循环神经网络实践
一、TensorFlow LSTM 有用的类和方法
- 本部分,我们将学习搭建 LSTM 层的主要方法和类,并且还会将其用在实例中。
- tf.nn.rnn_cell.BasicLSTMCell 类
- 这是一个最简单的 LSTM 循环神经网络的元胞,仅仅带一个遗忘门,而不带其他的新颖的特征,如窥视孔(peepholes)。窥视孔的作用在于让各种门可以观察到元胞的状态。参数如下:
- num_units: 整型变量,LSTM cell 的数目;
- forget_bias: 浮点型变量,偏差(默认为 1)。该参数作用于遗忘门,用于第一次迭代中减少信息的损失。
- activation: 是内部状态的损失函数(默认值为 tanh)。
- MultiRNNCell (RNNCell) 类
- 在本例中,我们会有多个元胞来记住历史信息,所以我们会级联式堆积多个元胞。因此,需要 MultiRNNCell 类,MultiRNNCell(cells,state_is_tuple=False) 这是它的构造函数,参数主要是 cells。这些 cell 是需要堆积的 RNNCell 类的实例。
- learn.ops.split_squeeze(dim,num_split,tensor_in)
- 这个函数对输入在某个维度上进行切割。输入一个张量,对该张量在 dim 维度上切割成 num_split 个其他维度数值一样的张量。
- dim: 该参数表示需要切割的维度
- num_split: 该参数表示分割数目
- tensor_in: 该参数是输入张量
二、循环神经网络应用实例
2.1 能量消耗、单变量时间序列数据预测
- 本例中,我们将解决一个回归问题。数据集是家庭某个时间范围内的电力消耗。由我们的常识可知,这种数据应该一定会存在某种规律(比如,因为要准备早餐和打开电脑,早上电量会上升,下午会少许下降,晚上,随着大家用电增加,数据又会上升,直到夜里,数据慢慢趋向 0,这样一直保持到第二天早上)
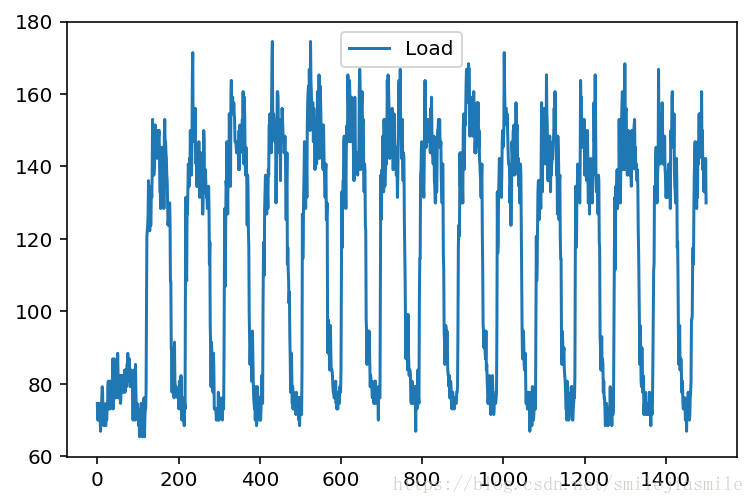
- 本例中,我们使用电力负荷数据集。每天采样 96(24 x 4) 次,这里为了简化模型,我们采用了一个客户完整的用电数据。第一步,将其读入程序,并且画出来,如下:
%matplotlib inline
%config InlineBackend.figure_formats = {'png','retina'}
import numpy as np
import pandas as pd
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow.python.framework import dtypes
from tensorflow.contrib import learn
from keras.models import Sequential
from keras.layers.core import Dense, Activation
from keras.layers.recurrent import LSTM
from keras.layers import Dropout
# 我们先取了前 1500 个样本,先观察一下数据
data = pd.read_csv('./elec_load.csv',error_bad_lines=False)
plt.subplot()
plot_test, = plt.plot(data.values[:1500],label='Load')
plt.legend(handles= [plot_test] )
# 从下面的图中可以大致看出,每 100 个采样呈现一个循环,这跟我们每天 96 个采样点吻合。<matplotlib.legend.Legend at 0x132055e10>
# 数据预处理
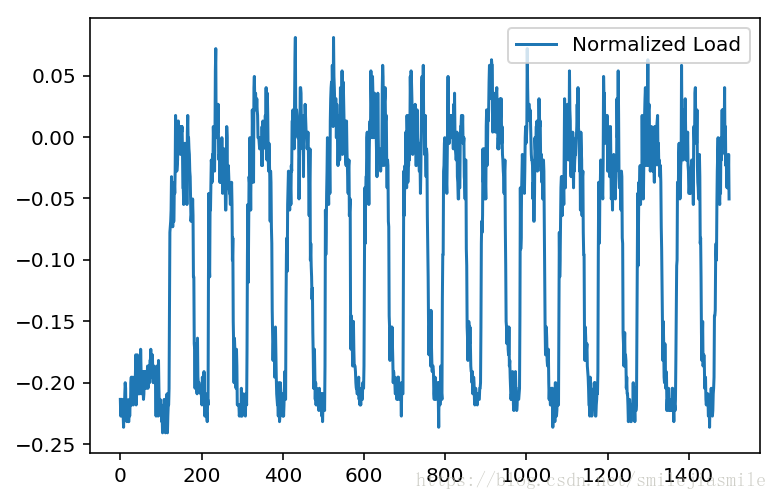
# 为了使得反向传播更加容易收敛,我们一般都会对数据进行正规化,
# 即放缩和数据中心化,即每个数据减去均值,并按照最大值进行缩放(将最大值限定到某个固定值,如 1)
# 通过 pandas.describe() 查看数据情况
print data.describe()
array = (data.values - 147.0) / 339.0
plt.subplot()
plot_test, = plt.plot(array[:1500],label='Normalized Load')
plt.legend(handles=[plot_test]) Load
count 140256.000000
mean 145.332503
std 48.477976
min 0.000000
25% 106.850998
50% 151.428571
75% 177.557604
max 338.218126
<matplotlib.legend.Legend at 0x12d0a2610>
# 构建数据集 (本例中,通过最近的 5 个值预测下一个值)
listX = []
listy = []
X = {}
y = {}
for i in range(0,len(array) - 6):
