一.LSTM出现的背景(可不看)
首先来看它为什么叫做LSTM网络。
因为对于传统的RNN网络来说,它会出现的一个问题就是:它的Memory记忆的时间序列会比较短,比如说当你去翻译一句话的时候,你可能一次只能记住3个语境相关的单词,虽然我们设计的时候是有一个语境的buffer在里边,即使
我们的Memory会记住你的整个句子的语境,但是实际上做的时候就会发现它只能记住最近的那部分相关的语境
the clouds are in the sky
比如这里的是sky,它只能记住最近的几个单词, 对于前边的单词的语境它都忘记了。
LSTM的出现除了要解决梯度离散的问题,它还解决了传统RNN的记忆长度的问题,比如这里和你说一句很长很长的话,然后问你他问什么说法语,前边讲了说他是在法国长大的,所以如果你可以保持一个很长的记忆的话, 这句话就可以很容易的理解,解决掉。那也就是说LSTM它为什么这么命名的由来:我们知道RNN是有一个这样的Memory在的,叫做short-time-memory(是因为 它里边记录语境的h变量只能记录一些相近的相关的语义信息,所以叫做short-time-memorry),而LSTM的出现会将这里的Memory记忆的时间序列加长了,所以的话在前边添加一个long的意思就是说将其变长了。
二.LSTM是为了解决什么问题而出现的
- 解决梯度离散的问题
- 解决传统RNN的记忆长度的问题
三.回顾Simple RNN的结构
这里来回顾一下前边的RNN也就是short-time-memory的机制
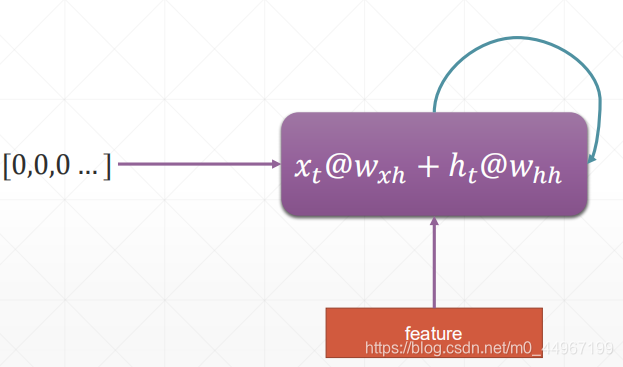
feature(当下时序的输入
)与原来的(上一个时序的)memory做一个结合,更新自己的memory (实际上一个单层的RNN网络只有一个单元,每次输入一个时序的数据,总结信息然后再循环传给自己,进入下一个时序…)

