版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/bingdianone/article/details/85599418
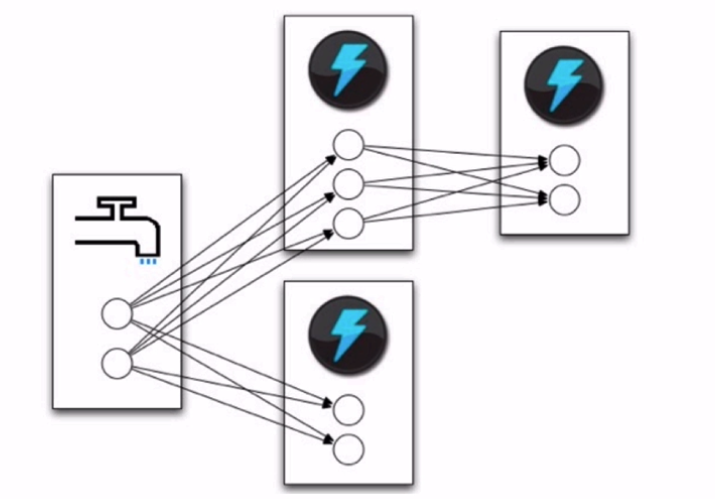
定义topology 的一部分是为每个bolt 指定它应该接收哪些Stream作为输入。Stream Grouping定义了如何在bolt的任务之间划分该Stream。
Storm中有8个内置的流分组,您可以通过实现 CustomStreamGrouping来实现自定义流分组:
- Shuffle grouping:元组(Tuples )在bolt的任务中是随机分布的,这样每个bolt都可以保证得到相等数量的元组。
- Fields grouping:根据分组中指定的字段对流进行分区。例如,如果流按“user-id”字段分组,那么具有相同“user-id”的元组将始终指向相同的任务,但是具有不同“user-id”的元组可能指向不同的任务。
- Partial Key grouping:流按照分组中指定的字段进行分区,就像字段分组一样,但是在两个下游bolt之间进行负载平衡,当传入数据倾斜时,可以更好地利用资源。本文很好地解释了它的工作原理及其优点。
- All grouping: 跨所有bolt任务复制流。小心使用这个分组。
- Global grouping: 整个流只用于bolt的一个任务。具体来说,它使用id最低的任务。
- None grouping:此分组指定您不关心流如何分组。目前,没有分组等同于洗牌分组。最终,Storm将按下没有分组的bolt,以便在与bolt相同的线程中执行,或者在可能的情况下,按下它们订阅的bolt。
- Direct grouping: 这是一种特殊的分组。以这种方式分组的流意味着元组的生产者将决定使用者的哪个任务将接收这个元组。直接分组只能在已声明为直接流的流上声明。向直接流发出的元组必须使用[emitDirect](javadocs/org/apache/storm/task/OutputCollector)之一发出。方法。bolt可以通过使用提供的TopologyContext或跟踪OutputCollector中emit方法的输出(该方法返回元组发送给它的任务id)来获得其使用者的任务id。
- Local or shuffle grouping:如果目标bolt在同一工作进程中有一个或多个任务,元组将被洗牌到那些进程内任务。否则,这就像一个普通的洗牌分组。
Shuffle grouping
元组(Tuples )在bolt的任务中是随机分布的,这样每个bolt都可以保证得到相等数量的元组。
import org.apache.storm.Config;
import org.apache.storm.StormSubmitter;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import org.apache.storm.utils.Utils;
import java.util.Map;
/**
* 使用Storm实现积累求和的操作
*/
public class ClusterSumShuffleGroupingStormTopology {
/**
* Spout需要继承BaseRichSpout
* 数据源需要产生数据并发射
*/
public static class DataSourceSpout extends BaseRichSpout {
private SpoutOutputCollector collector;
/**
* 初始化方法,只会被调用一次
* @param conf 配置参数
* @param context 上下文
* @param collector 数据发射器
*/
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
}
int number = 0;
/**
* 会产生数据,在生产上肯定是从消息队列中获取数据
*
* 这个方法是一个死循环,会一直不停的执行
*/
public void nextTuple() {
this.collector.emit(new Values(++number));
System.out.println("Spout: " + number);
// 防止数据产生太快
Utils.sleep(1000);
}
/**
* 声明输出字段
* @param declarer
*/
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("num"));
}
}
/**
* 数据的累积求和Bolt:接收数据并处理
*/
public static class SumBolt extends BaseRichBolt {
/**
* 初始化方法,会被执行一次
* @param stormConf
* @param context
* @param collector
*/
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
}
int sum = 0;
/**
* 其实也是一个死循环,职责:获取Spout发送过来的数据
* @param input
*/
public void execute(Tuple input) {
// Bolt中获取值可以根据index获取,也可以根据上一个环节中定义的field的名称获取(建议使用该方式)
Integer value = input.getIntegerByField("num");
sum += value;
System.out.println("Bolt: sum = [" + sum + "]");
System.out.println("Thread id: " + Thread.currentThread().getId() + " , rece data is : " + value);
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
public static void main(String[] args) {
// TopologyBuilder根据Spout和Bolt来构建出Topology
// Storm中任何一个作业都是通过Topology的方式进行提交的
// Topology中需要指定Spout和Bolt的执行顺序
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("DataSourceSpout", new DataSourceSpout());
builder.setBolt("SumBolt", new SumBolt(), 3).shuffleGrouping("DataSourceSpout");
// 代码提交到Storm集群上运行
String topoName = ClusterSumShuffleGroupingStormTopology.class.getSimpleName();
try {
StormSubmitter.submitTopology(topoName,new Config(), builder.createTopology());
} catch (Exception e) {
e.printStackTrace();
}
}
}
打包放到服务器测试
shuffleGrouping:
builder.setBolt("CountBolt", new CountBolt(),3).shuffleGrouping("SplitBolt");
随机分发到3个线程里。
FieldGrouping
根据分组中指定的字段对流进行分区。例如,如果流按“user-id”字段分组,那么具有相同“user-id”的元组将始终指向相同的任务,但是具有不同“user-id”的元组可能指向不同的任务。
import org.apache.storm.Config;
import org.apache.storm.StormSubmitter;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import org.apache.storm.utils.Utils;
import java.util.Map;
/**
* 使用Storm实现积累求和的操作
*/
public class ClusterSumFieldGroupingStormTopology {
/**
* Spout需要继承BaseRichSpout
* 数据源需要产生数据并发射
*/
public static class DataSourceSpout extends BaseRichSpout {
private SpoutOutputCollector collector;
/**
* 初始化方法,只会被调用一次
* @param conf 配置参数