listX.append(array[i:i+5].reshape([5,1]))
listy.append(array[i+6])
arrayX = np.array(listX) # (140250, 5, 1)
arrayy = np.array(listy) # (140250, 1)
# 划分数据集
X['train']=arrayX[0:13000]
X['test']=arrayX[13000:14000]
y['train']=arrayy[0:13000]
y['test']=arrayy[13000:14000]
# 建立模型,使用了连接 10 个串联的 LSTM multicell,
# 每个 multicell 的输出都是一个线性回归
model = Sequential()
model.add(LSTM(input_dim=1,output_dim=50, return_sequences=True))
model.add(Dropout(0.2))
model.add(LSTM(input_dim=100,output_dim=200,return_sequences=False))
model.add(Dropout(0.2))
model.add(Dense(output_dim=1))
model.add(Activation('linear'))
model.compile(loss='mse',optimizer='rmsprop')
# Fit the model to the data
model.fit(X['train'],y['train'],batch_size=512,nb_epoch=10,validation_split=0.08)
test_results = model.predict(X['test'])
# Rescale the test dataset and predicted data
test_results = test_results * 339 + 147
y['test'] = y['test'] * 339 + 147 Train on 11960 samples, validate on 1040 samples
Epoch 1/10
11960/11960 [==============================] - 3s 218us/step - loss: 0.0032 - val_loss: 0.0022
Epoch 2/10
11960/11960 [==============================] - 1s 123us/step - loss: 0.0020 - val_loss: 0.0021
Epoch 3/10
11960/11960 [==============================] - 1s 119us/step - loss: 0.0018 - val_loss: 0.0019
Epoch 4/10
11960/11960 [==============================] - 1s 124us/step - loss: 0.0017 - val_loss: 0.0016
Epoch 5/10
11960/11960 [==============================] - 1s 122us/step - loss: 0.0016 - val_loss: 0.0014
Epoch 6/10
11960/11960 [==============================] - 1s 118us/step - loss: 0.0015 - val_loss: 0.0014
Epoch 7/10
11960/11960 [==============================] - 1s 115us/step - loss: 0.0014 - val_loss: 0.0013
Epoch 8/10
11960/11960 [==============================] - 1s 115us/step - loss: 0.0013 - val_loss: 0.0012
Epoch 9/10
11960/11960 [==============================] - 1s 115us/step - loss: 0.0013 - val_loss: 0.0011
Epoch 10/10
11960/11960 [==============================] - 1s 116us/step - loss: 0.0013 - val_loss: 0.0011
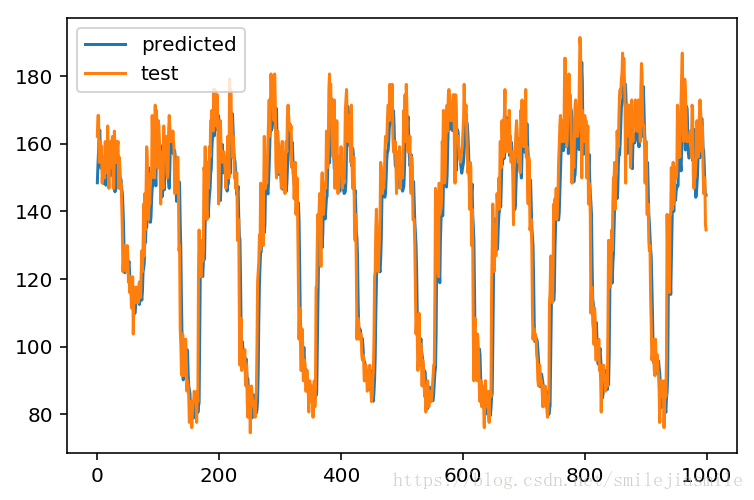
plt.subplot()
plot_predicted, = plt.plot(test_results,label='predicted')
plot_test, = plt.plot(y['test'],label='test')
plt.legend(handles= [plot_predicted,plot_test]) <matplotlib.legend.Legend at 0x1311b4b90>