一般RNN的表示方式有两种,一种是像上图左端一样,一个单元加一个循环的符号,便于理解RNN的原理;还有一种,把它展开,将不同时序的运算过程都表示出来,便于理解RNN具体的运算过程。
下边使用另外一种方式来绘制SimpleRNN的表达图(在时间的维度上展开)
每一个相同的模块中,只有一个神经网络层:tanh。这里的
只能保持最近一段时间的memory
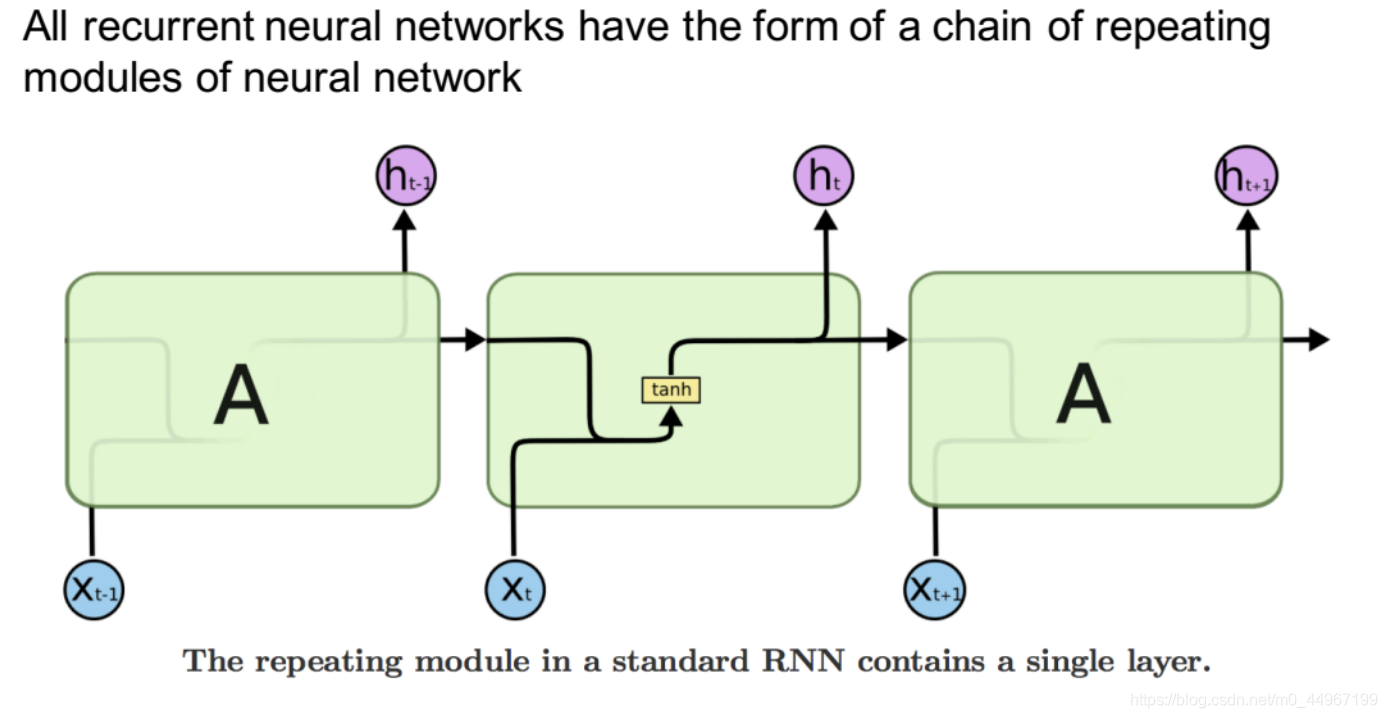
这里的 ,就是原始的RNN的表达方式。
四.LSTM的结构分析
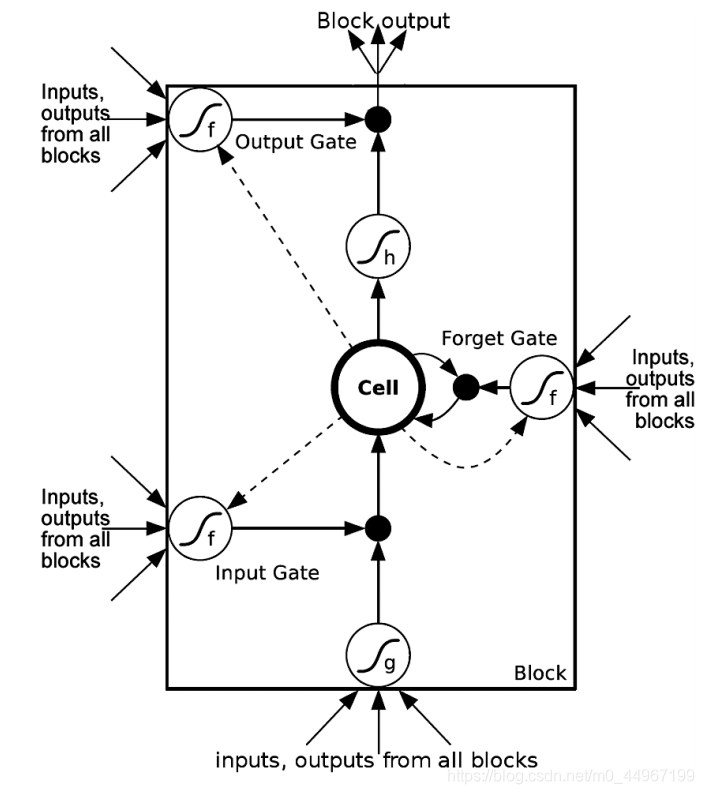
1.三道门外细节分析
接下来由此引出LSTM的结构
LSTM 的结构是这样引进来的:它有这样的一个初衷,对你原来的
,希望可以有一个闸门,可以让
的信息有目的性的过滤到下一个部分,同时对于新进来的信息,也有一道闸门也将信息有目的性的过滤进来。这两部分的信息进来以后进行一个结合,结合以后进行输出的时候,还是希望有一道闸门来控制你的信息的输出量,它就是这样的一个初衷,因此它设计了三道门。这里的三道门并不是我们生活中实物的门的概念,它其实是一个这样的概
,和
经过w以后再送到一个sigmoid激活函数(第一个门),这里将sigmoid函数生成的变量值近似为0和1,因此这个值就可以用来控制你的一个输出量,门中数值位置是1的部分,表示保留记忆的部分,而 其他不保留的则直接用当前的输入相应位置更新代替(这也是为什么要强调哪一部分和哪一部分的形状相同),这就是一个实现门机制的一个非常有效的方式,就是我们加一个w这样的tensor与你原来的信息做一个融合以后,通过一个sigmoid的激活函数,这样的话将sigmoid的输出量与你所要控制的量做一个乘积,这样的话就可以控制你输出的阈值,在这种做法下一共设置了3道门,这里的图中的三个σ 就表示三道门,即每一个激活函数就代表一道门分别控制了过去的信息 (这里的0/1控制门的开合,什么东西控制门的开度?)
