1、在自然语言处理过程中,神经网络中输入的语言中的每个单词都是以向量的形式送入的,那个该怎样将语言转化为向量形式呢?
一般采用1-of-N编码方式处理,处理过程如下:

具体原理参考笔记:
http://blog.csdn.net/chloezhao/article/details/53484471
2、Long Short-term Memory(LSTM)结构框架如下图所示:

由图可知:LSTM共有三个门和一个内存单元,顾名思义,是门就有开和关两种状态,所以三个门都有各自的信号控制部分分别控制三个门的状态,像一般的神经网络节点只有一个输入和输出,而对于LSTM来说,该网络有四个输入(一个网络输入和三个门控信号)和一个输出。
其运行过程如下图所示:

这里的激活函数一般是sigmoid函数,sigmoid函数的输出为0~1之间的值。注意这里遗忘门的输入是相乘,而输出是相加。
LSTM实际运行例子如下:
输入向量为x,输出为y
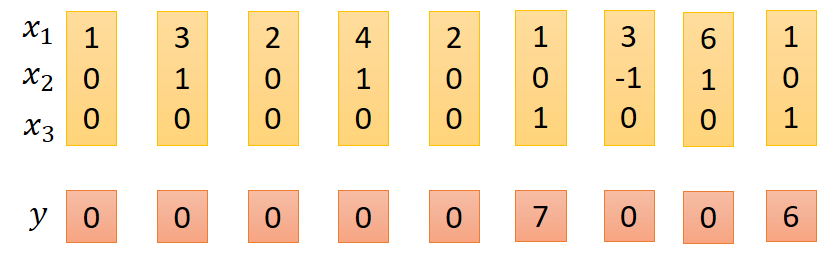
其中x1为网络需要处理的数据,定义x2、x3的功能分别如下:

注意这里遗忘门和输入门都是由x2控制,故x2可以有三-1、0、1种状态,x3是输出门控制信号,实际结果处理如下:
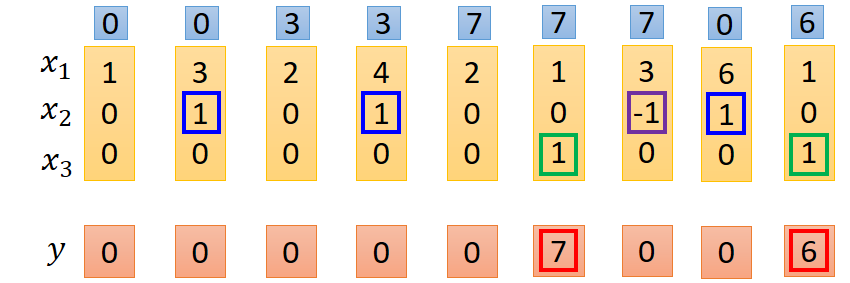
第一排数据是内存中的数据改变值过程。
具体处理过程的方式如下,只例举了其中部分
由图中注意到,每一个输入的节点都有相同的输入,而每个节点不同的效果则由各个输入的权重值决定,实际的输入除了x1、x2、x3之外,还有一个1,这个输入1的作用后面再解释,下面就从权重这个角度解释各个门的作用效果,LSTM单元输入模块中,只有x1的权重不为0,而其他的权重均为0,所以所以给模块输入只有x1有作用。同理对于输入门和输出门而言,只有x2、1有作用,输出门只有x3、1有作用。
由以上分析可知,1只有在输入、输出和遗忘门中才有作用,而在遗忘门中和另外两个门的作用效果又不相同,1的实际作用需要从激活函数说起,一般来说LSTM的门节点的激活函数均为sigmoid函数,输出范围为0~1之间,而实际输出则为0和1两个状态,所以在sigmoid输出后会进行归一化处理,以0.5作为阈值,大于0.5则输出1,否则为0。因为输入门和输出门1的权重相同,所以作用效果也一样,只要分析其中一个即可,对于输入门而言x2其作用,而x2有三种不同的取值,分别为-1、0、1;当取值为1时,激活函数输入值为100-10=90,sigmoid函数输出值大于0.5,标准化后输出为1,即输入门开,当为-1时,sigmoid输入值为-110,此时sigmoid输出小于0.5,标准化后为0,输入门关闭。当为0时,1的作用体现出来了,如果没有1,则sigmoid函数输入值为0输出值为0.5,此时就无法将其标准化为0或者1了,如果有一个1,则sigmoid函数输入值为-10,输出值小于0.5,可将其标准化为0。输出门的作用也是同样的道理。对于遗忘门而言,x2为-1才有作用,复位内存,即sigmoid函数输出为0,当x2为-1时,sigmoid输入值为-90,输出小于0.5标准化后为0,复位内存,同理当x2为1是,sigmoid输出标准化后输出为1,当x2为0是,如果没有1,则会出现输入门一样的情况,无法标准化为0或者1,有1后就可以标准化为1.
