一、循环神经网络简介
循环神经网络挖掘数据中的时序信息以及语义信息的深度表达能力,在语音识别、语言模型、机器翻译以及时序分析等方面实现了突破。
1、循环神经网络简介
循环神经网络的主要用途是处理和预测序列数据。循环神经网络的来源就是为了刻画一个序列当前的输出与之前信息的关系。从网络结构上,循环神经网络会记忆之前的信息,并利用之前的信息影响后面结点的输出。也就是说,循环神经网络的隐藏层之间的结点是有连接的,隐藏层的输入不仅包括输入层的输出,还包括上一时刻隐藏层的输出。
下图是一个典型的循环神经网络。循环神经网络的主体结构A的输入除了来自输入层
,还有一个循环的边来提供上一时刻的隐藏状态
。在每一时刻,循环神经网络的模块A在读取了
和
之后会生成新的隐藏状态
,并产生本时刻的输出
。循环神经网络当前的状态
是根据上一时刻的状态
和当前的输入
共同决定的。
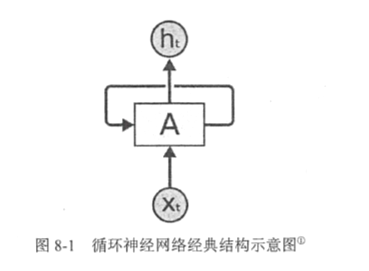
在时刻t,状态
浓缩了前面序列
,…,
的信息,用于作为输出
的参考。由于序列长度可以无限长,维度有限的h状态不可能将序列的全部信息都保存下来,因此模型必须学习只保留与后面任务
,…相关的最重要的信息。
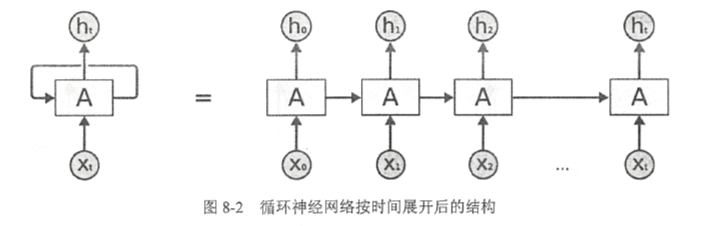
上图中,循环神经网络对长度为N的序列展开后,可以视为一个有N个中间层的前馈神经网络。这个前馈神经网络没有循环链接,因此可以直接使用反向传播算法进行训练,而不需要任何特别的优化算法。这样的训练方法称为“沿时间反向传播”,是训练循环神经网络最常见的方法。
对于一个序列数据,可以将这个序列上不同时刻的数据依次传入循环神经网络的输入层,而输出可以是对序列下一时刻的预测,也可以是对当前时刻信息的处理结果(如语音识别结果)。循环神经网络要求每一个时刻都有一个输入,但是不一定每个时刻都需要有输出。
2、循环神经网络前向传播流程
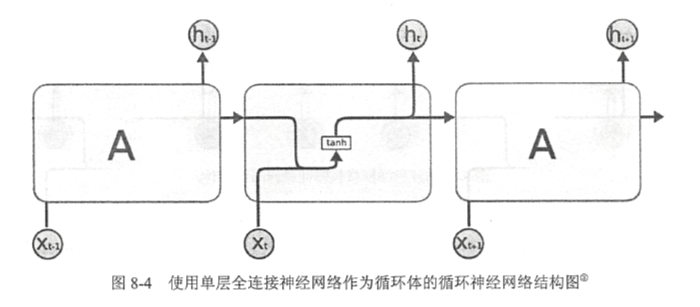
上图展示了一个最简单的循环体结构。通过上图介绍循环神经网络前向传播的完整流程。
循环神经网络中的状态是通过一个向量来表示的,这个向量的维度也称为循环神经网络隐藏层的大小,假设其为n。
假设输入向量的维度为x,隐藏层状态的维度为n,那么图中循环体的全连接层神经网络的输入大小为x+n。也就是将上一时刻的状态与当前时刻的输入拼接成一个大的向量作为循环体中神经网络的输入。因为该全连接层的输出为当前时刻的状态,于是输出层的节点个数也为n,循环体中的参数个数为(n+x) x n+n个。
注意:
1、循环体状态与最终输出的维度通常不同,因此为了将当前时刻的状态转化为最终的输出,循环神经网络还需要另外一个全连接神经网络类完成这个过程。这和卷积神经网络中最后的全连接层的意义是一样的。
2、在得到循环神经网络的前向传播结果之后,可以和其他神经网络类似地定义损失函数。循环神经网络唯一的区别在于因为它每个时刻都有一个输出,所以循环神经网络的总损失为所有时刻(或部分时刻)上的损失函数的总和。
以下代码实现了简单的循环神经网络前向传播的过程:
import numpy as np
X=[1,2]
state=[0.0,0.0]
# 分开定义不同输入部分的权重以方便操作
w_cell_state=np.asarray([[0.1,0.2],[0.3,0.4]])
w_cell_input=np.asarray([0.5,0.6])
b_cell=np.asarray([0.1,-0.1])
# 定义用于输出的全连接层参数
w_output=np.asarray([[1.0],[2.0]])
b_output=0.1
# 按照时间顺序执行循环神经网络的前向传播过程
for i in range(len(X)):
# 计算循环体中的全连接层神经网络
before_activation=np.dot(state,w_cell_state)+X[i]*w_cell_input+b_cell
