版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/bingdianone/article/details/85262697
Storm开发环境搭建
本地环境配置:
jdk: 1.8
windows: exe
linux/mac(dmg): tar ..... 把jdk指定到系统环境变量(~/.bash_profile)
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_121.jdk/Contents/Home
export PATH=$JAVA_HOME/bin:$PATH
source ~/.bash_profile
echo $JAVA_HOME
java -version
IDEA:
Maven: 3.3+
windows/linux/mac 下载安装包
tar .... -C ~/app
把maven指定到系统环境变量(~/.bash_profile)
export MAVEN_HOME=/Users/rocky/app/apache-maven-3.3.9
export PATH=$MAVEN_HOME/bin:$PATH
source ~/.bash_profile
echo $JAVA_HOME
mvn -v
调整maven依赖下载的jar所在位置: $MAVEN_HOME/conf/setting.xml
<localRepository>/Users/rocky/maven_repos</localRepository>
可以在官网看到最新的依赖
http://storm.apache.org/releases/1.2.2/Maven.html
在pom.xml中添加storm的maven依赖
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>1.2.2</version>
</dependency>
IDEA项目构建:
选择模板
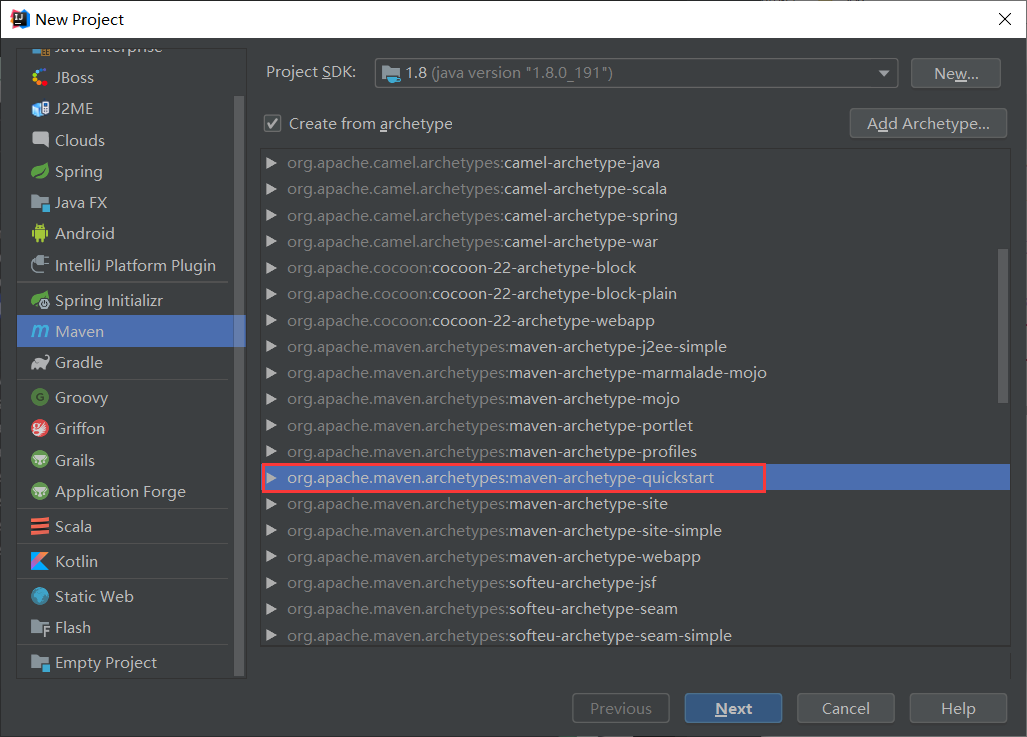
填写信息:下一步:点击next
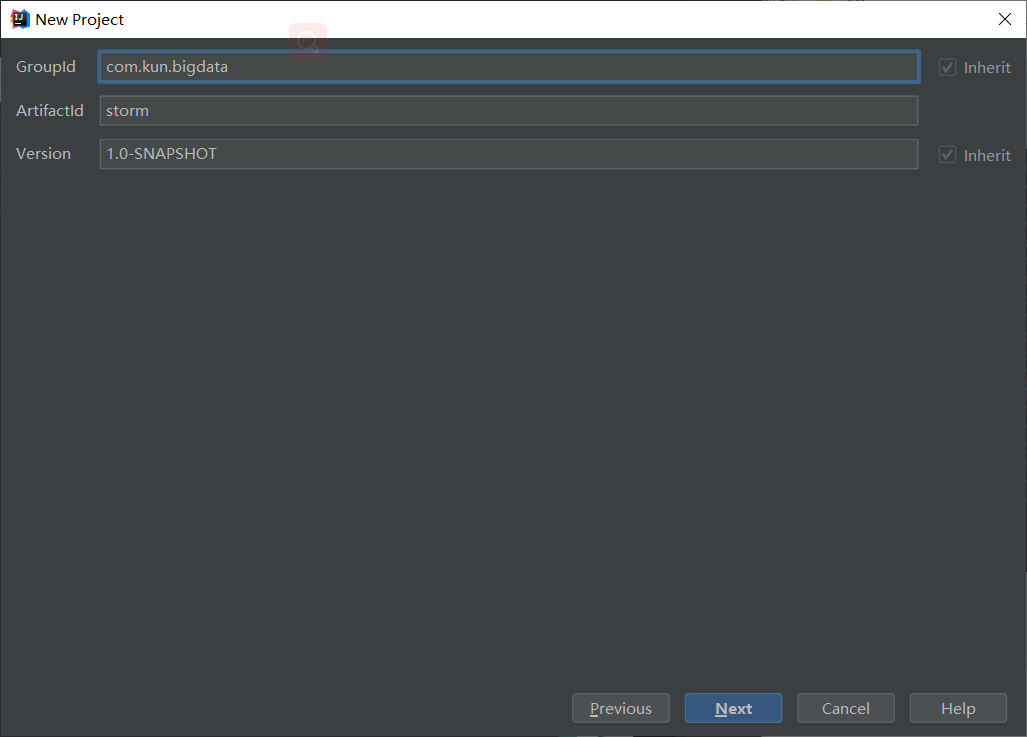
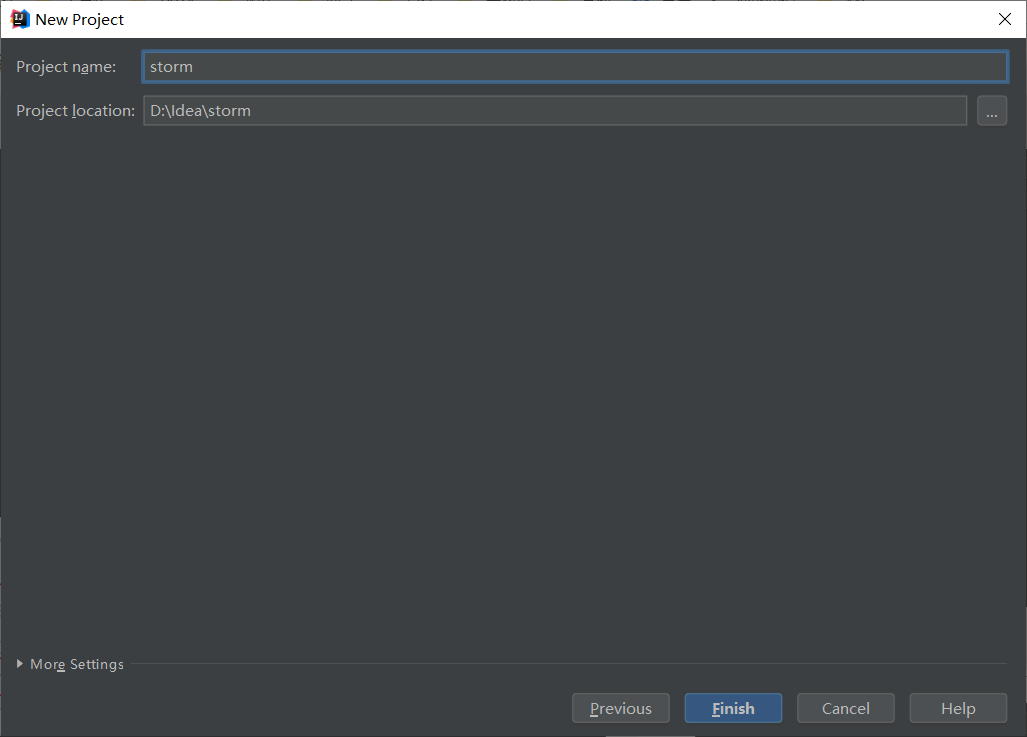
填写信息:下一步:点击next

下一步:点击finish完成
Storm核心接口
ISpout详解
概述
- 核心接口(interface),负责将数据发送到topology中去处理
- Storm会跟踪Spout发出去的tuple的DAG
- 调用ack/fail方法判断成功失败
- tuple: message id;当出现错误的时候id可以回传
- ack/fail/nextTuple是在同一个线程中执行的,所以不用考虑线程安全方面
核心方法
- open: 初始化操作
- close: 资源释放操作
- nextTuple: 发送数据 core api
- ack: tuple处理成功,storm会反馈给spout一个成功消息
- fail:tuple处理失败,storm会发送一个消息给spout,处理失败
实现类
- ctrl+alt+鼠标左键选择要打开的方法
public abstract class BaseRichSpout extends BaseComponent implements IRichSpout {
public interface IRichSpout extends ISpout, IComponent
DRPCSpout
ShellSpout
IComponent详解
概述:
public interface IComponent extends Serializable
为topology中所有可能的组件提供公用的方法
void declareOutputFields(OutputFieldsDeclarer declarer);
用于声明当前Spout/Bolt发送的tuple的名称
使用OutputFieldsDeclarer配合使用
实现类:
public abstract class BaseComponent implements IComponent
IBolt详解
概述
- 职责:接收tuple处理,并进行相应的处理(filter/join/…)
- hold住tuple再处理
