spout发出的消息为树根,Storm会跟踪这棵消息树的处理情况,只有当这棵消息树中的所有消息都被处理了,Storm才会认为spout发出的这个消息已经被“完全处理”。如果这棵消息树中的任何一个消息处理失败了,或者整棵消息树在限定的时间内没有“完全处理”,那么spout发出的消息就会重发。
考虑到尽可能减少对内存的消耗,Storm并不会跟踪消息树中的每个消息,而是采用了一些特殊的策略,它把消息树当作一个整体来跟踪,对消息树中所有消息的唯一id进行异或计算,通过是否为零来判定spout发出的消息是否被“完全处理”,这极大的节约了内存和简化了判定逻辑,后面会对这种机制进行详细介绍。
这种模式,每发送一个消息,都会同步发送一个ack/fail,对于网络的带宽会有一定的消耗,如果对于可靠性要求不高,可通过使用不同的emit接口关闭该模式。
上面所说的,Storm保证了每个消息至少被处理一次,但是对于有些计算场合,会严格要求每个消息只被处理一次,幸而Storm的0.7.0引入了事务性拓扑,解决了这个问题,后面会有详述。高容错性
如果在消息处理过程中出了一些异常,Storm会重新安排这个出问题的处理单元。Storm保证一个处理单元永远运行(除非你显式杀掉这个处理单元)。
当然,如果处理单元中存储了中间状态,那么当处理单元重新被Storm启动的时候,需要应用自己处理中间状态的恢复。支持多种编程语言
除了用java实现spout和bolt,你还可以使用任何你熟悉的编程语言来完成这项工作,这一切得益于Storm所谓的多语言协议。多语言协议是Storm内部的一种特殊协议,允许spout或者bolt使用标准输入和标准输出来进行消息传递,传递的消息为单行文本或者是json编码的多行。
Storm支持多语言编程主要是通过ShellBolt, ShellSpout和ShellProcess这些类来实现的,这些类都实现了IBolt 和 ISpout接口,以及让shell通过java的ProcessBuilder类来执行脚本或者程序的协议。
可以看到,采用这种方式,每个tuple在处理的时候都需要进行json的编解码,因此在吞吐量上会有较大影响。支持本地模式
Storm有一种“本地模式”,也就是在进程中模拟一个Storm集群的所有功能,以本地模式运行topology跟在集群上运行topology类似,这对于我们开发和测试来说非常有用。高效
2.2 storm的架构模型
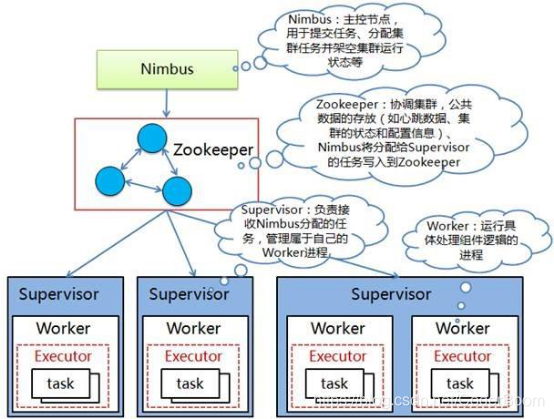
-
Nimbus
- 它是整个storm集群的老大,它负责资源的分配和任务的调度
-
zookeeper
- 整个storm集群搭建是需要一个zk集群
- zk集群作用
- 1、通过引入zk之后,保证storm集群的高可用
- 2、通过zk保存storm集群的元数据信息
- zk集群作用
- 整个storm集群搭建是需要一个zk集群
-
Supervisor
- 它是整个storm集群的小弟,它会负责任务的计算,也就是说它就是计算节点
-
Worker
- 它就是一个进程,它会在计算节点来启动对应的进程,后期任务就在该进程中运行
-
Executor
- 它就是具体任务,它是通过一个线程去运行
-
task
- 就是具体任务的名称,它会运行在worker进程中。
3、storm集群的安装部署
-
1、下载对应版本的安装包
- storm.apache.org
- https://archive.apache.org/dist/storm/apache-storm-1.1.1/apache-storm-1.1.1.tar.gz
- apache-storm-1.1.1.tar.gz
-
2、规划安装目录
- /export/servers
-
3、上传安装包到服务器中
-
4、解压安装包到指定的规划目录
- tar -zxvf apache-storm-1.1.1.tar.gz -C /export/servers
-
5、重命名解压目录
- mv apache-storm-1.1.1 storm
-
6、修改配置文件
-
进入到storm的安装目录conf文件夹
-
vim storm.yaml -
注意 : 修改的时候前面不要有空格
#指定storm需要依赖的zk服务地址(storm前面不要有空格) storm.zookeeper.servers: - "node-1" - "node-2" - "node-3" #指定哪些节点是老大Nimbus(nimbus前面不要有空格) nimbus.seeds: ["node-1", "node-2", "node-3"] #指定storm存放数据的本地目录(storm前面不要有空格) storm.local.dir: "/export/servers/storm/stormdata" #指定storm的web服务端口(ui前面不要有空格) ui.port: 8008 #指定每一个supervisor对应worker进程号(supervisor前面不要有空格) supervisor.slots.ports: - 6700 - 6701 - 6702 - 6703
-
-
-
7、配置storm的环境变量
-
vim /etc/profile
export STORM_HOME=/export/servers/storm export PATH=$PATH:$STORM_HOME/bin