2.2 基于 RNN 的创建巴赫风格的曲目
- 本例中,我们将循环网络用于字符序列,也称为字符 RNN 模型。
本例中,我们训练集是巴赫的哥德堡变奏曲,数据以字符的格式给出,通过将其输入网络,RNN 学习变奏曲的结构,最后基于学习到的结构谱出新的曲目。 - 字符级模型 :字符 RNN 模型可以处理字符序列。它的输入可以是各种语言,包括,程序代码,不同人的语言(用于建模某个作者的写作风格),科学论文 ( tex )等。
- 字符串序列和概率表示
- RNN 的输入需要一个清晰且直接的表示。一般针对这种情况,可以选择 one-hot 编码。这种编码方式对于输出的可能性是有限的情况(即分类情况),而字符输出正是这种情况。
- 使用字符对音乐编码 — > ABC 音乐格式
- 当我们寻求一种输入格式的时候,我们希望能够尽可能简单,又可以结构同质(structurally homogenerous)。在涉及到音乐格式时,我们发现 ABC 音乐格式,既结构简单,又只用可很少的字符,并且,这些都是 ASCII 字符集的子集。
ABC 格式的构成:由两部分构成,文件头和文件体。
- 文件头: 文件头包含多个键值对,如 X:【序号】,T:【歌曲名】,M:【拍号】,K:【调号】,C:【创始人】
- 文件体: 文件体紧接在文件头之后,包含每个小节的内容,每个小节之间用 “|” 字符分开。
数据集生成
- 由于,我们采用的是 ABC 格式来表示音乐的,故我们可以根据任何一个原始的 .abc 格式的音乐,然后按照下列代码,保存为 generate_dataset.py
# coding: utf-8
import random
input = open('original.txt','r').read().split('X:')
# print len(input)
for i in range(1,1000):
print 'X: ' + input[random.randint(1,6)] + '\n _____________________________\n'- 然后执行
python generate_dataset.py > input.txt之后就可以将其作为输入了。最后,在得到 .abc 格式的音乐字符后,可以到 这里,转换五线谱
源代码如下:
- 得到源代码后,应该先执行 python train.py –data_dir=’./’
- 然后执行 python sample.py
model.py
import tensorflow as tf
from tensorflow.contrib import rnn
from tensorflow.contrib import legacy_seq2seq
import numpy as np
class Model():
def __init__(self, args, training=True):
self.args = args
if not training:
args.batch_size = 1
args.seq_length = 1
if args.model == 'rnn':
cell_fn = rnn.BasicRNNCell
elif args.model == 'gru':
cell_fn = rnn.GRUCell
elif args.model == 'lstm':
cell_fn = rnn.BasicLSTMCell
elif args.model == 'nas':
cell_fn = rnn.NASCell
else:
raise Exception("model type not supported: {}".format(args.model))
cells = []
for _ in range(args.num_layers):
cell = cell_fn(args.rnn_size)
if training and (args.output_keep_prob < 1.0 or args.input_keep_prob < 1.0):
cell = rnn.DropoutWrapper(cell,
input_keep_prob=args.input_keep_prob,
output_keep_prob=args.output_keep_prob)
cells.append(cell)
self.cell = cell = rnn.MultiRNNCell(cells, state_is_tuple=True)
self.input_data = tf.placeholder(
tf.int32, [args.batch_size, args.seq_length])
self.targets = tf.placeholder(
tf.int32, [args.batch_size, args.seq_length])
self.initial_state = cell.zero_state(args.batch_size, tf.float32)
with tf.variable_scope('rnnlm'):
softmax_w = tf.get_variable("softmax_w",