state=np.tanh(before_activation)
# 根据当前时刻状态计算最终输出
final_output=np.dot(state,w_output)+b_output
# 输出每个时刻的信息
print("before activation:%f" % before_activation)
print("state:%f" % state)
print("output:%f" % final_output)运行以上程序可以看到输出:
before activation:[0.6 0.5]
state:[0.53704957 0.46211716]
output:[1.56128388]
before activation:[1.2923401 1.39225678]
state:[0.85973818 0.88366641]
output:[2.72707101]和其他神经网络类似,在定义完损失函数之后,使用类似地优化框架,Tensorflow就可以自动完成模型训练的过程。需要指出的是:理论上循环神经网络可以支持任意长度的序列,然而在实际训练过程中,如果序列过长,一方面会导致训练时出现梯度消失和梯度爆炸的问题;另一方面,展开后的循环神经网络会占用过大的内存,所以实际中会规定一个最大长度,当序列长度超过规定长度后会对序列进行截断。
二、长短时记忆网络(LSTM)结构
当前预测位置和相关信息之间的文本间隔不断增大时,简单循环神经网络有可能会丧失学习到距离如此远的信息的能力,或者在复杂语言场景中,有用信息的间隔有大有小、长短不一,循环神经网络的性能也会受到限制。
长短时记忆模型(long short-term memory,LSTM)的设计就是为了解决这个问题。采用LSTM结构的循环神经网络比标准的循环神经网络表现更好。与单一tanh循环体结构不同,LSTM是一种拥有三个“门”结构的特殊网络结构。
1、LSTM结构
LSTM靠一些“门”的结构让信息有选择性地影响循环神经网络中每个时刻的状态。所谓“门”结构就是一个使用sigmoid神经网络和一个按位做乘法的操作,这两个操作合在一起就是一个“门”的结构。使用sigmoid作为激活函数的全连接神经网络层会输出一个0到1之间的数值,描述当前输入有多少信息量可以通过这个结构。当门打开时(sigmoid神经网络层输出为1时),全部信息都可以通过;当门关上时(sigmoid神经网络层输出为0时),任何信息都无法通过。
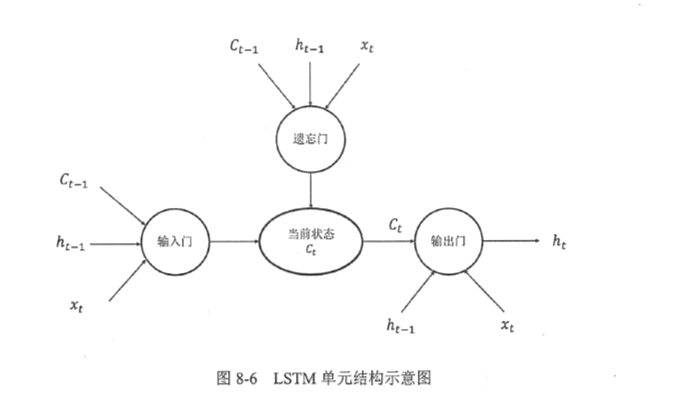
上图中“遗忘门”和“输入门”可以使神经网更有效的保存长期记忆。“遗忘门”的作用是让循环神经网络忘记之前没有用的信息。“遗忘门”会根据当前输入 和上一时刻输出 决定哪一部分记忆需要被遗忘。
(1)假设状态c的维度为n。“遗忘门”会根据当前输入
和上一时刻输出
计算一个维度为n的向量
,它的每一维度上的值都在(0,1)范围内,再将上一时刻的状态
与f向量按位相乘,那么f取值接近0的维度上的信息就会被“忘记”,而f取值接近1的维度上的信息会被保留。
比如文章中先介绍了某地原来是绿水蓝天,后来被污染了。于是在看到被污染之后,循环神经网络应该“忘记”之前绿水蓝天的状态。
(2)在循环网络“忘记”了部分之前的状态后,它还需要从当前的输入补充最新的记忆。这个过程由“输入门”完成。“输入门”会根据
和
决定哪些信息加入到状态
中生成新的状态
。
比如当看到文章中提到环境被污染之后,模型需要将这个信息写入新的状态。
**(3)**LSTM结构在计算得到新的状态
后需要产生当前时刻的输出,这个过程由“输出门”完成。“输出门”会根据最新的状态
、上一时刻的输出
和当前的输入
来决定该时刻的输出
。
比如当前的状态为被污染,那么“天空的颜色”后面的单词很有可能是“灰色的”。
2、LSTM前向传播过程
具体LSTM每个“门”的公式定义如下:
