循环神经网络与LSTM
是一个序列到序列的学习,他会生成一个序列squence
一.循环神经网络的结构
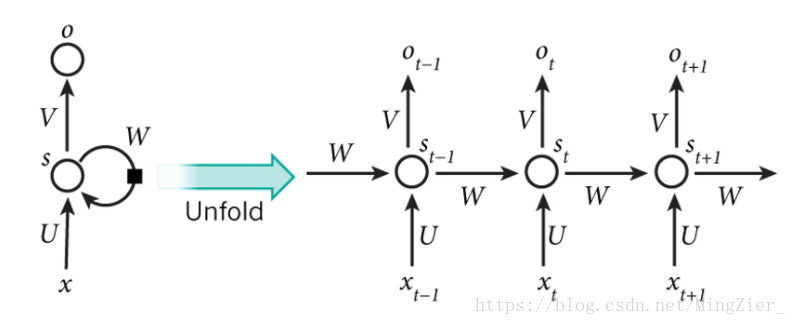
1.结构
❤unfold:展开
❤Xt是时间t处的输入
❤St是时间t处的“记忆”,St=f(UXt+WSt−1),f可以是tanh等
❤ Ot是时间t处的输出,比如是预测下个词的话,可能是 softmax输出的属于每个候选词的概率
❤拿我是中国人为例,假如Xt输入的是“中国”,那么Ot输出的就是“人”,那么St-1就是**隐状态也就是记忆体”**我是“
2.结构细节
❤可以把隐状态是视作“记忆体”,捕捉了之前时间点上的信息。
❤输出的Ot由当前时间及之前所有的“记忆”共同计算得到。
❤很可惜,实际应用中St并不能捕捉和保留之前所有信息.(LSTM来解决)
❤不同于CNN,RNN其实整个神经网络都共享一组参数(U,W,V),极大见笑了需要训练和预估的参数量。
❤图中的Ot在有些任务下是不存在的,比如文本情感分析,其实只需要最后的output结果就行。
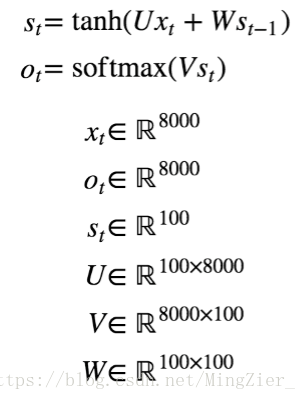
❤xt:一个长度为8000的向量[0,…,7999],one-hot形式
❤Ot:输出的是8000个词的概率
❤St:记忆体,100维
❤U:100行8000维
❤V:8000维100行
❤W:100行100维
二.不同的RNN
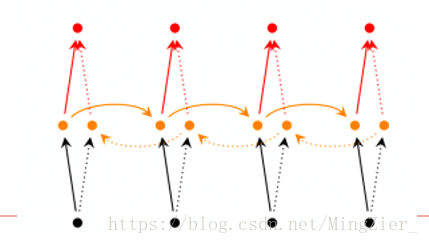
1.双向rnn
❤有些情况下,挡圈的输出不只依赖于之前的序列元素,还可以依赖之后的序列元素。
❤不如从一段话中踢掉部分词,让你补全。
❤直观理解:2个RNN叠加。
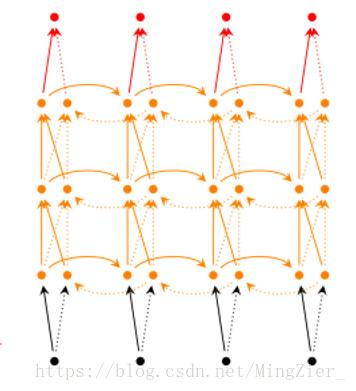
2.深层双向RNN
❤和双向rnn的区别是每一步/每个时间点我们设定多层结构
3.LSTM