[args.rnn_size, args.vocab_size])
softmax_b = tf.get_variable("softmax_b", [args.vocab_size])
embedding = tf.get_variable("embedding", [args.vocab_size, args.rnn_size])
inputs = tf.nn.embedding_lookup(embedding, self.input_data)
# dropout beta testing: double check which one should affect next line
if training and args.output_keep_prob:
inputs = tf.nn.dropout(inputs, args.output_keep_prob)
inputs = tf.split(inputs, args.seq_length, 1)
inputs = [tf.squeeze(input_, [1]) for input_ in inputs]
def loop(prev, _):
prev = tf.matmul(prev, softmax_w) + softmax_b
prev_symbol = tf.stop_gradient(tf.argmax(prev, 1))
return tf.nn.embedding_lookup(embedding, prev_symbol)
outputs, last_state = legacy_seq2seq.rnn_decoder(inputs, self.initial_state, cell, loop_function=loop if not training else None, scope='rnnlm')
output = tf.reshape(tf.concat(outputs, 1), [-1, args.rnn_size])
self.logits = tf.matmul(output, softmax_w) + softmax_b
self.probs = tf.nn.softmax(self.logits)
loss = legacy_seq2seq.sequence_loss_by_example(
[self.logits],
[tf.reshape(self.targets, [-1])],
[tf.ones([args.batch_size * args.seq_length])])
self.cost = tf.reduce_sum(loss) / args.batch_size / args.seq_length
with tf.name_scope('cost'):
self.cost = tf.reduce_sum(loss) / args.batch_size / args.seq_length
self.final_state = last_state
self.lr = tf.Variable(0.0, trainable=False)
tvars = tf.trainable_variables()
grads, _ = tf.clip_by_global_norm(tf.gradients(self.cost, tvars),
args.grad_clip)
with tf.name_scope('optimizer'):
optimizer = tf.train.AdamOptimizer(self.lr)
self.train_op = optimizer.apply_gradients(zip(grads, tvars))
# instrument tensorboard
tf.summary.histogram('logits', self.logits)
tf.summary.histogram('loss', loss)
tf.summary.scalar('train_loss', self.cost)
def sample(self, sess, chars, vocab, num=200, prime='The ', sampling_type=1):
state = sess.run(self.cell.zero_state(1, tf.float32))
for char in prime[:-1]:
x = np.zeros((1, 1))
x[0, 0] = vocab[char]
feed = {self.input_data: x, self.initial_state: state}
[state] = sess.run([self.final_state], feed)
def weighted_pick(weights):
t = np.cumsum(weights)
s = np.sum(weights)
return(int(np.searchsorted(t, np.random.rand(1)*s)))
ret = prime
char = prime[-1]
for n in range(num):
x = np.zeros((1, 1))