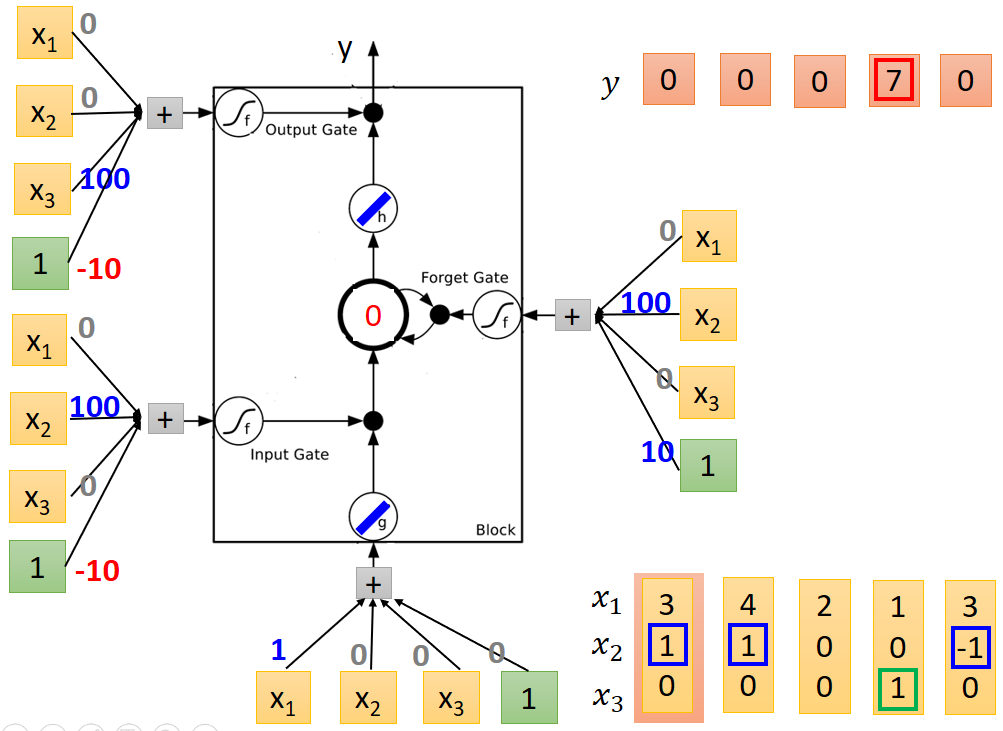
数据流向过程如下图所示:
刚开始内存中的值为0。
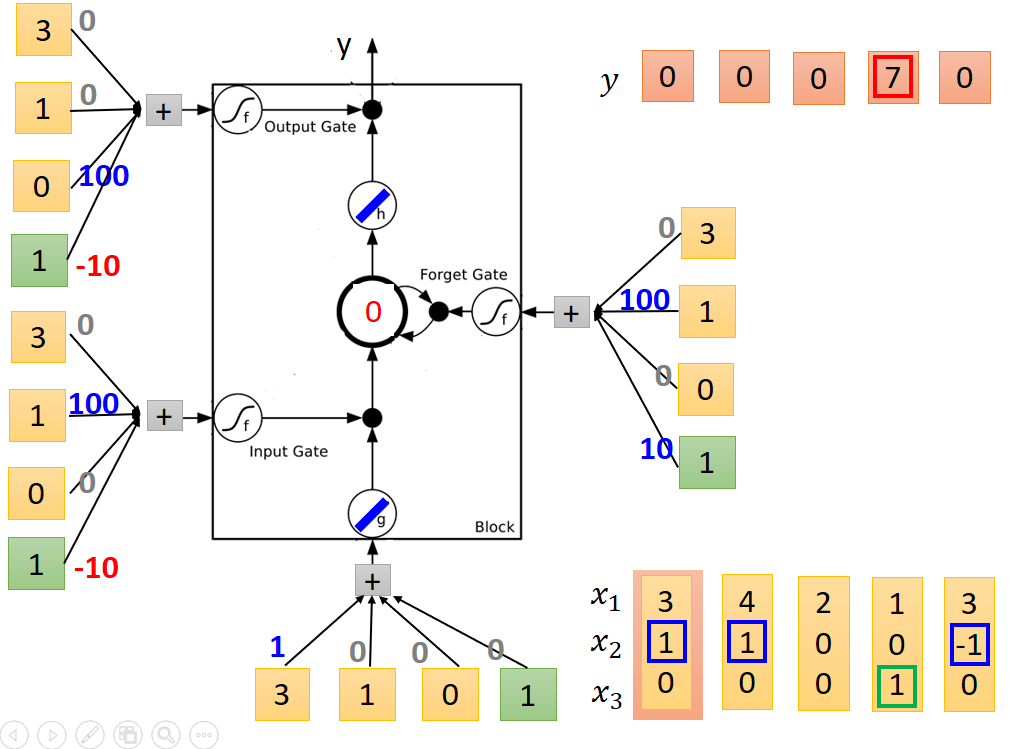
送入第一列值后个节点输出结果如下:
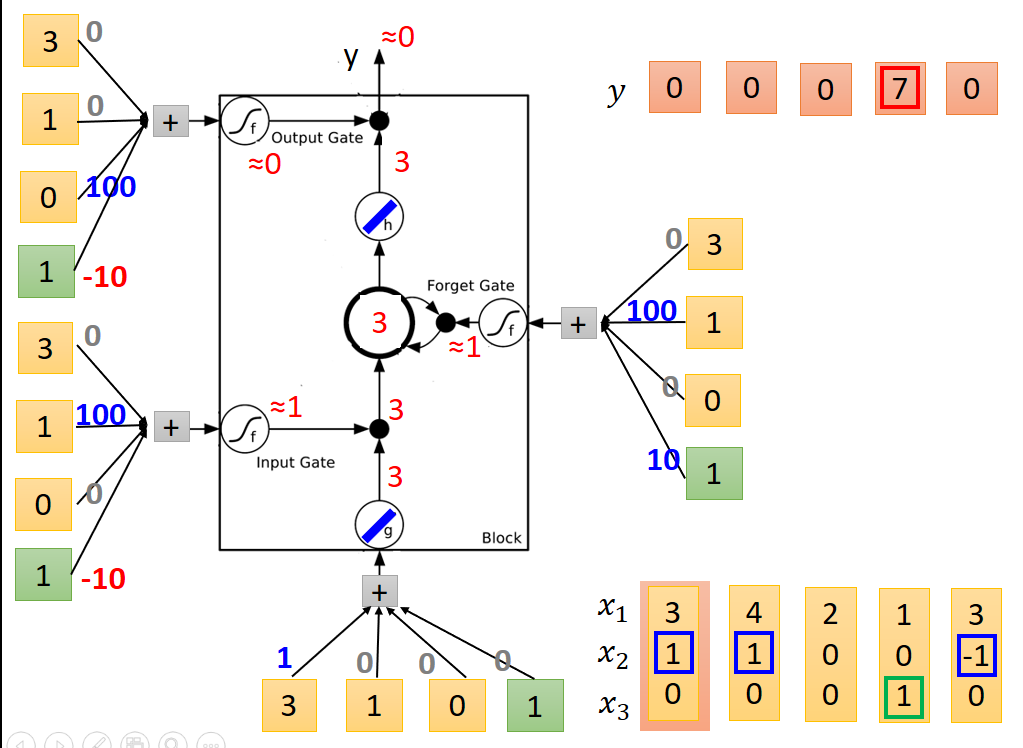