-
-
8、分发storm安装目录和环境变量
scp -r storm node-2:/export/servers scp -r storm node-3:/export/servers scp /etc/profile node-2:/etc scp /etc/profile node-3:/etc -
9、让所有storm节点的环境变量生效
- 在所有节点执行
source /etc/profile
- 在所有节点执行
4、storm集群的启动和停止
-
1、前提条件
- 先启动zk集群
-
2、启动storm集群
-
(1) 在node1上启动服务
#启动nimbus nohup storm nimbus > /dev/null 2>&1 & #启动supervisor nohup storm supervisor > /dev/null 2>&1 & #启动 ui nohup storm ui > /dev/null 2>&1 & #启动日志服务logviewer nohup storm logviewer > /dev/null 2>&1 & -
(2)在node2上启动服务
#启动nimbus nohup storm nimbus > /dev/null 2>&1 & #启动supervisor nohup storm supervisor > /dev/null 2>&1 & #启动 ui nohup storm ui > /dev/null 2>&1 & #启动日志服务logviewer nohup storm logviewer > /dev/null 2>&1 & -
(3)在node3上启动服务
#启动nimbus nohup storm nimbus > /dev/null 2>&1 & #启动supervisor nohup storm supervisor > /dev/null 2>&1 & #启动 ui nohup storm ui > /dev/null 2>&1 & #启动日志服务logviewer nohup storm logviewer > /dev/null 2>&1 & -
如果storm集群节点非常多,需要再每一台集群都来启动这些脚本,比较麻烦,可以写一个一键启动storm脚本
#!/bin/sh nohup /export/servers/storm/bin/storm ui >/dev/null 2>&1 & for host in node-1 node-2 node-3 do ssh $host "source /etc/profile;nohup /export/servers/storm/bin/storm nimbus >/dev/null 2>&1 & nohup / export/servers/storm/bin/storm supervisor >/dev/null 2>&1 &" echo "$host storm is running" done
-
-
3、创建storm停止所有相关进程脚本
-
storm集群没有封装这种关闭脚本,没有特别好的办法,只能够一个一个的kill掉
-
可以模仿之前kafka集群停止脚本来写一个storm的一键关闭脚本 , 在每个机器的/export/servers/storm/bin创建storm-server-stop.sh
-
vim storm-server-stop.sh#!/bin/sh p1=$(ps ax | grep -i 'nimbus' | grep -v grep | awk '{print $2}') p2=$(ps ax | grep -i 'supervisor' | grep -v grep | awk '{print $2}') p3=$(ps ax | grep -i 'logviewer' | grep -v grep | awk '{print $2}') p4=$(ps ax | grep -i 'storm.ui.core' | grep -v grep | awk '{print $2}') for pid in {$p1,$p2,$p3,$p4} do if [ -z "$pid" ]; then exit 1 else kill -s TERM $pid fi done -
在node-1 下创建一键关闭storm所有进程脚本
-
vim stop-storm.sh
#!/bin/sh for host in node-1 node-2 node-3 do ssh $host "source /etc/profile;/export/servers/storm/bin/storm-server-stop.sh" echo "$host storm is stop" done -
5、storm的web管理界面
- 启动ui服务
- 主机名:8008
6、storm的编程模型
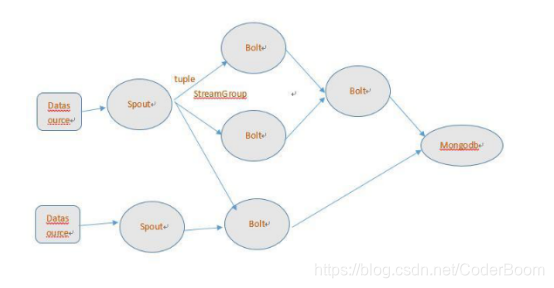
-
1、DataSource
- 就是外部的数据源
-
2、Spout
- 它会对接外部数据源,然后把接受到的数据发给下游bolt
-
3、Bolt
- 它会接受到上游发送的数据,然后进行一定的逻辑处理,最后可以把数据发送给下游bolt或者是把数据进行持久化保存