Neural Network Layer :神经网络层
Pointwise Operation :
Vector Transfer:向量传输
Concatenate(联合,连环,连接,系):将向量进行线性组合
copy:复制
- 结构:
LSTM也具有这种链状的结构,但是重复的模块内部具有和Simple RNN重复的模块内部不同的结构。不再是只有一个神经网络层,而是有四个神经网络层,以非常特殊的方式进行交互。
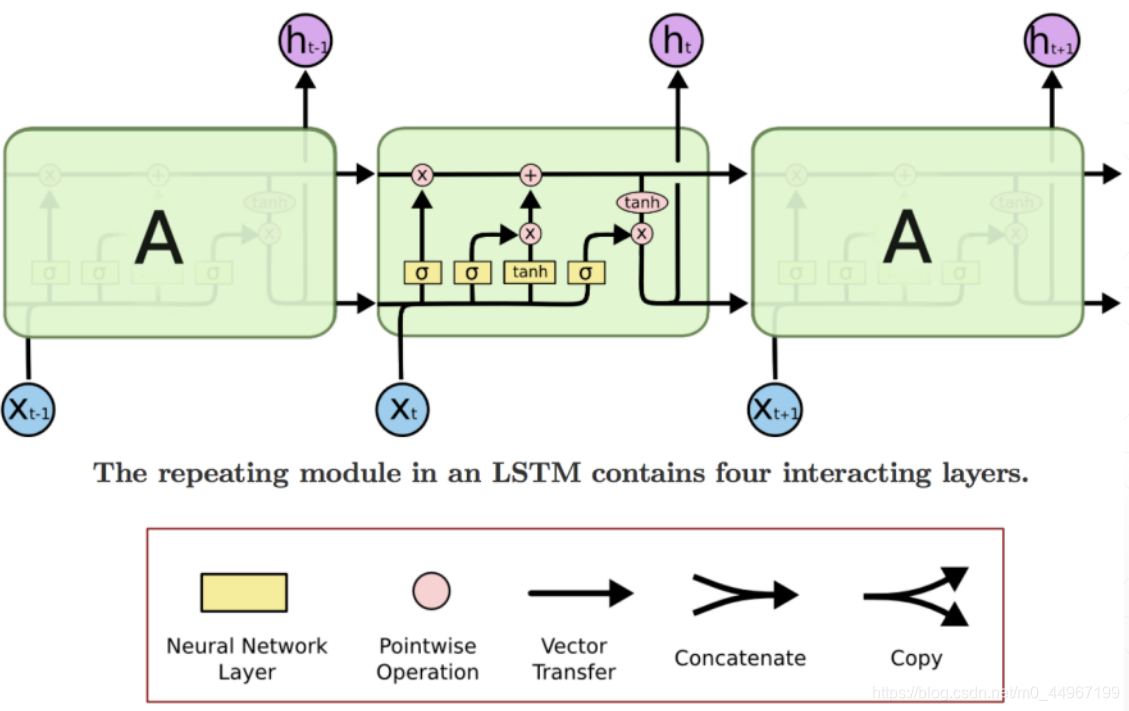
图中下边贯穿三个部分的线是 (作为模块的输出),它与模块的状态 (图中上边贯穿三个部分的直线)的区别在于:要经过一扇门进行选择输出(即每一个模块得到的新的状态并不是全部的输出)。这里上边垂直上去的 是将输出的 复制了一份上去。
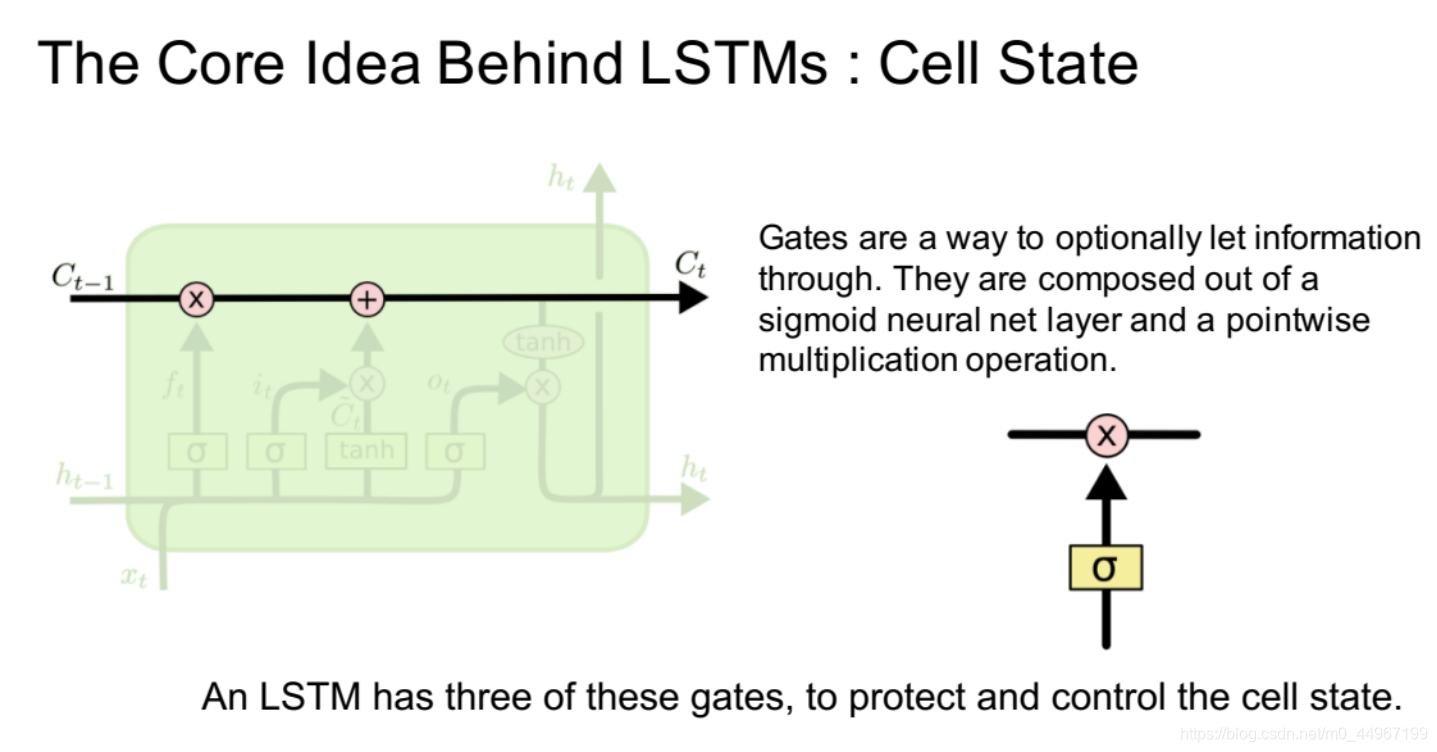