- IBolt会在一个运行的机器上创建,使用Java序列化它,然后提交到主节点(nimbus)上去执行
- nimbus会启动worker来反序列化,调用prepare方法,然后才开始处理tuple处理
方法
- prepare:初始化
- execute:处理一个tuple数据,tuple对象中包含了元数据信息
- cleanup:shutdown之前的资源清理操作
实现类:
public abstract class BaseRichBolt extends BaseComponent implements IRichBolt {
public interface IRichBolt extends IBolt, IComponent
RichShellBolt
Storm求和案例编程
求和案例
需求:1 + 2 + 3 + … = ???
实现方案:
Spout发送数字作为input
使用Bolt来处理业务逻辑:求和
将结果输出到控制台
拓扑设计: DataSourceSpout --> SumBolt
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import org.apache.storm.utils.Utils;
import java.util.Map;
/**
* 使用Storm实现积累求和的操作
*/
public class LocalSumStormTopology {
/**Spout功能实现
* Spout需要继承BaseRichSpout
* 数据源需要产生数据并发射
*/
public static class DataSourceSpout extends BaseRichSpout {
private SpoutOutputCollector collector;
/**
* 初始化方法,只会被调用一次
* @param conf 配置参数
* @param context 上下文
* @param collector 数据发射器
*/
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
}
int number = 0;
/**
* 会产生数据,在生产上肯定是从消息队列中获取数据
*
* 这个方法是一个死循环,会一直不停的执行
*/
public void nextTuple() {
this.collector.emit(new Values(++number));
System.out.println("Spout: " + number);
// 防止数据产生太快
Utils.sleep(1000);
}
/**
* 声明输出字段
* @param declarer
*/
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("num"));
}
}
/**Bolt功能实现
* 数据的累积求和Bolt:接收数据并处理
*/
public static class SumBolt extends BaseRichBolt {
/**
* 初始化方法,会被执行一次
* @param stormConf
* @param context
* @param collector
*/
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
}
int sum = 0;
/**
* 其实也是一个死循环,职责:获取Spout发送过来的数据
* @param input
*/
public void execute(Tuple input) {
// Bolt中获取值可以根据index获取,也可以根据上一个环节中定义的field的名称获取(建议使用该方式)
Integer value = input.getIntegerByField("num");
sum += value;
System.out.println("Bolt: sum = [" + sum + "]");
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
public static void main(String[] args) {
// TopologyBuilder根据Spout和Bolt来构建出Topology