x[0, 0] = vocab[char]
feed = {self.input_data: x, self.initial_state: state}
[probs, state] = sess.run([self.probs, self.final_state], feed)
p = probs[0]
if sampling_type == 0:
sample = np.argmax(p)
elif sampling_type == 2:
if char == ' ':
sample = weighted_pick(p)
else:
sample = np.argmax(p)
else: # sampling_type == 1 default:
sample = weighted_pick(p)
pred = chars[sample]
ret += pred
char = pred
return ret- utile.py
import codecs
import os
import collections
from six.moves import cPickle
import numpy as np
class TextLoader():
def __init__(self, data_dir, batch_size, seq_length, encoding='utf-8'):
self.data_dir = data_dir
self.batch_size = batch_size
self.seq_length = seq_length
self.encoding = encoding
input_file = os.path.join(data_dir, "input.txt")
vocab_file = os.path.join(data_dir, "vocab.pkl")
tensor_file = os.path.join(data_dir, "data.npy")
if not (os.path.exists(vocab_file) and os.path.exists(tensor_file)):
print("reading text file")
self.preprocess(input_file, vocab_file, tensor_file)
else:
print("loading preprocessed files")
self.load_preprocessed(vocab_file, tensor_file)
self.create_batches()
self.reset_batch_pointer()
def preprocess(self, input_file, vocab_file, tensor_file):
with codecs.open(input_file, "r", encoding=self.encoding) as f:
data = f.read()
counter = collections.Counter(data)
count_pairs = sorted(counter.items(), key=lambda x: -x[1])
self.chars, _ = zip(*count_pairs)
self.vocab_size = len(self.chars)
self.vocab = dict(zip(self.chars, range(len(self.chars))))
with open(vocab_file, 'wb') as f:
cPickle.dump(self.chars, f)
self.tensor = np.array(list(map(self.vocab.get, data)))
np.save(tensor_file, self.tensor)
def load_preprocessed(self, vocab_file, tensor_file):
with open(vocab_file, 'rb') as f:
self.chars = cPickle.load(f)
self.vocab_size = len(self.chars)
self.vocab = dict(zip(self.chars, range(len(self.chars))))
self.tensor = np.load(tensor_file)
self.num_batches = int(self.tensor.size / (self.batch_size *
self.seq_length))
def create_batches(self):
self.num_batches = int(self.tensor.size / (self.batch_size *
self.seq_length))
# When the data (tensor) is too small,
# let's give them a better error message
if self.num_batches == 0:
assert False, "Not enough data. Make seq_length and batch_size small."