- 闸门是有选择地让信息通过的一种方式。 它们由包含sigmoid激活函数的神经网络层和“逐点”乘法(向量的内积(点乘))运算组成。
- LSTM使用三个这样的门,来保护和控制单元状态。
- 这里的粉色圆圈加一个乘号就是一个信息过滤的过程,做一个矩阵的内积
- 这里的粉色圆圈加一个加号就是一个简单的信息融合的过程
2.三道门分析(都是一个激活函数组成)
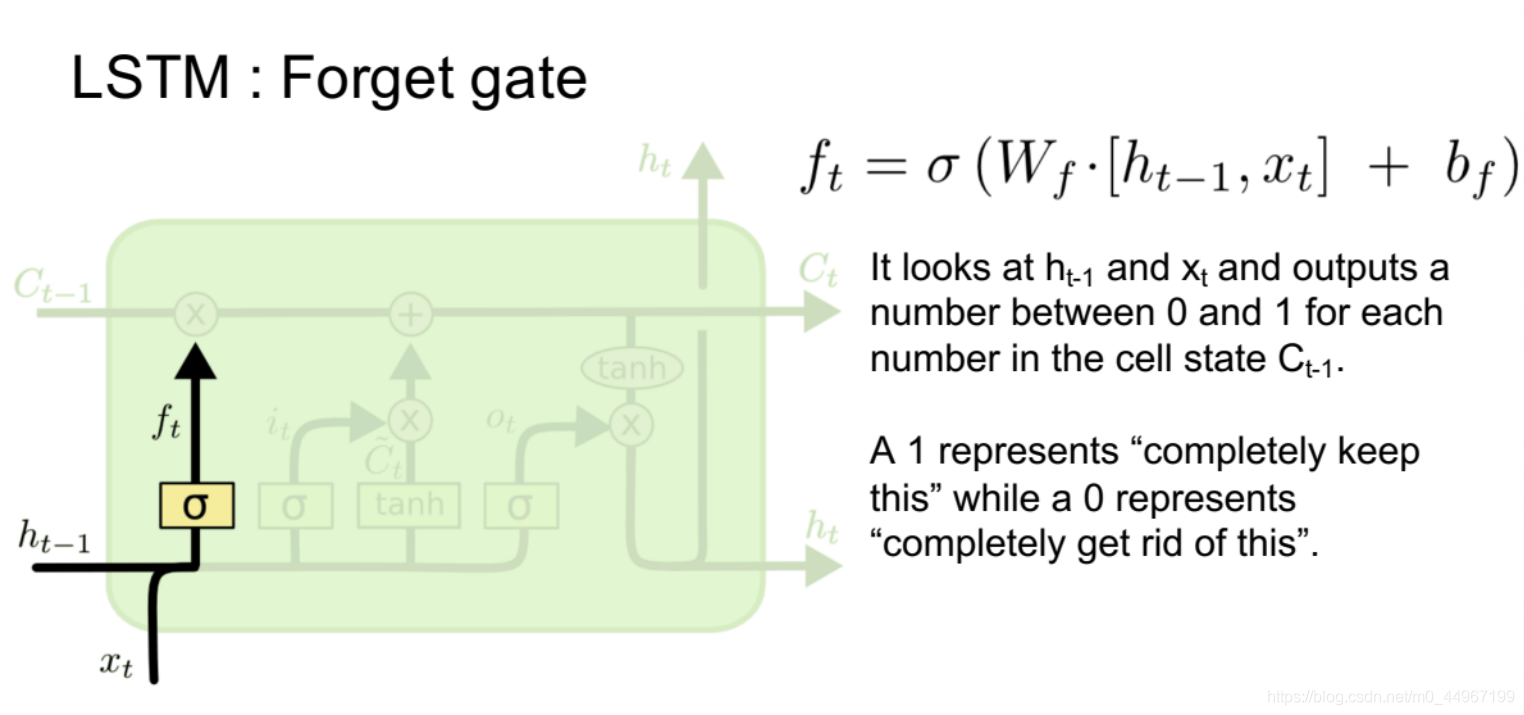
(1)遗忘门
遗忘门(Forget gate)
这道门的作用:对过去记忆的信息进行选择性的忘记(其实叫做remember门更合适)
- 这道门首先通过对输入 和 做一个线性变化,然后通过激活函数为上一个单元的状态 中的每一个值生成一个0到1之间的数值,用来做点乘。(这里也就是生成一个新的矩阵,矩阵中的元素值的分为都在0到1之间,与上一个时序的状态矩阵 做内积,来决定上一个时序的状态(memory)中那一部分记忆要忘掉,哪一部分要记住)
