Dense全连接 Deep
DNN稠密网络,全连接网络(权重最多,占大头)
卷积 权重少 原因是:卷积核上权重整个图像上是共享的,所以参数少
循环神经网络
RNN:专门用来处理带有序列关系模式的数据(天气,故事,自然语言),使用权重共享来减少需要训练的权重的数量
使用思路:不仅要考虑序连接关系还要考虑先后的时间关系
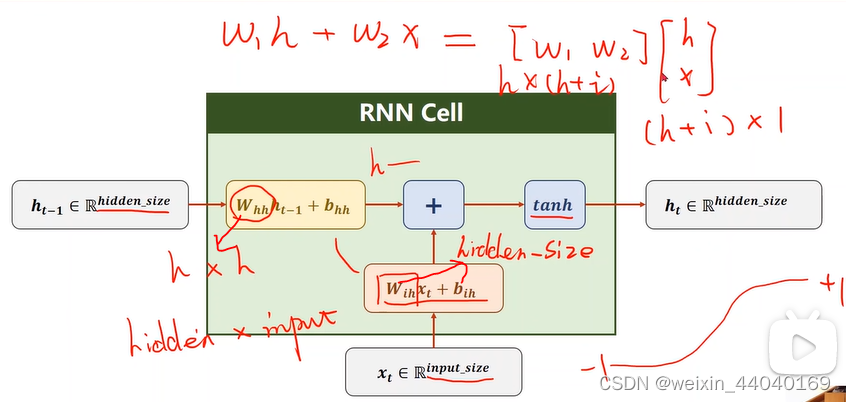
RNN Cell:本质线性层(一个维度映射到另一个维度) 如下图
h0先验值:CNN+FC(图像生成文本)或设成和h1…同维度的向量
for x in X: #h1=Linear(x1,h0)
h=Linear(x,h) #h2 =Linear(x2,h1)

RNN具体计算过程:
激活函数tanh(-1到+1)
Whh是hh
Wih是hi
如下图
cell = torch.nn.RNNCell(input_size=input_size, hidden_size=hidden_size)
#输入维度,隐层维度
hidden = sell(input,hidden)
input of shape(batch,imput_size )
hidden of shape(batch, hidden_size)
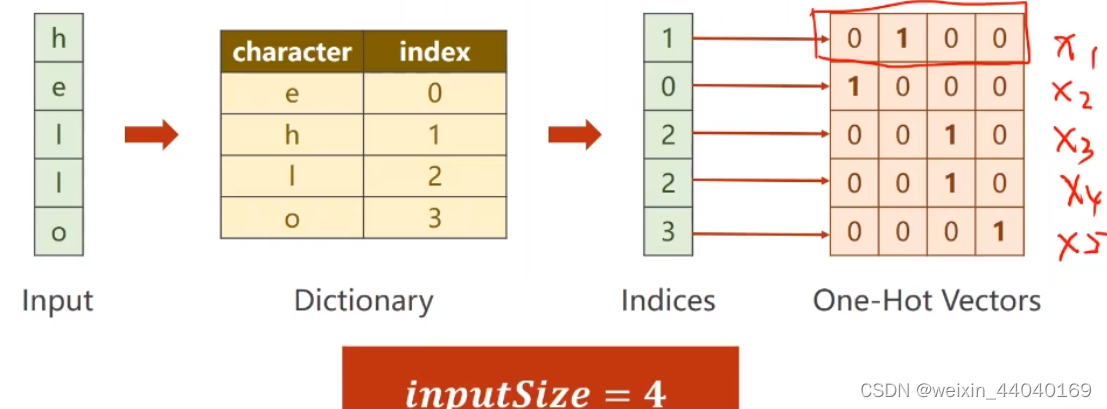
对每个样本里有 x1,x2,x3 即序列 每个维度为4即有4个元素

import torch
batch_size=1
seq_len=3
input_size=4
hidden_size=2
Cell=torch.nn.RNNCell(input_size=input_size,hidden_size=hidden_size)#初始化,构建RNNCell
dataset=torch.randn(seq_len,batch_size,input_size)#设置dataset的维度
hidden=torch.zeros(batch_size,hidden_size)#隐层的维度:batch_size*hidden_size,初始h0置0向量
for idx,input in enumerate(dataset):
print('='*20,idx,'='*20)
print('Input size:',input.shape)
hidden=Cell(input,hidden)
print('Outputs size:',hidden.shape)
print(hidden)
RNN numLayers
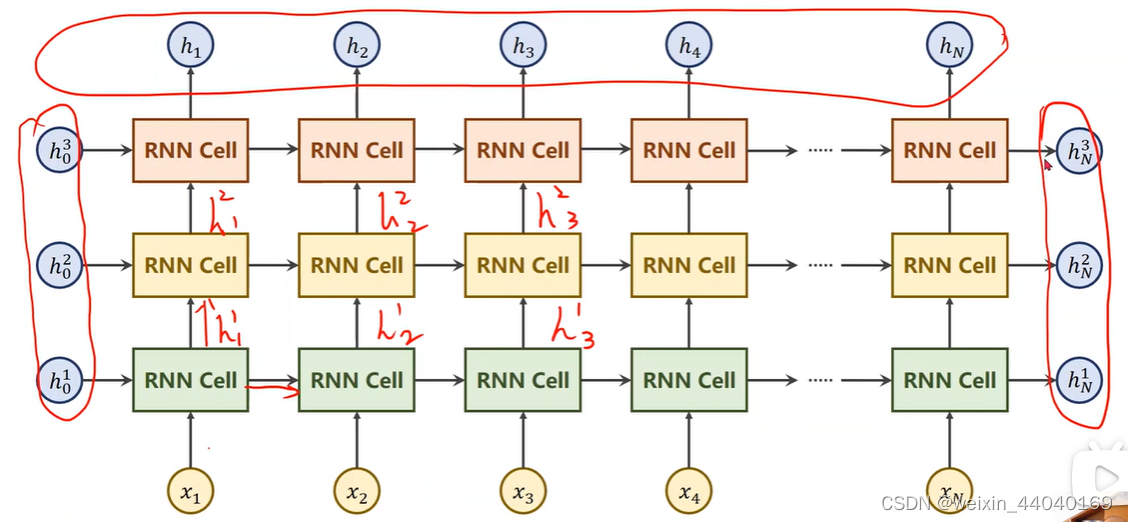
同样颜色的RNN Cell是同一个,所以下图是有3个线性层(一个RNNCell是一个线性层)
import torch
batch_size=1
seq_len=3
input_size=4
hidden_size=2
num_layers=1
cell=torch.nn.RNN(input_size=input_size,hidden_size=hidden_size,num_layers=num_layers)
inputs=torch.randn(seq_len,batch_size,input_size)
hidden=torch.zeros(num_layers,batch_size,hidden_size)