-
4、tuple
- 它是storm数据传输的最小单元,封装了每一条数据,它内部有List集合,集合中存放对应的数据
-
5、topology
- 它是storm实时计算的应用程序,它会把spout和bolt进行组装,最后组合成一个topology
-
后期开发storm程序就是就编写一个Spout逻辑和很多个Bolt逻辑,最后把这些逻辑组装在一起,组成一个storm的实时计算应用程序-------->topology
spout----->bolt----->bolt------>bolt----->bolt------>保存
7、storm的wordcount程序案例
图解
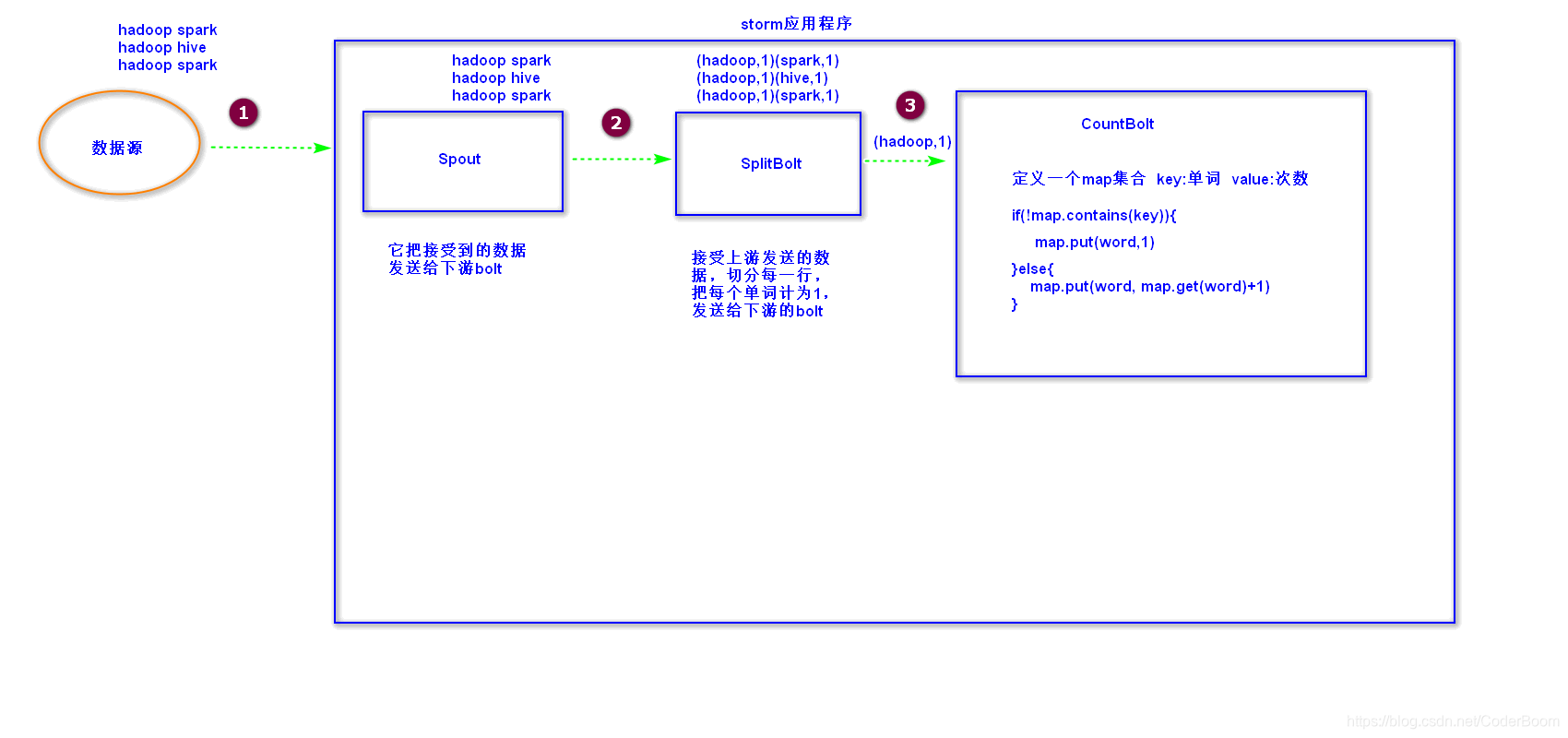
7.1、构建maven工程,引入依赖
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>1.1.1</version>
<scope>provided</scope>
</dependency>
7.2 RandomSpout代码开发
package cn.itcast.wordcount;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values;
import java.util.Map;
import java.util.Random;
//todo:定义一个Spout,后期把数据发送给下游的bolt
public class RandomSpout extends BaseRichSpout{
//通过collector向下游发送数据
private SpoutOutputCollector collector;
private Random random;
private String[] lines;
/**
* 它是一个初始化的方法,它会被执行一次
* @param conf 就是一个map集合
* @param context 是一个上下文对象
* @param collector 可以通过该对象在nextTuple 方法中把对应的数据发送给下游
*/
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector=collector;
this.random=new Random();
this.lines=new String[]{"hadoop spark","hadoop hive"};
}
/**
* 该方法可以实现数据的不断发送
*/
@Override
public void nextTuple() {
//随机向下游发送数据
int index = random.nextInt(lines.length);
String line = lines[index];
//调用 collector有一个emit发送数据的方法,需要一个list集合,storm中自己封装一个类型Values,它是继承自ArrayList
collector.emit(new Values(line));
}
/**
* 在给下游发送数据的时候,可以给数据一个声明,后期下游可以通过这个声明来获取上游的数据
* @param declarer
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
//发送数据的时候,需要给数据一个声明,声明就是一个字段data,下游后期就可以通过data字段获取上游发送的数据
declarer.declare(new Fields("data"));
}
}
7.3 SplitBolt 代码开发
package cn.itcast.wordcount;
import org.apache.storm.topology.BasicOutputCollector;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseBasicBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
//todo:接受上游Spout发送的数据,然后进行切分,把个单词计为1 发送给下游的bolt
public class SplitBolt extends BaseBasicBolt {
/**
*
* @param input 封装了上游发送的数据,获取可以操作它获取上游数据
* @param collector 把结果数据发送出去
*/
@Override
public void execute(Tuple input, BasicOutputCollector collector) {
String data = input.getStringByField("data");
String[] words = data.split(" ");
for (String word : words) {
//把结果数据封装一下,发送给下游
collector.emit(new Values(word,1));
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
//由于发送的数据是2个结果,这里就需要声明2个字段,一一对应