- 这里的 就是这个门的阈值,它的范围就是0到1,如果是0的话就全部忘记,如果是1的话就全部记住,在0到1之间的话就是一个记忆的程度。
- 新进来的 和上一个的 经过信息融合(乘以一个 )以后,在经过一个 函数。其实三道门都是由这两个变量 , )控制生成的,只是乘以不同的 .控制量还是 和 ,通过这两个量来控制所有的门的开度(sigmoid的函数只能给出一个[0,1],真正开多大还是由这两个变量决定,这两个变量属于 所以这个门的开度是 )
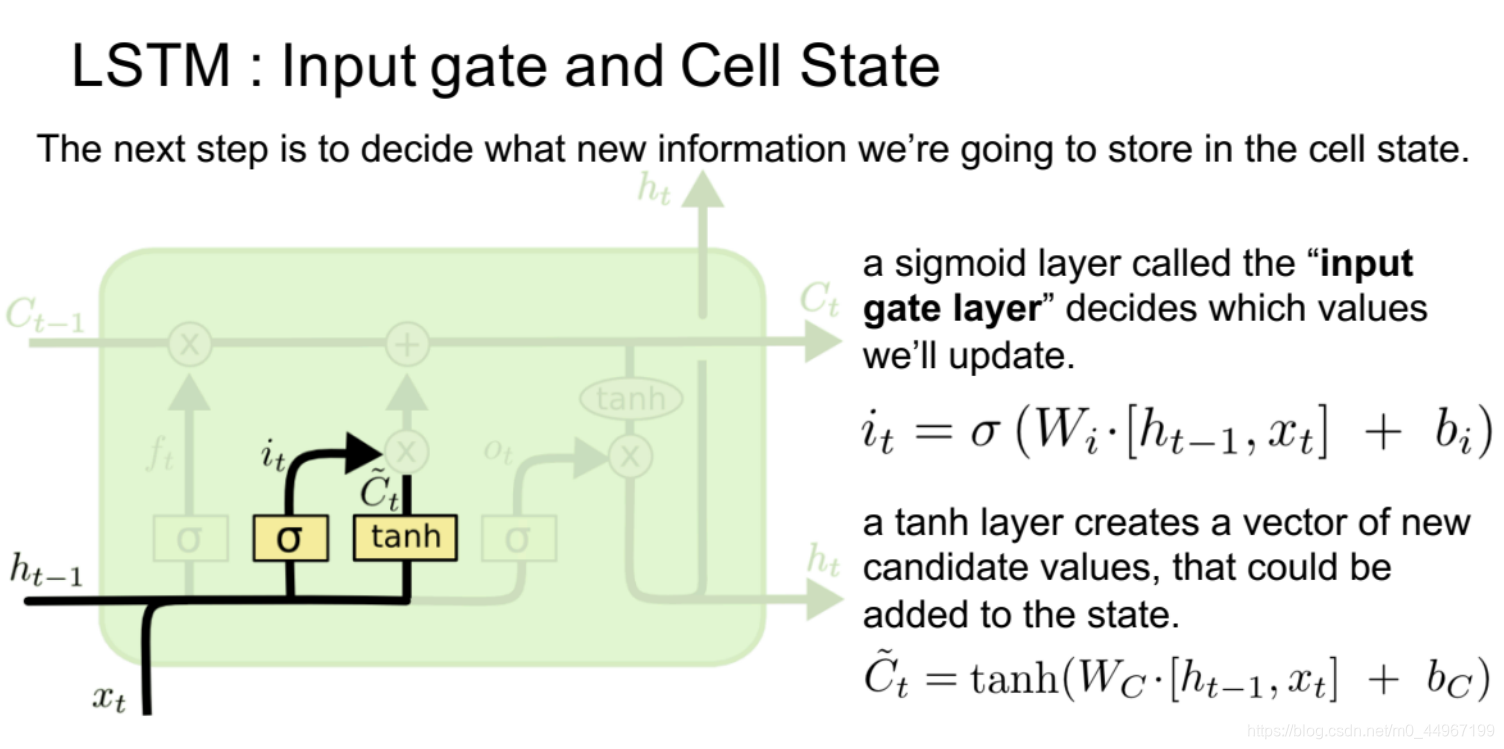
(2)输入门
输入门(Input gate)
这道门的作用:对输入的信息进行过滤
首先输入门也有一个开度,我们把它叫做 。同样的道理,将变量 , 与 做一个融合,会得到一个输入门的开度,有一个这样的前提就是说所有的 都是有自动优化的。(?)