out,hidden=cell(inputs,hidden)
print('Output size:',out.shape)
print('Output:',out)
print('Hidden size:',hidden.shape)
print('Hidden',hidden)
seq --> seq学习序列转换规律
属于分类问题
RNN cell:
单词—>字典—>索引---->独热向量

import torch
input_size = 4
hidden_size = 4
batch_size = 1 # 一个样本
idx2char = ['e', 'h', 'l', 'o']
x_data = [1, 0, 2, 2, 3] # 维度: seq * input_szie
y_data = [3, 1, 2, 3, 2]
one_hot_lookup = [[1, 0, 0, 0],# 查询表
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]]
x_one_hot = [one_hot_lookup[x] for x in x_data] # 变成独热向量--根据x值将one_hot_lookup列表中对应的向量拿走
# print(x_one_hot)
# -1 表示自动适配,维度自己判断,在这里指seq维度
inputs = torch.Tensor(x_one_hot).view(-1, batch_size, input_size)
labels = torch.LongTensor(y_data).view(-1, 1)
class Model(torch.nn.Module):
def __init__(self, input_size, hidden_size, batch_size):
super(Model, self).__init__()
self.batch_size = batch_size
self.input_size = input_size
self.hidden_size = hidden_size
self.rnncell = torch.nn.RNNCell(input_size=self.input_size,
hidden_size=self.hidden_size)
def forward(self, input, hidden):
# ht = cell(xt, ht-1)
hidden = self.rnncell(input, hidden)
return hidden
def init_hidden(self):#初始隐层
return torch.zeros(self.batch_size, self.hidden_size)
net = Model(input_size, hidden_size, batch_size)
criterion = torch.nn.CrossEntropyLoss()#交叉熵
optimizer = torch.optim.Adam(net.parameters(), lr=0.01)#改进的基于梯度下降的优化器
for epoch in range(100):
loss = 0
optimizer.zero_grad()
hidden = net.init_hidden()#初始化hidden
print('Predicted string:', end='')