输入值
输入门
遗忘门
输出门
新状态
输出
其中
$W_i
$W_o$是4个维度为[2n,n]的参数矩阵。
3、Tensorflow中LSTM结构的实现
以下代码展示了在Tensorflow中实现使用LSTM结构的循环神经网络的前向传播过程:
# 定义一个LSTM结构。在Tensorflow中通过一句简单的命令就可以实现一个完整的LSTM结构
# LSTM中使用的变量也会在该函数中自动被声明
lstm=tf.nn.rnn.cell.BasicLSTMCell(lstm_hidden_size)
# 将LSTM中的状态初始化为全0数组。BasicLSTMCell类提供了zero_state函数来生成全0初始状态。state是一个
# 包含两个张量的LSTMStateTuple类,其中state.c和state.h分别对应了上述c状态和h状态
# 和其他神经网络类似,在优化循环神经网络时,每次也会使用一个batch的训练样本
# 在以下代码中,batch_size给出了一个batch的大小
state=lstm.zero_state(batch_size,tf.float32)
# 定义损失函数
loss=0.0
# 虽然在测试时循环神经网络可以处理任意长度的序列,但是在训练中为了将循环神经网络展开成前馈神经网络,我们需要
# 知道训练数据的序列长度。在以下代码中,用num_steps来表示这个长度。后面会介绍使用dynamic_rnn动态处理变长
# 序列的方法
for i in range(num_steps):
# 在第一时刻声明LSTM结构中使用的变量,在之后的时刻都需要复用之前定义好的变量。
if i>0:
tf.get_variable_scpoe.reuse_variables()
# 每一步处理时间序列中的一个时刻。将当前输入current_input和前一时刻状态state(h_t-1和c_t-1)传入定义
# 的LSTM结构可以得到当前LSTM的输出lstm_output(ht)和更新后状态state(ht和ct)。lstm_output用于输出
# 给其他层,state用于输出给下一时刻,他们在dropout等方面可以有不同的处理方式。
lstm_output,state=lstm(current_input,state)
# 将当前时刻LSTM结构的输出传入一个全连接层得到最后的输出
final_output=fully_connected(lstm_output)
# 计算当前时刻输出的损失
loss+=calc_loss(final_output,expected_output)
# 使用常规神经网络的方法训练模型三、循环神经网络的变种
1、双向循环神经网络
在经典的循环神经网络中,状态和传输是从前往后单向的。然而在有些问题中,当前时刻的输出不仅和之前的状态有关,也和之后的状态相关。这时需要使用双向循环神经网络(bidirectional RNN)来解决这个问题。双向循环神经网络是由两个独立的循环神经网络叠加在一起组成的。输出由这两个循环神经网络的输出拼接而成。下图展示了一个双向循环神经网络的结构:
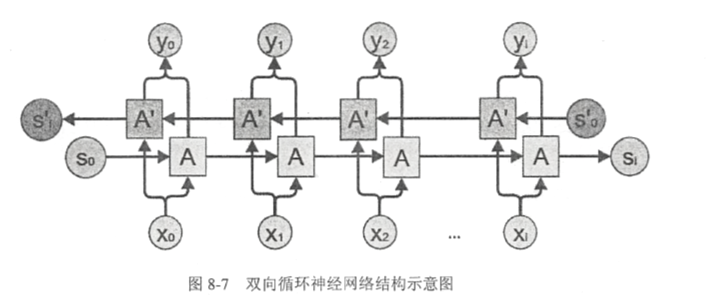
在每一个时刻t,输入会同时提供给这两个方向相反的循环神经网络、两个独立的网络独立进行计算,各自产生该时刻的新状态和输出,而双向循环神经网络的最终输出是这两个单向循环神经网络的输出的简单拼接。两个循环神经网络除方向不同以外,其余结构完全对称。每一个网络中的循环体可以自由选用任意结构,RNN或LSTM。
2、深层循环神经网络
深层循环神经网络(Deep RNN)是循环神经网络的另一种变种。为了增强模型的表达能力,可以在网络中设置多个循环层,将每层循环网络的输出传给下一层进行处理。下图展示了一个深层循环神经网络的结构:
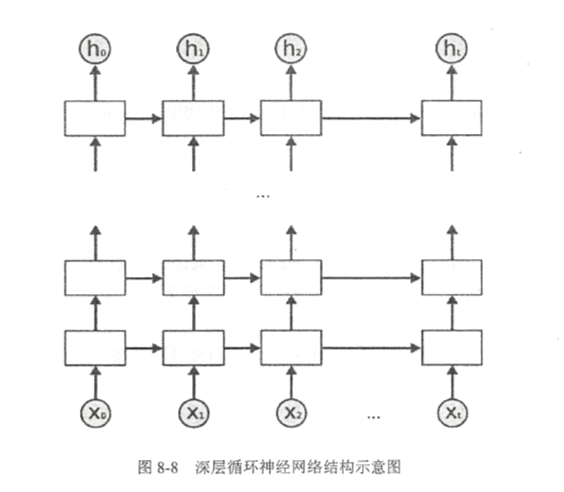