declarer.declare(new Fields("word","num"));
}
}
7.4 CountBolt代码开发
package cn.itcast.wordcount;
import org.apache.storm.topology.BasicOutputCollector;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseBasicBolt;
import org.apache.storm.tuple.Tuple;
import java.util.HashMap;
//todo:接受上游的bolt数据,实现单词统计逻辑
public class CountBolt extends BaseBasicBolt{
private HashMap<String,Integer> map=new HashMap<String,Integer>();
@Override
public void execute(Tuple input, BasicOutputCollector collector) {
String word = input.getStringByField("word");
Integer num = input.getIntegerByField("num");
if(!map.containsKey(word)){
map.put(word,1);
}else{
map.put(word,map.get(word)+1);
}
System.out.println(map);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
//它是最后一个处理逻辑,没有向下游去发送数据,这里就不需要做一些声明
}
}
7.5 WordCount驱动主类
package cn.itcast.wordcount;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.generated.AlreadyAliveException;
import org.apache.storm.generated.AuthorizationException;
import org.apache.storm.generated.InvalidTopologyException;
import org.apache.storm.topology.TopologyBuilder;
public class WordCount {
public static void main(String[] args) throws Exception {
//创建一个TopologyBuilder对象,后期组织spout和bolt
TopologyBuilder topologyBuilder = new TopologyBuilder();
//组织spout,需要一个id,唯一标识,还需要一个Spout
topologyBuilder.setSpout("randomSpout",new RandomSpout());
//组织bolt
topologyBuilder.setBolt("splitBolt",new SplitBolt()).shuffleGrouping("randomSpout");
topologyBuilder.setBolt("countBolt",new CountBolt()).shuffleGrouping("splitBolt");
Config config = new Config();
if(args !=null && args.length>0){
//集群模式提交
StormSubmitter.submitTopology(args[0],config,topologyBuilder.createTopology());
}else{
//本地模式提交
LocalCluster localCluster = new LocalCluster();
localCluster.submitTopology("wordcount",config,topologyBuilder.createTopology());
}
}
}
7.6 打成jar包提交到集群运行
storm jar storm_class14-1.0-SNAPSHOT.jar cn.itcast.wordcount.WordCount wordcount
8、storm的并行度
设置storm的并行度,就是去设置整个程序在运行的时候worker进程的个数和task线程个数
//设置randomSpout的task个数为3
topologyBuilder.setSpout("randomSpout",new RandomSpout(),3);
//组织bolt
topologyBuilder.setBolt("splitBolt",new SplitBolt(),3).shuffleGrouping("randomSpout");
topologyBuilder.setBolt("countBolt",new CountBolt(),3).shuffleGrouping("splitBolt");
Config config = new Config();