# inputs:seqlen*batch_size*input_size , input按序列读取x1,x2....
for input, label in zip(inputs, labels):#input :batch_size*input_size
hidden = net(input, hidden)#input是序列里的每个元素------结合具体例子来说元素就是单词中的字母
loss += criterion(hidden, label)#序列里每步的loss加到一起
# hidden 是一个一列四维的向量,里面每个字母的概率【分类问题】
_, idx = hidden.max(dim=1)
# 根据词典打印
print(idx2char[idx.item()], end='')
loss.backward()
optimizer.step()
print(', Epoch [%d/15] loss=%.4f' % (epoch+1, loss.item()))
结果:

RNN:
#使用RNN
import torch
input_size=4
hidden_size=4
num_layers=1
batch_size=1
seq_len=5
# 准备数据
idx2char=['e','h','l','o']
x_data=[1,0,2,2,3] # hello
y_data=[3,1,2,3,2] # ohlol
one_hot_lookup=[[1,0,0,0],
[0,1,0,0],
[0,0,1,0],
[0,0,0,1]] #分别对应0,1,2,3项
x_one_hot=[one_hot_lookup[x] for x in x_data] # 组成序列张量
print('x_one_hot:',x_one_hot)
# 构造输入序列和标签
inputs=torch.Tensor(x_one_hot).view(seq_len,batch_size,input_size)
labels=torch.LongTensor(y_data) #labels维度是: (seqLen * batch_size ,1)
# design model
class Model(torch.nn.Module):
def __init__(self,input_size,hidden_size,batch_size,num_layers=1):
super(Model, self).__init__()
self.num_layers=num_layers
self.batch_size=batch_size
self.input_size=input_size
self.hidden_size=hidden_size
self.rnn=torch.nn.RNN(input_size=self.input_size,
hidden_size=self.hidden_size,
num_layers=self.num_layers)
def forward(self,input):
hidden=torch.zeros(self.num_layers,self.batch_size,self.hidden_size)
out, _=self.rnn(input,hidden)
# 为了能和labels做交叉熵,需要reshape一下:(seqlen*batchsize, hidden_size),即二维向量,变成一个矩阵
return out.view(-1,self.hidden_size)
net=Model(input_size,hidden_size,batch_size,num_layers)
# loss and optimizer
criterion=torch.nn.CrossEntropyLoss()
optimizer=torch.optim.Adam(net.parameters(), lr=0.05)
# train cycle
for epoch in range(20):
optimizer.zero_grad()
#inputs维度是: (seqLen, batch_size, input_size) labels维度是: (seqLen * batch_size * 1)
#outputs维度是: (seqLen, batch_size, hidden_size)
outputs=net(inputs)
loss=criterion(outputs,labels)
loss.backward()
optimizer.step()
_, idx=outputs.max(dim=1)
idx=idx.data.numpy()
print('Predicted: ',''.join([idx2char[x] for x in idx]),end='')
print(',Epoch [%d/20] loss=%.3f' % (epoch+1, loss.item()))