全连接神经网络和卷积神经网络,他们都只能单独的取处理一个个的输入,前一个输入和后一个输入是完全没有关系的。但是,某些任务需要能够更好的处理序列的信息,即前面的输入和后面的输入是有关系的。比如,当我们在理解一句话意思时,孤立的理解这句话的每个词是不够的,我们需要处理这些词连接起来的整个序列;当我们处理视频的时候,我们也不能只单独的去分析每一帧,而要分析这些帧连接起来的整个序列。这时,就需要用到深度学习领域中另一类非常重要神经网络:循环神经网络(Recurrent Neural Network)。
下图是一个简单的循环神经网络,它由输入层、一个隐藏层和一个输出层组成:
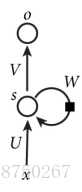
U是输入层到隐藏层的权重矩阵;V是隐藏层到输出层的权重矩阵。那么,现在我们来看看W是什么。循环神经网络的隐藏层的值s不仅仅取决于当前这次的输入x,还取决于上一次隐藏层的值s。权重矩阵 W就是隐藏层上一次的值作为这一次的输入的权重。
如果我们把上面的图展开,循环神经网络也可以画成下面这个样子:

现在看上去就比较清楚了,这个网络在t时刻接收到输入
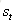
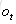
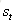
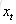
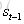
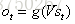

公式很好理解g()和f()都是激活函数;如果把
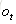

从上面可以看出,循环神经网络的输出值


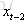

双向循环神经网络:

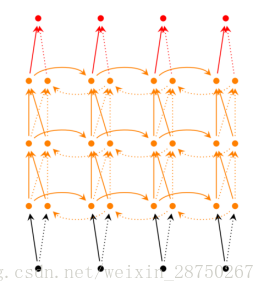
从上图可以看出,双向卷积神经网络的隐藏层要保存两个值,一个A参与正向计算,另一个值A'参与反向计算。最终的输出值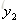



其中,






深度循环神经网络:
前面我们介绍的循环神经网络只有一个隐藏层,我们当然也可以堆叠两个以上的隐藏层,这样就得到了深度循环神经网络。如下图所示:
我们把第i个隐藏层的值表示为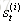


循环神经网络的训练算法:BPTT
BPTT算法是针对循环层的训练算法,它的基本原理和BP算法是一样的,也包含同样的三个步骤:
1. 前向计算每个神经元的输出值;
2. 反向计算每个神经元的误差项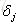
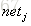
3. 计算每个权重的梯度。
最后再用随机梯度下降算法更新权重。
1.前项计算:

2.误差项计算:
BTPP算法将第l层t时刻的误差项
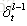


将沿时间往前传递一个时刻,我们就可以求得任意时刻k的误差项

上式就是将误差项沿时间反向传播的算法。


将误差项反向传递到上一层网络:

上式就是将误差传递到上一层算法。
3.权重梯度计算:
误差项




那么最终梯度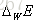

同理:

以上所有公式具体推导参见博客(https://zybuluo.com/hanbingtao/note/541458)。
RNN的梯度爆炸和消失问题:
如果计算误差项时向前看很远,这就会导致误差项的值增长或缩小的非常快,这样就会导致相应的梯度爆炸和梯度消失问题;
梯度爆炸:程序会收到NaN错误。我们可以设置一个梯度阈值,当梯度超过这个阈值的时候可以直接截取。
梯度消失:
1. 合理的初始化权重值。初始化权重,使每个神经元尽可能不要取极大或极小值,以躲开梯度消失的区域。
2. 使用relu代替sigmoid和tanh作为激活函数。
3. 使用其他结构的RNNs,比如长短时记忆网络(LTSM)和Gated Recurrent Unit(GRU),这是最流行的做法。我们将在以后的文章中介绍这两种网络。
基本的循环神经网络存在梯度爆炸和梯度消失问题,并不能真正的处理好长距离的依赖(虽然有一些技巧可以减轻这些问题)。事实上,真正得到广泛的应用的是循环神经网络的一个变体:长短时记忆网络。它内部有一些特殊的结构,可以很好的处理长距离的依赖。