//设置worker的进程数,一个worker内部会开启一个内置的task线程,一共有3个worker,一共就新增3个线程
config.setNumWorkers(3);
9、storm的分发策略
- 就是spout与bolt、bolt与bolt之间的数据传输关系。
//storm的分发策略:
//一共有8种分发策略:
//1、shuffleGrouping 随机分发
// topologyBuilder.setBolt("splitBolt",new SplitBolt(),3).shuffleGrouping("randomSpout");
//2、fieldsGrouping 按照字段进行分组,相同的字段会进行入到同一个bolt中去处理
// topologyBuilder.setBolt("splitBolt",new SplitBolt(),3).fieldsGrouping("randomSpout",new Fields("hadoop"));
//3、allGrouping 广播分组,下游每一个bolt都会接受到上游的数据
// topologyBuilder.setBolt("splitBolt",new SplitBolt(),3).allGrouping("randomSpout");
//4、globalGrouping 全局分组,数据被发送到下游中task id最小的bolt中
// topologyBuilder.setBolt("splitBolt",new SplitBolt(),3).globalGrouping("randomSpout");
//5、noneGrouping:不分组,效果跟shuffleGrouping是一样
// topologyBuilder.setBolt("splitBolt",new SplitBolt(),3).noneGrouping("randomSpout");
//6、directGrouping 直接分组,可以指定数据流入到具体哪一个下游的task中
// topologyBuilder.setBolt("splitBolt",new SplitBolt(),3).directGrouping("randomSpout");
//7、localOrShuffleGrouping 本地或者随机分组,这里考虑了数据的本地性,减少数据的网络传输
topologyBuilder.setBolt("splitBolt",new SplitBolt(),3).localOrShuffleGrouping("randomSpout");
//8、自定义分组 customGrouping
详解 :
1)shuffleGrouping(随机分组)随机分组;将tuple随机分配到bolt中,能够保证各task中处理的数据均衡;
2)fieldsGrouping(按照字段分组,在这里即是同一个单词只能发送给一个Bolt)
按字段分组; 根据设定的字段相同值得tuple被分配到同一个bolt进行处理;
举例:builder.setBolt(“mybolt”, new MyStoreBolt(),5).fieldsGrouping(“checkBolt”,new Fields(“uid”));
说明:该bolt由5个任务task执行,相同uid的元组tuple被分配到同一个task进行处理;该task接收的元祖字段是mybolt发射出的字段信息,不受uid分组的影响。
该分组不仅方便统计而且还可以通过该方式保证相同uid的数据保存不重复(uid信息写入数据库中唯一);
3)allGrouping(广播发送,即每一个Tuple,每一个Bolt都会收到)广播发送:所有bolt都可以收到该tuple
4)globalGrouping(全局分组,将Tuple分配到task id值最低的task里面)全局分组:tuple被发送给bolt的同一个并且最小task_id的任务处理,实现事务性的topology
5)noneGrouping(随机分派)不分组:效果等同于shuffle Grouping.
6)directGrouping(直接分组,指定Tuple与Bolt的对应发送关系)
直接分组:由tuple的发射单元直接决定tuple将发射给那个bolt,一般情况下是由接收tuple的bolt决定接收哪个bolt发射的Tuple。这是一种比较特别的分组方法,用这种分组意味着消息的发送者指定由消息接收者的哪个task处理这个消息。 只有被声明为Direct Stream的消息流可以声明这种分组方法。而且这种消息tuple必须使用emitDirect方法来发射。消息处理者可以通过TopologyContext来获取处理它的消息的taskid (OutputCollector.emit方法也会返回taskid)。
7)Local or shuffle Grouping本地或者随机分组,优先将数据发送到本机的处理器executor,如果本机没有对应的处理器,那么再发送给其他机器的executor,避免了网络资源的拷贝,减轻网络传输的压力
8)customGrouping (自定义的Grouping)
10、storm整合kafka
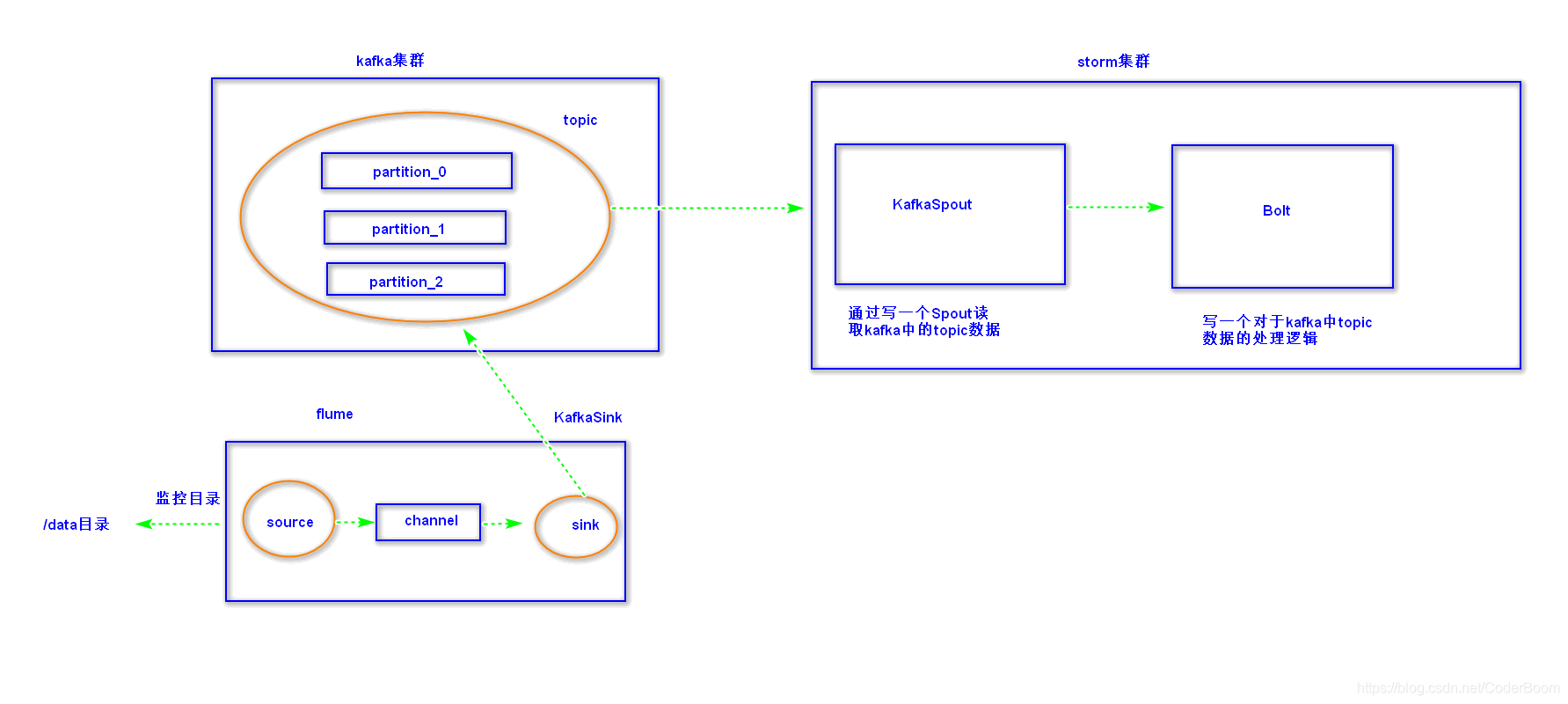
-
1、引入依赖