self.tensor = self.tensor[:self.num_batches * self.batch_size * self.seq_length]
xdata = self.tensor
ydata = np.copy(self.tensor)
ydata[:-1] = xdata[1:]
ydata[-1] = xdata[0]
self.x_batches = np.split(xdata.reshape(self.batch_size, -1),
self.num_batches, 1)
self.y_batches = np.split(ydata.reshape(self.batch_size, -1),
self.num_batches, 1)
def next_batch(self):
x, y = self.x_batches[self.pointer], self.y_batches[self.pointer]
self.pointer += 1
return x, y
def reset_batch_pointer(self):
self.pointer = 0
- train.py
from __future__ import print_function
import tensorflow as tf
import argparse
import time
import os
from six.moves import cPickle
from utils import TextLoader
from model import Model
def main():
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument('--data_dir', type=str, default='data/tinyshakespeare',
help='data directory containing input.txt')
parser.add_argument('--save_dir', type=str, default='save',
help='directory to store checkpointed models')
parser.add_argument('--log_dir', type=str, default='logs',
help='directory to store tensorboard logs')
parser.add_argument('--rnn_size', type=int, default=128,
help='size of RNN hidden state')
parser.add_argument('--num_layers', type=int, default=2,
help='number of layers in the RNN')
parser.add_argument('--model', type=str, default='lstm',
help='rnn, gru, lstm, or nas')
parser.add_argument('--batch_size', type=int, default=50,
help='minibatch size')
parser.add_argument('--seq_length', type=int, default=50,
help='RNN sequence length')
parser.add_argument('--num_epochs', type=int, default=50,
help='number of epochs')
parser.add_argument('--save_every', type=int, default=1000,
help='save frequency')
parser.add_argument('--grad_clip', type=float, default=5.,
help='clip gradients at this value')
parser.add_argument('--learning_rate', type=float, default=0.002,
help='learning rate')
parser.add_argument('--decay_rate', type=float, default=0.97,
help='decay rate for rmsprop')
parser.add_argument('--output_keep_prob', type=float, default=1.0,
help='probability of keeping weights in the hidden layer')
parser.add_argument('--input_keep_prob', type=float, default=1.0,
help='probability of keeping weights in the input layer')
parser.add_argument('--init_from', type=str, default=None,
help="""continue training from saved model at this path. Path must contain files saved by previous training process:
'config.pkl' : configuration;
'chars_vocab.pkl' : vocabulary definitions;
'checkpoint' : paths to model file(s) (created by tf).
Note: this file contains absolute paths, be careful when moving files around;
'model.ckpt-*' : file(s) with model definition (created by tf)
""")
args = parser.parse_args()
train(args)
def train(args):
data_loader = TextLoader(args.data_dir, args.batch_size, args.seq_length)
args.vocab_size = data_loader.vocab_size
# check compatibility if training is continued from previously saved model
if args.init_from is not None:
# check if all necessary files exist
assert os.path.isdir(args.init_from)," %s must be a a path" % args.init_from
assert os.path.isfile(os.path.join(args.init_from,"config.pkl")),"config.pkl file does not exist in path %s"%args.init_from
assert os.path.isfile(os.path.join(args.init_from,"chars_vocab.pkl")),"chars_vocab.pkl.pkl file does not exist in path %s" % args.init_from
ckpt = tf.train.get_checkpoint_state(args.init_from)
assert ckpt, "No checkpoint found"
assert ckpt.model_checkpoint_path, "No model path found in checkpoint"
# open old config and check if models are compatible
with open(os.path.join(args.init_from, 'config.pkl'), 'rb') as f:
saved_model_args = cPickle.load(f)
need_be_same = ["model", "rnn_size", "num_layers", "seq_length"]
for checkme in need_be_same:
assert vars(saved_model_args)[checkme]==vars(args)[checkme],"Command line argument and saved model disagree on '%s' "%checkme
# open saved vocab/dict and check if vocabs/dicts are compatible
with open(os.path.join(args.init_from, 'chars_vocab.pkl'), 'rb') as f:
saved_chars, saved_vocab = cPickle.load(f)
assert saved_chars==data_loader.chars, "Data and loaded model disagree on character set!"