这个门的开度是多少?
这个门的开度是多少是完全由backpropagate决定的,并不是由我们人为决定的,不然的话就没有办法设计开度了,所以它是由BP算法来决定的每一个开度是多少(通过反向传播来计算 参数)。也就是说决定每一个流程的时候,取多少的上一次的信息,取多少这一次的信息,在式子里边使用 矩阵来控制这一次取多少现在的信息。这里的开度是取[0,1]的范围。这里有些不一样的地方,我们新的信息不是 ,它也是 和 与 做了一个融合以后,得到一个 的这样的一个信息。
这个信息就是由 得来的,但是它不等于 。现在就得到了过滤后的历史信息和过滤后的新的信息 接下来对两个信息做一个简单的相加即可。也可以这样理解:在进入输入门之前增加了一个对输入值的处理过程, 与 经过一个线性变换,再经过一个激活函数会得到一个新的输入,叫做 ,它并不会全部用来更新memory,接下来会经过输入门的处理
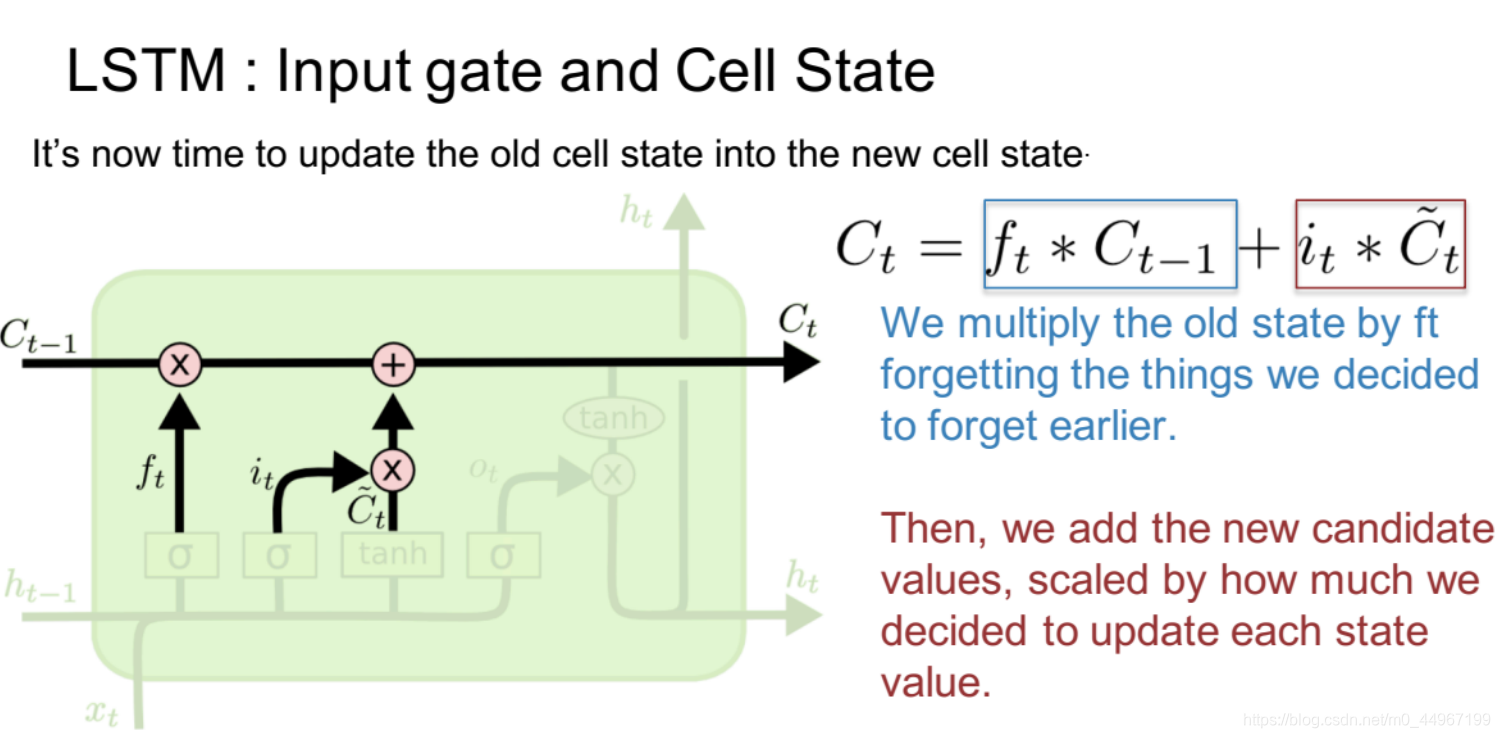
更新状态
这里便开始将原来旧的时序单元里边的状态更新到现在这个时序单元里边的新的状态。
这里新的状态就等于旧的状态乘以 ,(忘记哪些想要忘记的之前的旧的信息),然后加上新的输入值(候选值) 乘以 (以此来决定每个状态值更新时缩放的范围。)