送入第二列值后节点输出结果如下:注意内存中的值为和上一次相加。
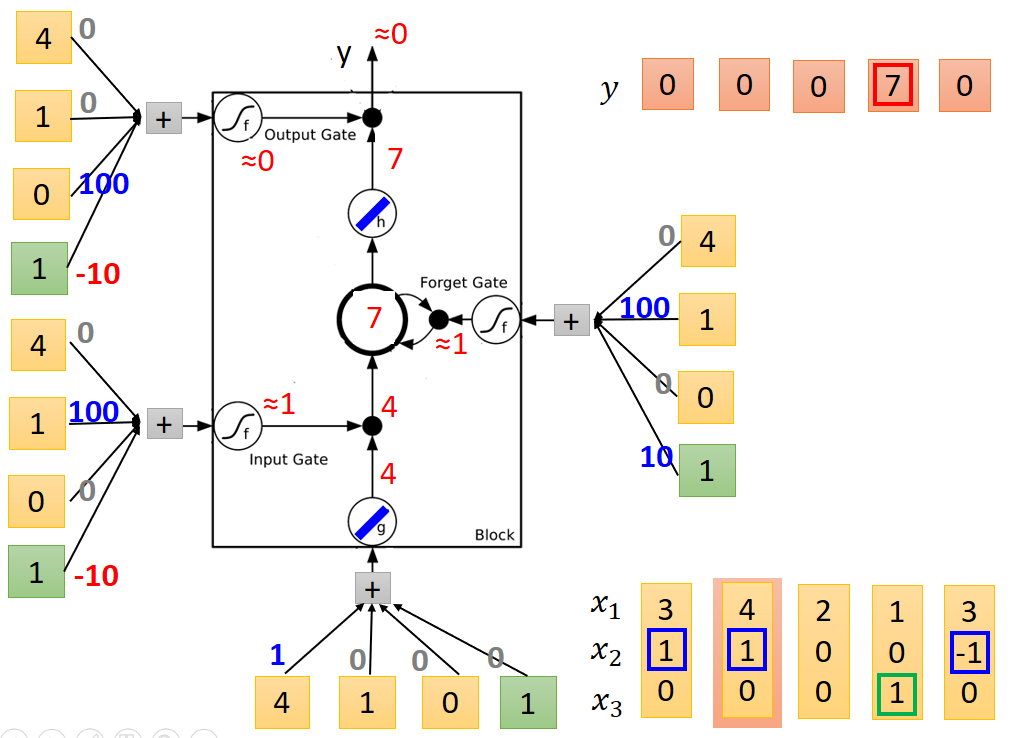
第三列
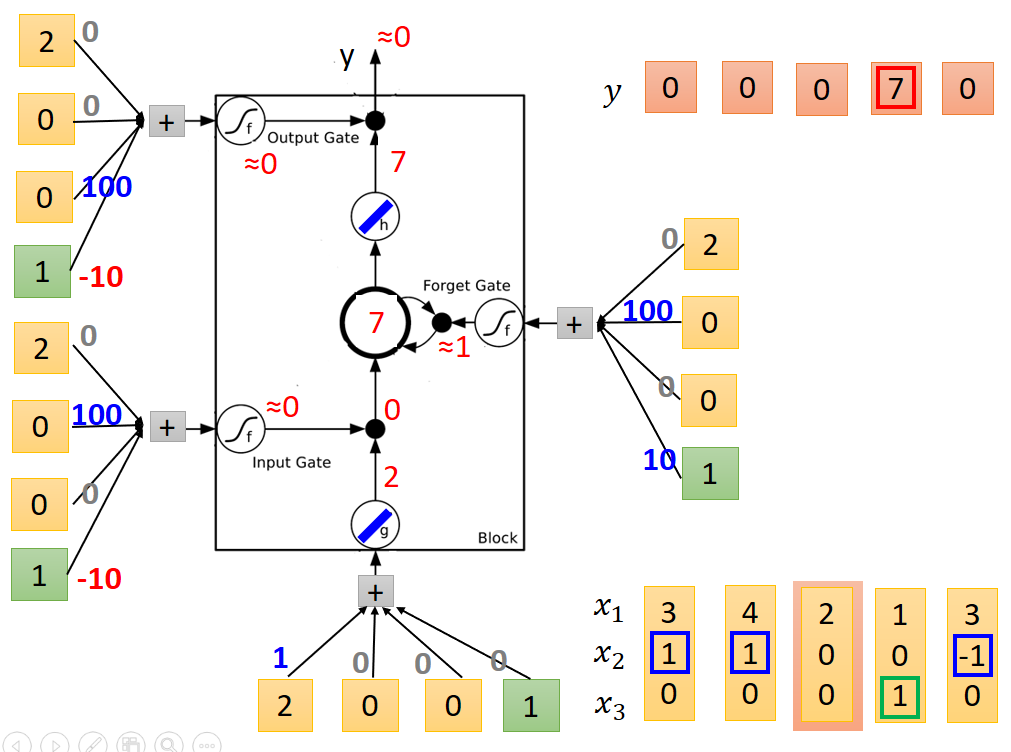
第四列,输出结果为7

第五列
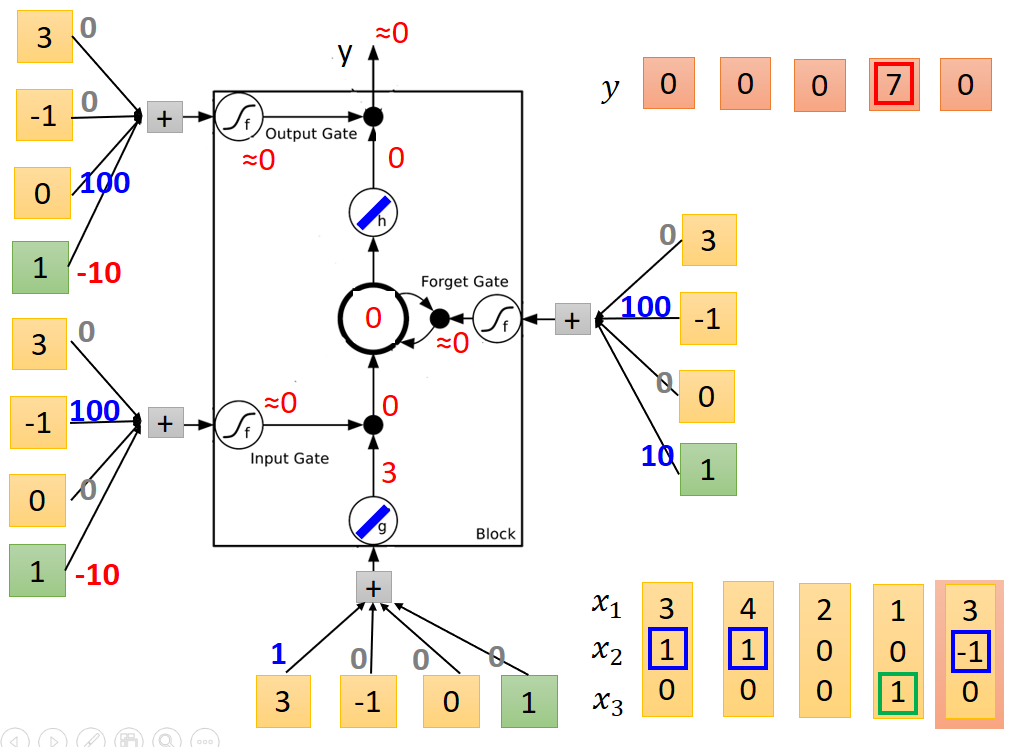