在一个L层的深层循环网络中,每一时刻的输入
到输出
之间有L个循环体,网络因此可以从输入中抽取更加高层的信息。和卷积神经网络类似,每一层的循环体中参数是一致的,而不同层中的参数可以不同。为了更好支持深层循环神经网络,Tensorflow中提供了MultiRNNCell类来实现深层循环神经网络的前向传播过程。
# 定义一个基本的LSTM结构作为循环体的基础结构。深层循环神经网络也支持使用其他的循环体结构
lstm_cell=tf.nn.rnn.cell.BasicLSTMCell
# 通过MUltiRNNCell类实现深层循环神经网络中每一个时刻的前向传播过程。其中number_of_layers表示有多少层,
# 即从x_t到o_t需要经过多少个LSTM结构。
stacked_lstm=tf.nn.rnn_cell.MultiRNNCell([lstm_cell(lstm_size) for _ in range(number_of_layers)])
# 和经典的循环神经网络一样,可以通过zero_state函数来获取初始状态
state=stacked_lstm.zero_state(batch_size,tf.float32)
# 计算每一时刻的前向传播结果
for i in range(len(num_steps)):
if i>0:
tf.get_variable_scope().reuse_variables()
stacked_lstm_output,state=stacked_lstm(current_input,state)
final_output=fully_connected(stacked_lstm_output)
loss+=calc_loss(final_output,expected_output)Tensorflow只需要在BasicLSTMCell的基础上再封装一层MultiRNNCell就可以非常容易地实现深层循环神经网络了。
3、循环神经网络dropout
在循环神经网络中使用dropout可以让神经网络更加健壮。类似在卷机神经网络只在最后的全连接层中使用dropout,循环神经网络一般只在不同层循环体结构之间使用dropout,而不在同一层的循环体结构之间使用。即从时刻t-1传递到时刻t时,循环神经网络不会进行状态的dropout;而在同一时刻t中,不同层循环体之间会使用dropout。
下图展示了循环神经网络使用dropout的方法。
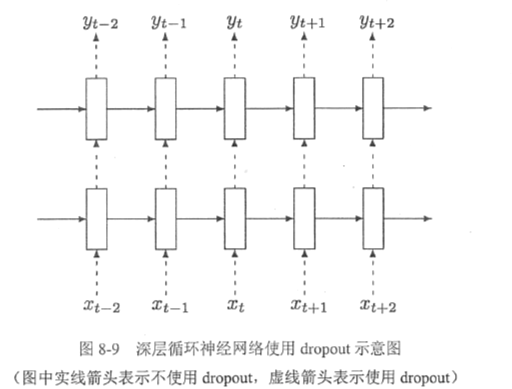
假设要从t-2时刻的输入
传递到t+1时刻的输出
,那么
将首先传入第一层循环体结构,这个过程会使用dropout,但是从t-2时刻的第一层循环体结构传递到第一层的t-1、t、t+1时刻不会使用dropout。在t+1时刻的第一层循环体结构传递到同一时刻内更高层的循环体结构时,会再次使用dropout。
在Tensorflow中,使用tf.nn.rnn_cell.DropoutWrapper类可以很容易实现dropout功能。以下代码展示了如何在Tensorflow中实现带dropout的循环神经网络。
# 定义LSTM结构
lstm_cell=tf.nn.rnn_cell.BasicLSTMCell
# 使用DropoutWrapper类来实现dropout功能。该类通过两个参数来控制dropout的概率,一个参数为
# input_keep_prob,它可以用来控制输入的dropout概率;另一个参数为output_Keep_prob,它可以用来
# 控制输出的dropout概率
# 在使用了DropoutWrapper的基础上定义MultiRNNCell
stacked_lstm=rnn_cell.MultiRNNCell([tf.nn.rnn_Cell.DropoutWrapper(lstm_cell(lstm_size)) for _ in range(number_of_layers)])四、循环神经网络样例应用