(3)输出门
输出门(output gate)
这道门的作用:决定哪一部分状态信息要输出到下一个序列单元
首先,我们要使用一个激活函数层,来决定我们要将当前时序单元状态中的哪一部分作为输出部分输出。这里的 (output)就是得到的当下时序状态要输出的部分,然后将时序单元状态 放进激活函数 里边,将 里边的元素值变为-1到1,再乘以前边得到的经过一个激活函数门输出的 ,这样一来,输出的部分就可以由我们来控制了。
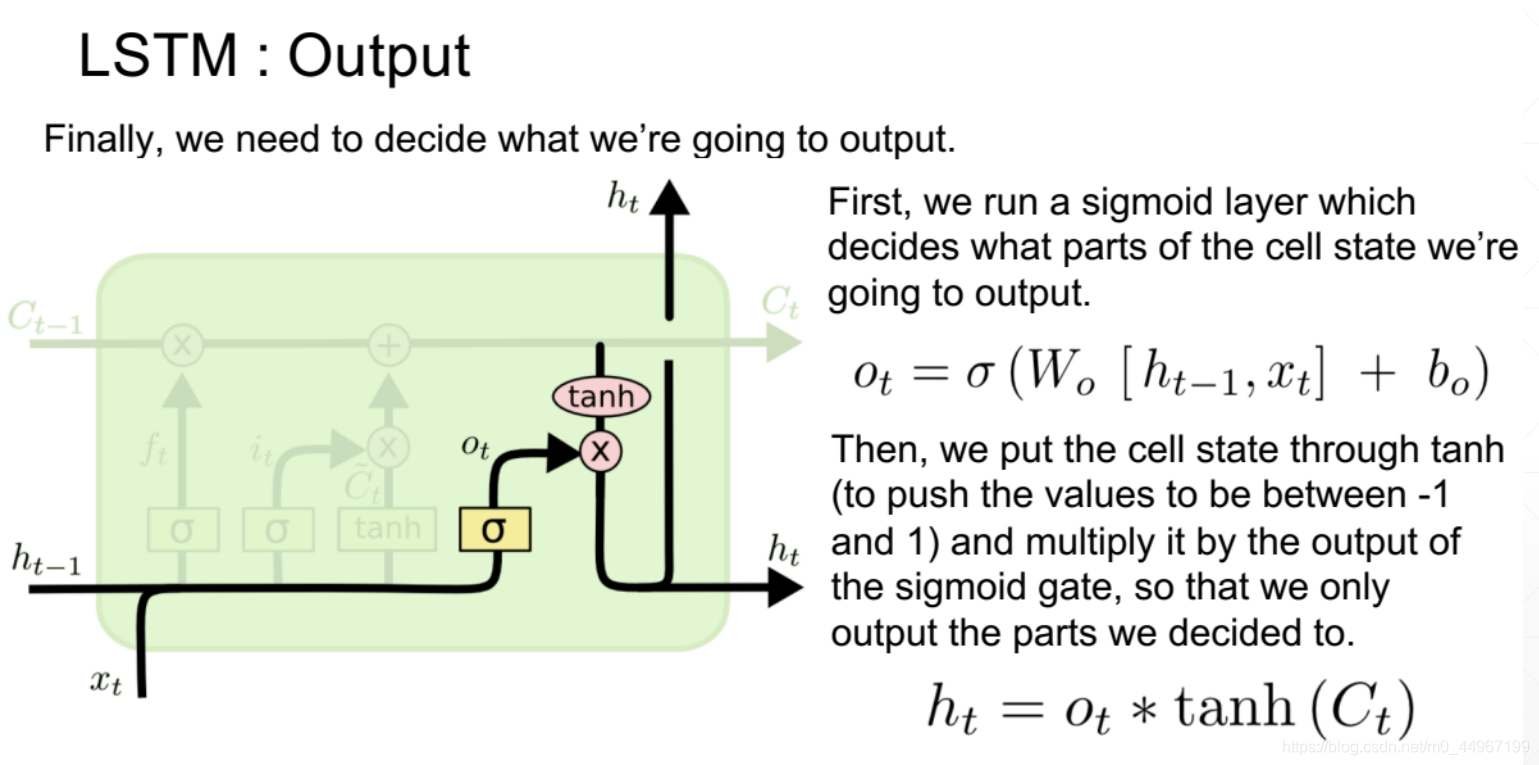
3.再用一个更加直观的方式来看看LSTM的原理:
在数据进入中间的输入门之前还会有一个数据的处理过程。
在进入输入门之前增加了一个对输入值的处理过程, 与 经过一个线性变换,再经过一个激活函数会得到一个新的输入,叫做 ,它并不会全部用来更新memory,接下来会经过输入门的处理
第一道forget门:忘记前一个状态不相关的部分
第二道input门:有选择的使用输入值更新单元状态值
第三道output门:输出想要输出的部分单元状态
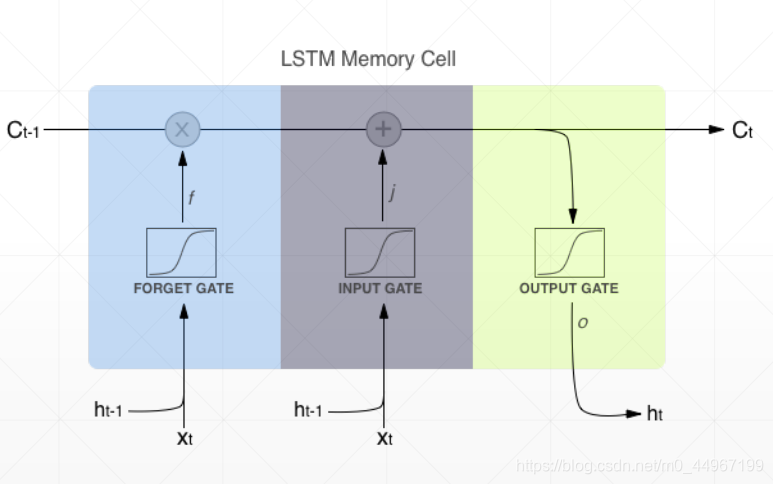