至此,整个例子运行结束。
以上就是LSTM网络结构原理图解
3、LSTM的特点
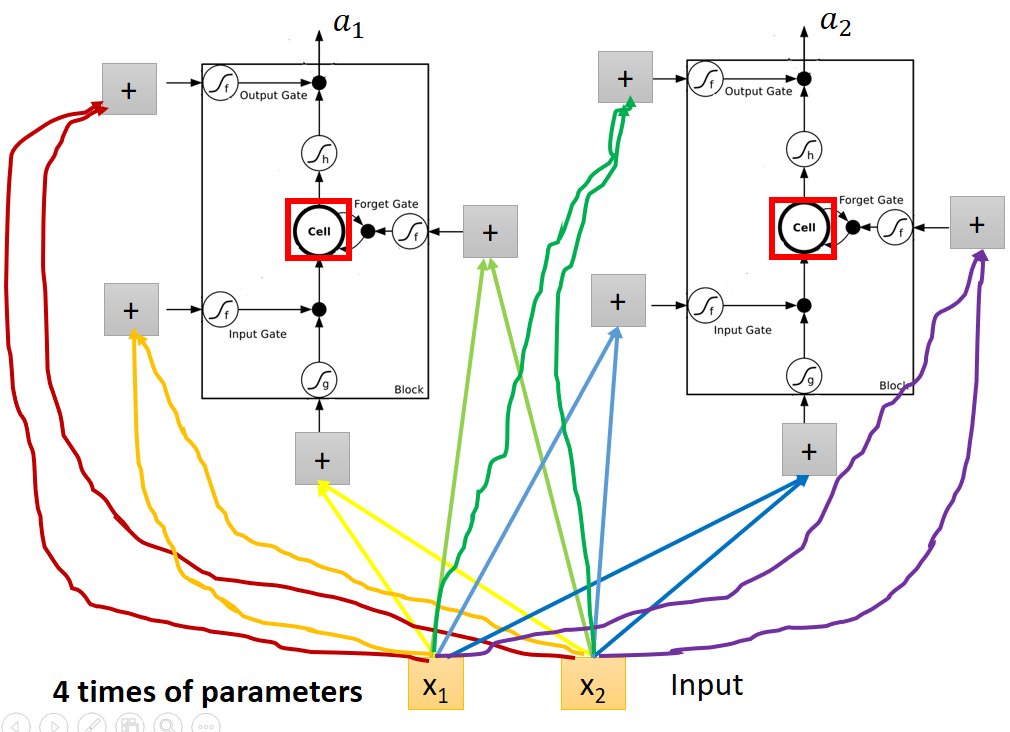
一般的神经网络如下:

用LSTM代替后参数数量变为原来的四倍
4、LSTM变体
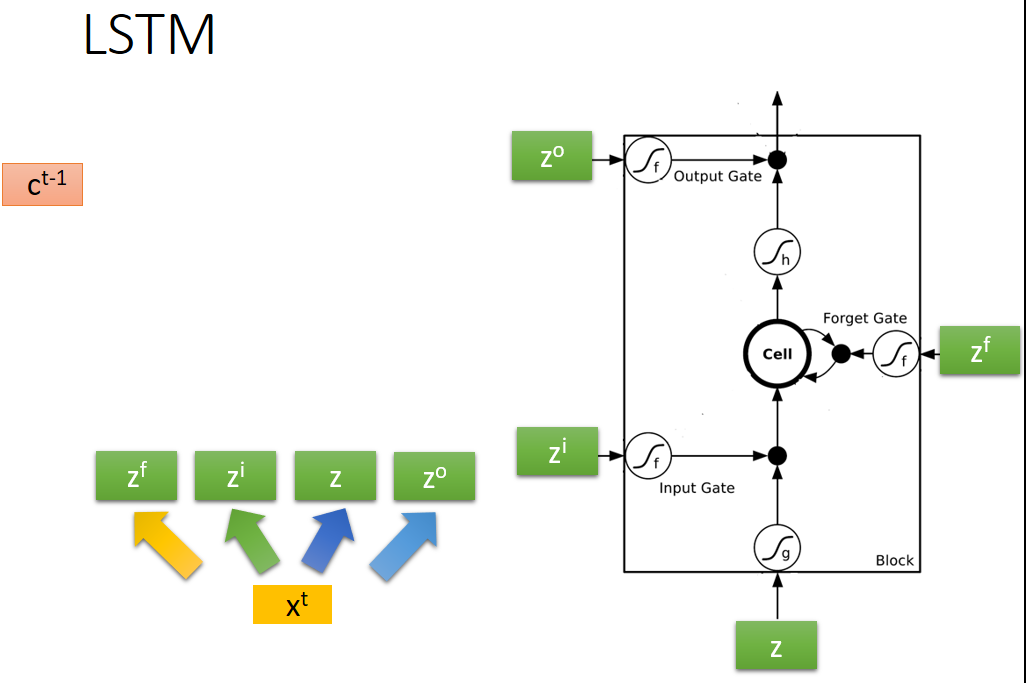