// Storm中任何一个作业都是通过Topology的方式进行提交的
// Topology中需要指定Spout和Bolt的执行顺序
//Topology功能实现
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("DataSourceSpout", new DataSourceSpout());
builder.setBolt("SumBolt", new SumBolt()).shuffleGrouping("DataSourceSpout");
// 创建一个本地Storm集群:本地模式运行,不需要搭建Storm集群
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("LocalSumStormTopology", new Config(),
builder.createTopology());
}
}
Storm词频案例编程
词频统计
需求:读取指定目录的数据,并实现单词计数功能
实现方案:
Spout来读取指定目录的数据,作为后续Bolt处理的input
使用一个Bolt把input的数据,切割开,我们按照逗号进行分割
使用一个Bolt来进行最终的单词的次数统计操作
并输出
拓扑设计: DataSourceSpout ==> SplitBolt ==> CountBolt
添加一个依赖
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.4</version>
</dependency>
import org.apache.commons.io.FileUtils;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import java.io.File;
import java.io.IOException;
import java.util.*;
/**
* 使用Storm完成词频统计功能
*/
public class LocalWordCountStormTopology {
public static class DataSourceSpout extends BaseRichSpout {
private SpoutOutputCollector collector;
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
}
/**
* 业务:
* 1) 读取指定目录的文件夹下的数据:D:/data/storm/wc
* 2) 把每一行数据发射出去
*/
public void nextTuple() {
// 获取所有文件
Collection<File> files = FileUtils.listFiles(new File("D:\\data\\storm\\wc"),
new String[]{"txt"},true);
for(File file : files) {
try {
// 获取文件中的所有内容
List<String> lines = FileUtils.readLines(file);
// 获取文件中的每行的内容
for(String line : lines) {
// 发射出去
this.collector.emit(new Values(line));
}
// TODO... 数据处理完之后,改名,否则一直重复执行
FileUtils.moveFile(file, new File(file.getAbsolutePath() + System.currentTimeMillis()));
} catch (IOException e) {
e.printStackTrace();
}
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("line"));
}
}
/**
* 对数据进行分割
*/
public static class SplitBolt extends BaseRichBolt {
private OutputCollector collector;
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
/**
* 业务逻辑:
* line: 对line进行分割,按照逗号
*/