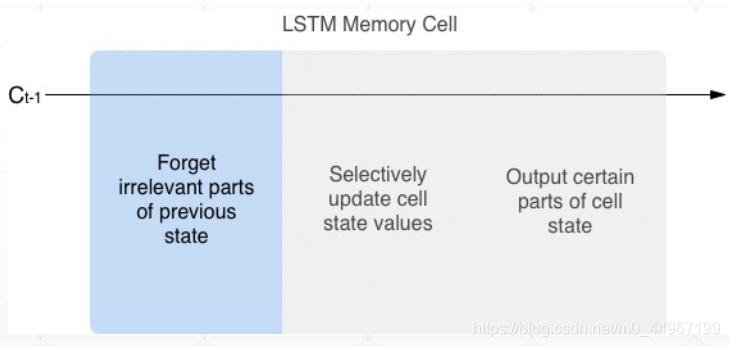
4.LSTM的原理图概览
由图得:所有的信息都是由变量 和 来控制的,即这三道门的信息都是由这两个变量来控制的。

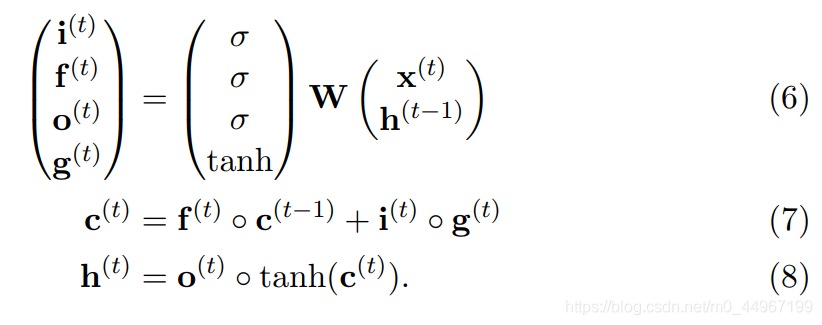
5.LSTM初衷再总结
从另外一个角度来理解LSTM的初衷是什么意思。
这里来看一下Input门和forget门在不同状态下会有什么样的逻辑
1.若是Input门全部关闭(也就是C波浪全部没有了),forget(remember)门全部打开
所以得到的输入信息全部是c_{t-1}会得到c_{t-1} = c_t,即全部用过去的信息,将现在新的信息全部忽略掉;
2.若是两道门全部都打开,
那么 (当然这里的 要乘以相应的门控变量),就是将过去的信息添加到现在的状态上边去;
3.若果两个门全部关闭的话,
c_t = 0 + 0,因此你就会清除掉当前的一个memory;如果只开Input门的话memory c_t就等于新的信息 ,实现了将原来的memory进行覆盖
也就是可以理解为:你是清除值,还是覆盖值,还是添加值,还是忽略当前的输入直接使用历史的值,这四种状态可以从某种程度上边解释,我们的三道门设置的一个初衷