上图中向量c表示内存中原有的值,输入向量xt经过不同的权值处理后分别产生了四个z分别对应LSTM的四个输入。

上图中,每个LSTM输入中都包含有上一个LSTM的内存值和输出值,再分别作用到四个输入端口,也可以等价的理解,将上一次LSTM的内存值和输出值分别作用到下一个LSTM的四个输入端口,此连接成为peephole连接。
多层连接
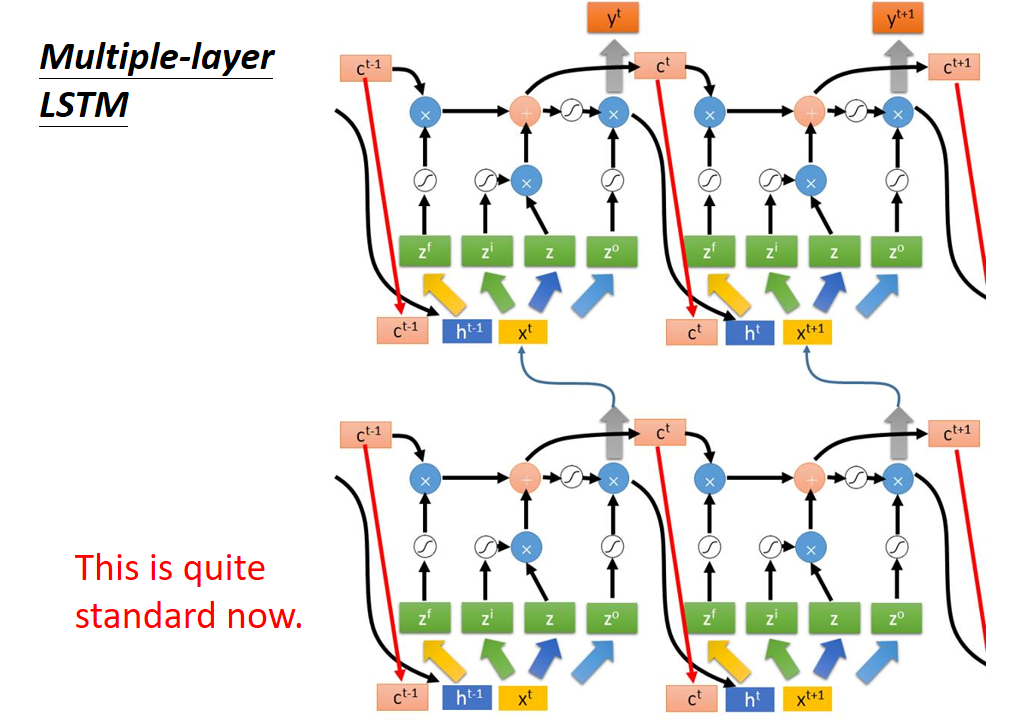
当前形式为标准形式
LSTM主要学习的什么呢?
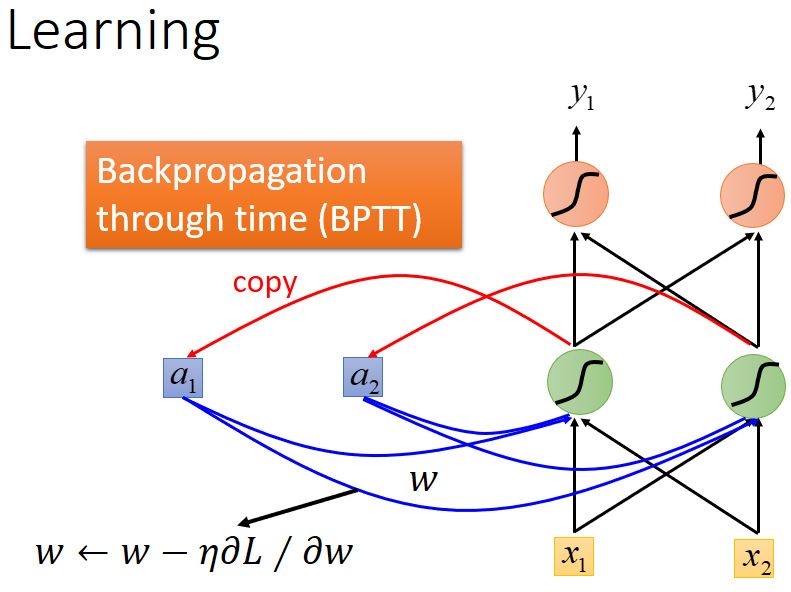
学习的主要是内存单元值回送至下一次内存中的权重值,如图中w值。
学习算法为:Back Propagation Through Time(BPTT)反向传播算法(算法原理稍后再讲)