* @param context 上下文
* @param collector 数据发射器
*/
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
}
int number = 0;
/**
* 会产生数据,在生产上肯定是从消息队列中获取数据
*
* 这个方法是一个死循环,会一直不停的执行
*/
public void nextTuple() {
this.collector.emit(new Values(number%2, ++number));
System.out.println("Spout: " + number);
// 防止数据产生太快
Utils.sleep(1000);
}
/**
* 声明输出字段
* @param declarer
*/
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("flag","num"));
}
}
/**
* 数据的累积求和Bolt:接收数据并处理
*/
public static class SumBolt extends BaseRichBolt {
/**
* 初始化方法,会被执行一次
* @param stormConf
* @param context
* @param collector
*/
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
}
int sum = 0;
/**
* 其实也是一个死循环,职责:获取Spout发送过来的数据
* @param input
*/
public void execute(Tuple input) {
// Bolt中获取值可以根据index获取,也可以根据上一个环节中定义的field的名称获取(建议使用该方式)
Integer value = input.getIntegerByField("num");
sum += value;
System.out.println("Bolt: sum = [" + sum + "]");
System.out.println("Thread id: " + Thread.currentThread().getId() + " , rece data is : " + value);
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
public static void main(String[] args) {
// TopologyBuilder根据Spout和Bolt来构建出Topology
// Storm中任何一个作业都是通过Topology的方式进行提交的
// Topology中需要指定Spout和Bolt的执行顺序
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("DataSourceSpout", new DataSourceSpout());
builder.setBolt("SumBolt", new SumBolt(), 3)
.fieldsGrouping("DataSourceSpout", new Fields("flag"));
// 代码提交到Storm集群上运行
String topoName = ClusterSumFieldGroupingStormTopology.class.getSimpleName();
try {
StormSubmitter.submitTopology(topoName,new Config(), builder.createTopology());
} catch (Exception e) {
e.printStackTrace();
}
}
}
打包服务器测试
Fields grouping:
builder.setBolt("CountBolt", new CountBolt(),3).fieldsGrouping("SplitBolt");
只有两个线程在处理;因为是按照基数和偶数来分组的。
AllGrouping
跨所有bolt任务复制流。小心使用这个分组。
import org.apache.storm.Config;
import org.apache.storm.StormSubmitter;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import org.apache.storm.utils.Utils;
import java.util.Map;
/**
* 使用Storm实现积累求和的操作
*/
public class ClusterSumAllGroupingStormTopology {
/**
* Spout需要继承BaseRichSpout
* 数据源需要产生数据并发射
*/
public static class DataSourceSpout extends BaseRichSpout {
private SpoutOutputCollector collector;
/**
* 初始化方法,只会被调用一次
* @param conf 配置参数
* @param context 上下文
* @param collector 数据发射器
*/
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
}
int number = 0;
/**
* 会产生数据,在生产上肯定是从消息队列中获取数据
*
* 这个方法是一个死循环,会一直不停的执行
*/
public void nextTuple() {
this.collector.emit(new Values(++number));
System.out.println("Spout: " + number);
// 防止数据产生太快
Utils.sleep(1000);
}
/**
* 声明输出字段
* @param declarer
*/
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("num"));
}
}
/**
* 数据的累积求和Bolt:接收数据并处理
*/
public static class SumBolt extends BaseRichBolt {
/**
* 初始化方法,会被执行一次
* @param stormConf
* @param context
* @param collector
*/
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
}
int sum = 0;
/**
* 其实也是一个死循环,职责:获取Spout发送过来的数据
* @param input
*/
public void execute(Tuple input) {
// Bolt中获取值可以根据index获取,也可以根据上一个环节中定义的field的名称获取(建议使用该方式)
Integer value = input.getIntegerByField("num");
sum += value;
System.out.println("Bolt: sum = [" + sum + "]");
System.out.println("Thread id: " + Thread.currentThread().getId() + " , rece data is : " + value);
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
public static void main(String[] args) {
// TopologyBuilder根据Spout和Bolt来构建出Topology
// Storm中任何一个作业都是通过Topology的方式进行提交的
// Topology中需要指定Spout和Bolt的执行顺序
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("DataSourceSpout", new DataSourceSpout());
builder.setBolt("SumBolt", new SumBolt(), 3)
.allGrouping("DataSourceSpout");
// 代码提交到Storm集群上运行
String topoName = ClusterSumAllGroupingStormTopology.class.getSimpleName();
try {
StormSubmitter.submitTopology(topoName,new Config(), builder.createTopology());
} catch (Exception e) {
e.printStackTrace();
}
}
}
打包上传服务器
有几个task就会处理几次-会以副本的形式执行;每个线程都会处理同一个数。
这个分组其实没什么意义