<!--添加storm与kafka的整合依赖 封装好了 KafkaSpout--> <dependency> <groupId>org.apache.storm</groupId> <artifactId>storm-kafka-client</artifactId> <version>1.1.1</version> </dependency> -
2、驱动主类开发
package cn.itcast.kafka; import org.apache.storm.Config; import org.apache.storm.LocalCluster; import org.apache.storm.StormSubmitter; import org.apache.storm.generated.AlreadyAliveException; import org.apache.storm.generated.AuthorizationException; import org.apache.storm.generated.InvalidTopologyException; import org.apache.storm.kafka.spout.KafkaSpout; import org.apache.storm.kafka.spout.KafkaSpoutConfig; import org.apache.storm.topology.TopologyBuilder; public class KafkaStormTopology { public static void main(String[] args) throws InvalidTopologyException, AuthorizationException, AlreadyAliveException { //1、创建TopologyBuilder 组织spout和bolt TopologyBuilder topologyBuilder = new TopologyBuilder(); //2、定义KafkaSpout KafkaSpoutConfig.Builder<String, String> builder = KafkaSpoutConfig.builder("node1:9092,node2:9092,node3:9092", "itcast"); //设置消费者组id builder.setGroupId("storm"); //设置从哪个位置去消费数据 指定消费的策略:从最后未消费的偏移量开始读取数据 builder.setFirstPollOffsetStrategy(KafkaSpoutConfig.FirstPollOffsetStrategy.UNCOMMITTED_LATEST); KafkaSpoutConfig<String, String> kafkaSpoutConfig = builder.build(); //构建KafkaSpout KafkaSpout<String, String> kafkaSpout = new KafkaSpout<>(kafkaSpoutConfig); //2、组织spout和bolt topologyBuilder.setSpout("kafkaSpout",kafkaSpout); topologyBuilder.setBolt("kafkaBolt",new KafkaBolt()).shuffleGrouping("kafkaSpout"); Config config = new Config(); if(args !=null && args.length>0){ //集群提交任务 StormSubmitter.submitTopology(args[0],config,topologyBuilder.createTopology()); }else{ //本地运行 LocalCluster localCluster = new LocalCluster(); localCluster.submitTopology("kafka-storm",config,topologyBuilder.createTopology()); } } } -
3、kafkaBolt开发
package cn.itcast.kafka; import org.apache.storm.topology.BasicOutputCollector; import org.apache.storm.topology.OutputFieldsDeclarer; import org.apache.storm.topology.base.BaseBasicBolt; import org.apache.storm.tuple.Tuple; import java.util.List; //todo:接受kafkaSpout中的数据,然后进行处理 public class KafkaBolt extends BaseBasicBolt{ @Override public void execute(Tuple input, BasicOutputCollector collector) { List<Object> values = input.getValues(); //获取topic中的真实数据,在list集合中下标为4 Object message1 = values.get(4); //直接从tuple中获取topic中的数据 String message2 = input.getString(4); System.out.println("message1:"+message1+" message2:"+message2); } @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { } }
11、实时看板案例
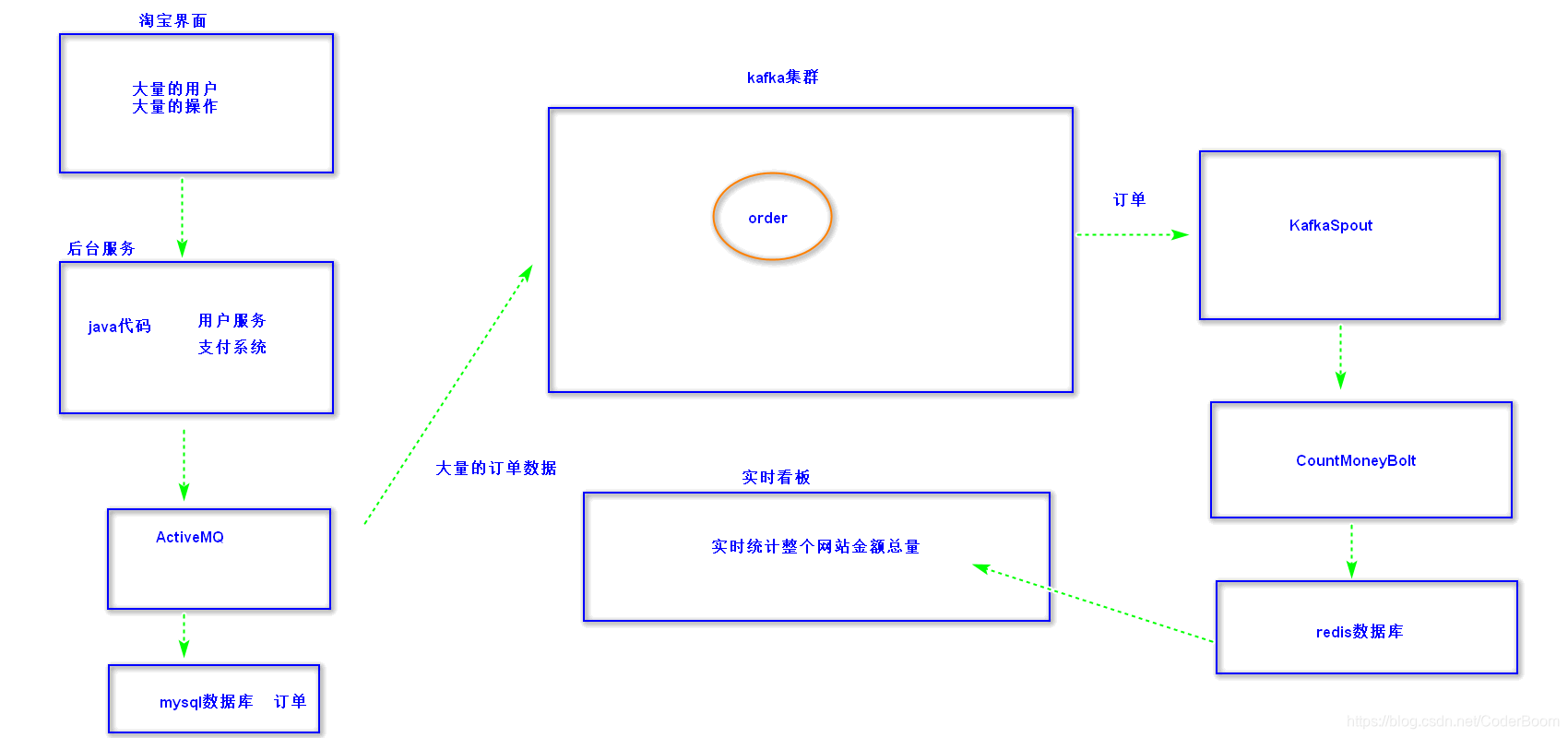
-
1、引入依赖
<dependency> <groupId>org.apache.storm</groupId> <artifactId>storm-core</artifactId> <version>1.1.1</version> <!--编译时需要,打包的时候不需要--> <!--<scope>provided</scope>--> </dependency> <!--添加storm与kafka的整合依赖 封装好了 KafkaSpout--> <dependency> <groupId>org.apache.storm</groupId> <artifactId>storm-kafka-client</artifactId> <version>1.1.1</version> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.41</version> </dependency> <dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>2.9.0</version> </dependency> -
2、开发驱动主类
package cn.itcast.realBoard; import org.apache.storm.Config; import org.apache.storm.LocalCluster; import org.apache.storm.StormSubmitter; import org.apache.storm.generated.AlreadyAliveException; import org.apache.storm.generated.AuthorizationException; import org.apache.storm.generated.InvalidTopologyException; import org.apache.storm.kafka.spout.KafkaSpout; import org.apache.storm.kafka.spout.KafkaSpoutConfig; import org.apache.storm.topology.TopologyBuilder; public class KafkaStormOrderTopology { public static void main(String[] args) throws InvalidTopologyException, AuthorizationException, AlreadyAliveException { //1、创建TopologyBuilder 组织spout和bolt TopologyBuilder topologyBuilder = new TopologyBuilder(); //2、定义KafkaSpout KafkaSpoutConfig.Builder<String, String> builder = KafkaSpoutConfig.builder("node1:9092,node2:9092,node3:9092", "itcast_order"); //设置消费者组id builder.setGroupId("storm"); //设置从哪个位置去消费数据 指定消费的策略:从最后未消费的偏移量开始读取数据 builder.setFirstPollOffsetStrategy(KafkaSpoutConfig.FirstPollOffsetStrategy.UNCOMMITTED_LATEST); KafkaSpoutConfig<String, String> kafkaSpoutConfig = builder.build(); //构建KafkaSpout KafkaSpout<String, String> kafkaSpout = new KafkaSpout<>(kafkaSpoutConfig); //2、组织spout和bolt topologyBuilder.setSpout("kafkaSpout",kafkaSpout); topologyBuilder.setBolt("kafkaOrderBolt",new KafkaOrderBolt()).localOrShuffleGrouping("kafkaSpout"); Config config = new Config(); if(args !=null && args.length>0){ //集群提交任务 StormSubmitter.submitTopology(args[0],config,topologyBuilder.createTopology()); }else{ //本地运行 LocalCluster localCluster = new LocalCluster(); localCluster.submitTopology("kafka-order-storm",config,topologyBuilder.createTopology()); } } } -