然而基于以上讨论的RNN在实际训练过程中并不总是可以得到理想的结果,代价函数有时会出现巨大的波动,如下图所示:

主要是代价函数曲线误差面不是梯度消失就是梯度爆炸,如下图所示:
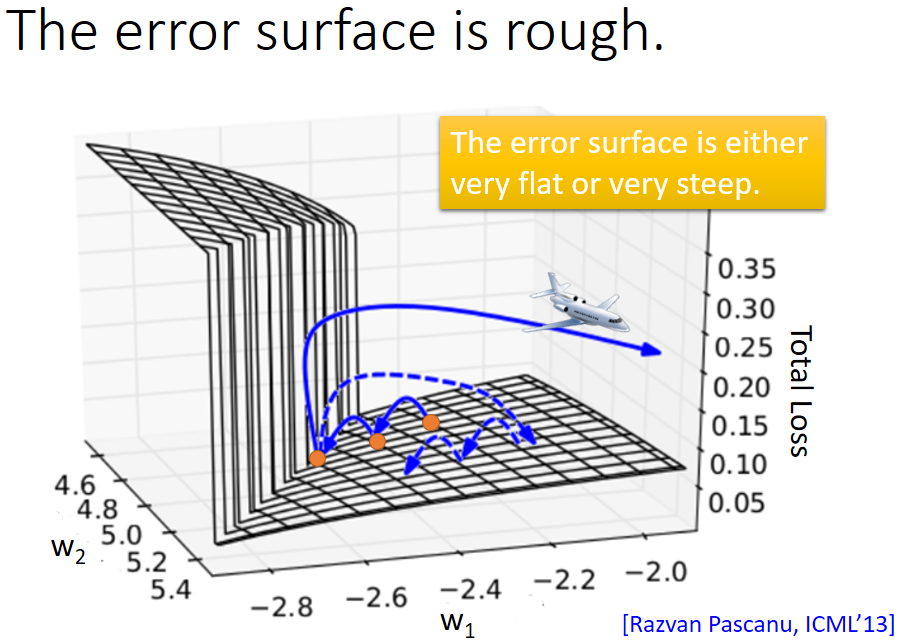
主要原因就是学习参数w导致,原因如下:
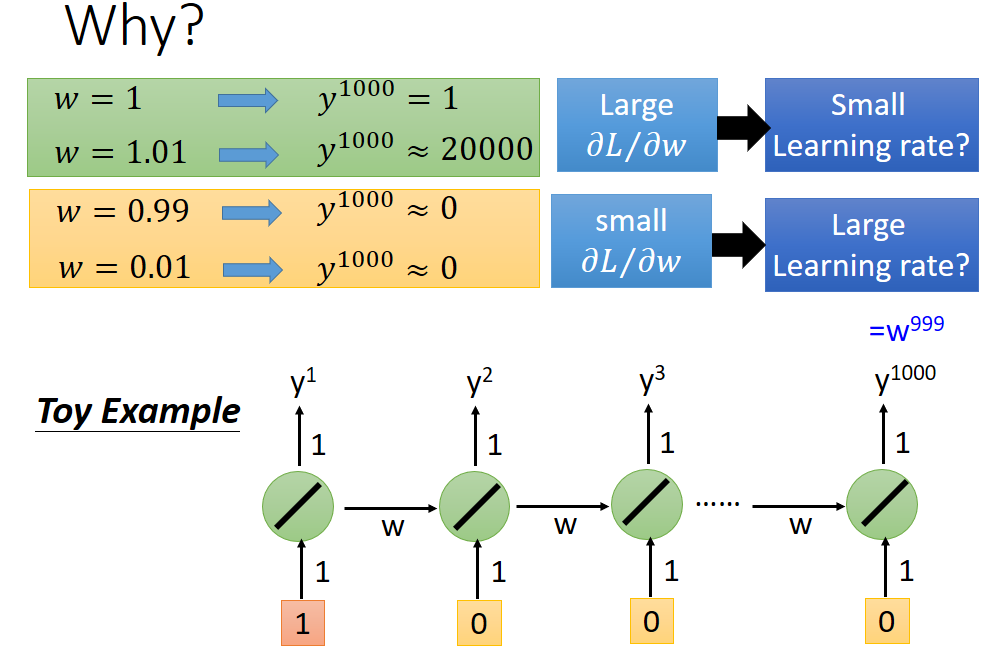
如果直接取w为1,即相当于将原始内存值直接加到新的内存中可以解决梯度消失问题,如下图所示:

因为w始终为恒定值1,所以基于上述图解

w=1时,输出就是输入值,而不会受到w的影响而改变,只要输入不为0,就不存在输出值y为0的情况,所以也就不会有梯度消失的情形。
w=1时的LSTM就是GRU单元。