以时间预测为例,利用循环神经网络实现对函数sin x取值的预测
# -*- coding: utf-8 -*-
import numpy as n
import yensorflow as tf
# 加载matplotlib工具包,使用该工具包可以对预测的sin函数曲线进行绘图
import matplotlib as mpl
mpl.use('Agg')
from matplotlib import pyplot as plt
HIDEN_SIZE=30 # LSTM中隐藏节点的个数
NUM_LAYERS=2 # LSTM的层数
TIMESTEPS=10 # 循环神经网络的训练序列长度
TRAINING_STEPS=10000 # 训练轮数
BATCH_SIZE=32 # batch的大小
TRAINING_EXAMPLES=10000 # 训练数据大小
TESTING_EXAMPLES=1000 # 测试数据个数
SAMPLE_GAP=0.01 # 采样间隔
def generate_data(seq):
X=[]
y=[]
# 序列的第i项和后面的TIMESTEPS-1项合在一起作为输入;第i+TIMESTEPS项作为输出。即用sin函数前面的
# TIMESTEPS个点的信息,预测第i+TIMESTEPS个点的函数值
for i in range(len(seq)-TIMESTEPS)
X.append([seq[i:i+TIMESTEPS]])
y.append([seq[i+TIMESTEPS]])
return np.array(X,dtype=np.float32),np.array(y,dtype=np.float32)
def lstm_model(X,y,is_training)
# 使用多层的LSTM结构
cell=tf.nn.rnn_cell.MultiRNNCell([tf.nn.rnn_cell.BasicLSTMCell(HIDDEN_SIZE) for _ in range(NUM_LAYERS)])
# 使用Tensorflow接口将多层LSTM结构连接成RNN网络并计算其前向传播结果
outputs,_=tf.nn.dynamic_rnn(cell,X,dtype=tf.float32)
# outputs是顶层LSTM在每一步的输出结果,维度是[batch_size,time,HIDDEN_SIZE]在本问题中只关注最后一
# 个时刻的输出结果
output=outputs[:,-1,:]
# 对LSTM网络的输出再做加一层全连接层并计算损失。这里默认的损失为平均平方差损失函数
predictions=tf.contrib.layers.fully_connected(output,1,activation_fn=None)
# 只在训练时计算损失函数和优化步骤。测试时直接返回预测结果
if not is_training:
return predictions,None,None
loss=tf.losses.mean_squared_error(labels=y,predictions=predictions)
# 创建模型优化器并得到优化步骤
train_op=tf.contrib.layers.optimize_loss(loss,tf.train.get_global_step(),optimizer="Adagrad",learning_rate=0.1)
return predictions,loss,train_op
def train(sess,train_X,train_y):
# 将训练数据以数据集的方式提供给计算图
ds=tf.data.Dataset.from_tensor_slices((train_X,train_y))