2、开发Bolt处理逻辑
package cn.itcast.realBoard; import cn.itcast.realBoard.domain.PaymentInfo; import cn.itcast.realBoard.util.JedisUtil; import com.alibaba.fastjson.JSONObject; import org.apache.storm.topology.BasicOutputCollector; import org.apache.storm.topology.OutputFieldsDeclarer; import org.apache.storm.topology.base.BaseBasicBolt; import org.apache.storm.tuple.Tuple; import redis.clients.jedis.Jedis; //todo:接受kafkaSpout中的订单数据,然后统计对应的一些指标,最后把结果数据写入到redis中 public class KafkaOrderBolt extends BaseBasicBolt{ private Jedis jedis; @Override public void execute(Tuple input, BasicOutputCollector collector) { String orderMessage = input.getString(4); JSONObject jsonObject = new JSONObject(); PaymentInfo paymentInfo = jsonObject.parseObject(orderMessage, PaymentInfo.class); Jedis conn = JedisUtil.getConn(); /** 平台运维角度统计指标 */ // 平台总销售额度 // redisRowKey设计 itcast:order:total:price:date conn.incrBy("itcast:order:total:price:date",paymentInfo.getPayPrice()); // 平台今天下单人数 // redisRowKey设计 itcast:order:total:user:date conn.incr("itcast:order:total:user:date"); // 平台商品销售数量 // redisRowKey设计 itcast:order:total:num:date conn.incr("itcast:order:total:num:date"); /* 商品销售角度统计指标 */ // 每个商品的总销售额 // Redis的rowKey设计 itcast:order:productId:price:date conn.incrBy("itcast:order:"+paymentInfo.getProductId()+":price:date",paymentInfo.getPayPrice()); // 每个商品的购买人数 // Redis的rowKey设计 itcast:order:productId:user:date conn.incr("itcast:order:"+paymentInfo.getProductId()+":user:date"); // 每个商品的销售数量 // Redis的rowKey设计itcast:order:productId:num:date conn.incr("itcast:order:"+paymentInfo.getProductId() +":num:date"); //店铺销售角度统计指标 // 每个店铺的总销售额 // Redis的rowKey设计 itcast:order:shopId:price:date conn.incrBy("itcast:order:"+paymentInfo.getShopId()+":price:date",paymentInfo.getPayPrice()); // 每个店铺的购买人数 // Redis的rowKey设计itcast:order:shopId:user:date conn.incr("itcast:order:"+paymentInfo.getShopId()+":user:date"); // 每个店铺的销售数量 // Redis的rowKey设计itcast:order:shopId:num:date conn.incr("itcast:order:"+paymentInfo.getShopId()+":num:date"); conn.close(); } @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { } } -
3、用到的一些基础工具类
- 详细见资料