public void execute(Tuple input) {
String line = input.getStringByField("line");
String[] words = line.split(",");
for(String word : words) {
this.collector.emit(new Values(word));
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
/**
* 词频汇总Bolt
*/
public static class CountBolt extends BaseRichBolt {
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
}
Map<String,Integer> map = new HashMap<String, Integer>();
/**
* 业务逻辑:
* 1)获取每个单词
* 2)对所有单词进行汇总
* 3)输出
*/
public void execute(Tuple input) {
// 1)获取每个单词
String word = input.getStringByField("word");
Integer count = map.get(word);
if(count == null) {
count = 0;
}
count ++;
// 2)对所有单词进行汇总
map.put(word, count);
// 3)输出
System.out.println("~~~~~~~~~~~~~~~~~~~~~~");
Set<Map.Entry<String,Integer>> entrySet = map.entrySet();
for(Map.Entry<String,Integer> entry : entrySet) {
System.out.println(entry);
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
public static void main(String[] args) {
// 通过TopologyBuilder根据Spout和Bolt构建Topology
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("DataSourceSpout", new DataSourceSpout());
builder.setBolt("SplitBolt", new SplitBolt()).shuffleGrouping("DataSourceSpout");
builder.setBolt("CountBolt", new CountBolt()).shuffleGrouping("SplitBolt");
// 创建本地集群
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("LocalWordCountStormTopology",
new Config(), builder.createTopology());
}
}
Storm编程注意事项
错误:
builder.setSpout("__DataSourceSpout", new DataSourceSpout());
builder.setBolt("__SplitBolt", new SplitBolt()).shuffleGrouping("DataSourceSpout");
builder.setBolt("__CountBolt", new CountBolt()).shuffleGrouping("SplitBolt");
不能以__双下划线开头
- Exception in thread “main” java.lang.IllegalArgumentException: Spout has already been declared for id DataSourceSpout
- org.apache.storm.generated.InvalidTopologyException: null
__是保留字段;不可以使用,否则会报上面两个错误 - topology的名称重复: local似乎没问题, 等到集群测试的时候再来验证这个问题(其实是有问题的)