ds=ds.repeat().shuffle(1000).batch(BATCH_SIZE)
X,y=ds.make_one_shot_iterator().get_next()
# 调用模型,得到预测结果、损失函数和训练操作
with tf.variable_scpoe("model"):
predictions,loss,train_op=lstm_model(X,y,True)
# 初始化变量
sess.run(tf.global_variables_initializer())
for i in range(TRAINING_STEPS):
_,l=sess.run([train_op,loss])
if i%100 == 0:
print("train step:"+str(i)+",loss:"+str(l))
def run_eval(sess,test_X,test_y):
# 将测试数据以数据集的方式提供给计算图
ds=tf.data.Dataset.from_tensor_slices((test_X,test_y))
ds=d.batch(1)
X,y=ds.make_one_hot_interator().get_next()
# 调用模型得到计算结果,这里不需要输入真实的y值
with tf.variables_scope("model",reuse=True):
prediction,_,_=lstm_model(X,[0.0],False)
# 将预测结果存入一个数组
predictions=[]
labels=[]
for i in range(TESTING_EXAMPLES):
p,l=sess.run([prediction,y])
predections.append(p)
labels.append(l)
# 计算rmse作为评价指标
predictions=np.array(predictions).squeeze()
labels=np.array(labels).squeeze()
rmse=np.sqrt(((predictions-labels)**2).mean(axis=0))
print("Mean Square Error is:%f" % rmse)
# 对预测的sin函数曲线进行绘图
plt.figure()
plt.plot(predictions,label='predictions')
plt.plot(labels,label='real_sin')
plt.legend()
plt.show()
# 用正弦函数生成训练和测试数据集合
# numpy.linspace函数可以创建一个等差序列的数组,它常用的参数有3个,第一个参数表示起始值,第二个参数表示
# 终止值,第三个参数表示数列的长度。如linespace(1,10,10)产生的数组是array([1,2,3,4,5,6,7,8,9,10])
test_start=(TRAING_EXAMPLES+TIMESTEPS)*SAMPLE_GAP
test_end=test_start+(TESTING_EXAMPLES+TIMESTEPS)*SAMPLE_GAP
train_X,train_y=generate_data(np.sin(np.linspace(0,test_start,TRAINING_EXAMPLES+TIMESTEPS,dtype=np.float32)))
test_X,test_y=generate_data(np.sin(np.linspace(test_start,test_end,TESTING_EXAMPLES+TIMESTRPS,dtype=np.float32)))
with tf.Session() as sess:
# 训练模型
train(sess,train_X,train_y)
# 使用训练好的模型对测试数据进行预测
run_eval(sess,test_X,test_y)