assert saved_vocab==data_loader.vocab, "Data and loaded model disagree on dictionary mappings!"
if not os.path.isdir(args.save_dir):
os.makedirs(args.save_dir)
with open(os.path.join(args.save_dir, 'config.pkl'), 'wb') as f:
cPickle.dump(args, f)
with open(os.path.join(args.save_dir, 'chars_vocab.pkl'), 'wb') as f:
cPickle.dump((data_loader.chars, data_loader.vocab), f)
model = Model(args)
with tf.Session() as sess:
# instrument for tensorboard
summaries = tf.summary.merge_all()
writer = tf.summary.FileWriter(
os.path.join(args.log_dir, time.strftime("%Y-%m-%d-%H-%M-%S")))
writer.add_graph(sess.graph)
sess.run(tf.global_variables_initializer())
saver = tf.train.Saver(tf.global_variables())
# restore model
if args.init_from is not None:
saver.restore(sess, ckpt.model_checkpoint_path)
for e in range(args.num_epochs):
sess.run(tf.assign(model.lr,
args.learning_rate * (args.decay_rate ** e)))
data_loader.reset_batch_pointer()
state = sess.run(model.initial_state)
for b in range(data_loader.num_batches):
start = time.time()
x, y = data_loader.next_batch()
feed = {model.input_data: x, model.targets: y}
for i, (c, h) in enumerate(model.initial_state):
feed[c] = state[i].c
feed[h] = state[i].h
train_loss, state, _ = sess.run([model.cost, model.final_state, model.train_op], feed)
# instrument for tensorboard
summ, train_loss, state, _ = sess.run([summaries, model.cost, model.final_state, model.train_op], feed)
writer.add_summary(summ, e * data_loader.num_batches + b)
end = time.time()
print("{}/{} (epoch {}), train_loss = {:.3f}, time/batch = {:.3f}"
.format(e * data_loader.num_batches + b,
args.num_epochs * data_loader.num_batches,
e, train_loss, end - start))
if (e * data_loader.num_batches + b) % args.save_every == 0\
or (e == args.num_epochs-1 and
b == data_loader.num_batches-1):
# save for the last result
checkpoint_path = os.path.join(args.save_dir, 'model.ckpt')
saver.save(sess, checkpoint_path,
global_step=e * data_loader.num_batches + b)
print("model saved to {}".format(checkpoint_path))
if __name__ == '__main__':
main()- sample.py
from __future__ import print_function
import tensorflow as tf
import argparse
import os
from six.moves import cPickle
from model import Model
from six import text_type
def main():
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument('--save_dir', type=str, default='save',
help='model directory to store checkpointed models')
parser.add_argument('-n', type=int, default=500,
help='number of characters to sample')
parser.add_argument('--prime', type=text_type, default=u' ',
help='prime text')
parser.add_argument('-- ', type=int, default=1,
help='0 to use max at each timestep, 1 to sample at '
'each timestep, 2 to sample on spaces')
args = parser.parse_args()
sample(args)
def sample(args):
with open(os.path.join(args.save_dir, 'config.pkl'), 'rb') as f:
saved_args = cPickle.load(f)
with open(os.path.join(args.save_dir, 'chars_vocab.pkl'), 'rb') as f:
chars, vocab = cPickle.load(f)
model = Model(saved_args, training=False)
with tf.Session() as sess:
tf.global_variables_initializer().run()
saver = tf.train.Saver(tf.global_variables())
ckpt = tf.train.get_checkpoint_state(args.save_dir)
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess, ckpt.model_checkpoint_path)
print(model.sample(sess, chars, vocab, args.n, args.prime,
args.sample).encode('utf-8'))
if __name__ == '__main__':
main()