❤前面提到的RNN解决了对之前的信息保存的问题 。 但是,存在长期依赖的问题。 比如看电影的时候,某些情节的推断需要依赖很久以前的 一些细节。 很多其他的任务也一样。 很可惜随着时间间隔不断增大时,RNN 会丧失学习到 连接如此远的信息的能力。也就是说,记忆容量有限,一本书从头到尾一字不漏 的去记,肯定离得越远的东西忘得越多。怎么办:LSTM
❤LSTM解决长期存在的问题。是RNN的一种,有选择的对记忆进行过滤和更新。
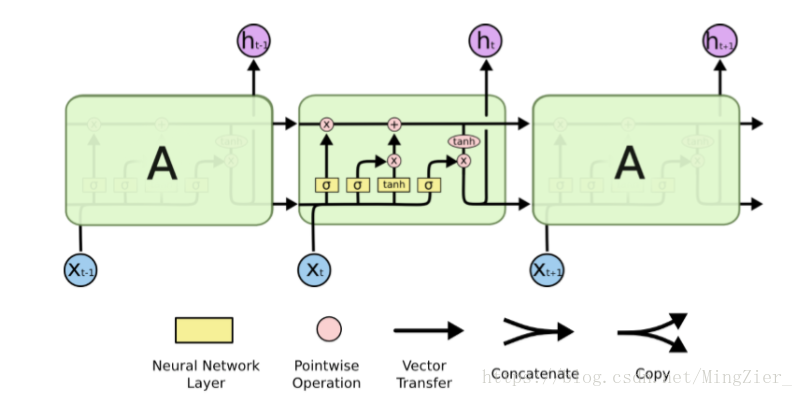
它的“记忆细胞”改造过。 该记的信息会一直传递,不该记的会被“门”截断。
包含一个sigmoid神经网络层 和 一个pointwise乘法操作
Sigmoid 层输出0到1之间的概率值,描述每个部分有多少量可以通过。 0代表“不许任何量通过”,1就指“允许任意量通过”
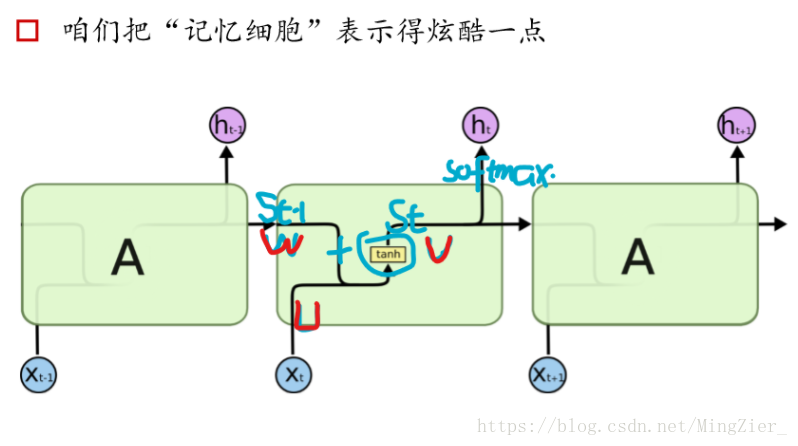
❤LSTM结构:像一个个黑箱子。每一步的权重都不同的。
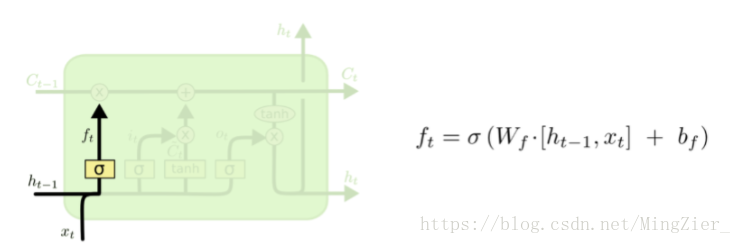
❤LSTM第一步:决定从细胞状态中丢弃什么信息,也就是“忘记门”
deta:也就是simoid函数,整个括号里面其实就是Wx+b;所以ft是0-1之间的,所以ft与Ct-1一相乘,就会筛掉不想要的东西。
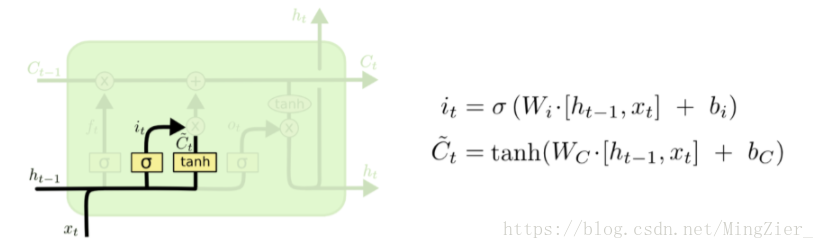
❤ LSTM第二步:决定放什么新信息到“细胞状态”中 , Sigmoid层决定什么值需要更新,Tanh层创建一个新的候选值向量Ct拔,it是确定哪部分信息要更新,有些信息不着急更新就不更新了;上述2步是为状态更新做准备 。
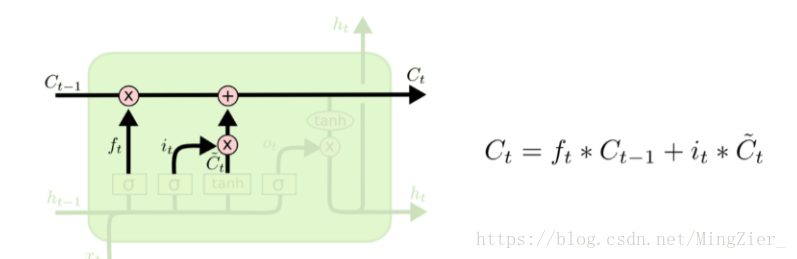
❤LSTM第三步:更新“细胞状态”
更新Ct-1为Ct,把旧状态与ft相乘,丢弃我们确定需要丢弃的信息,加上it*Ct拔,这就是新的候选值,根据我们决定更新每个状态的程度进行变化。
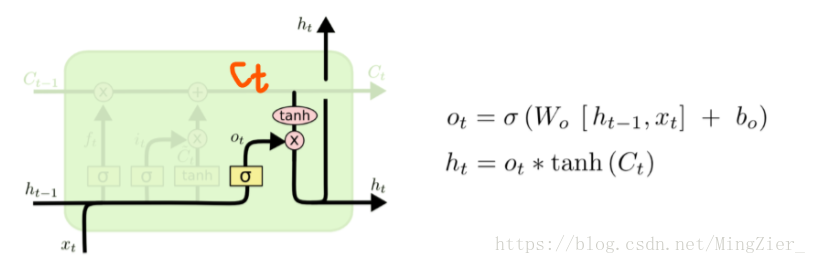
❤LSTM第四步:ht可以认为是当前时刻最后的输出,ht-1是t-1时刻的输出;ot是个概率向量,用来确定哪个部分是被输出的。
首先运行一个sigmoid 层来确定细胞状态的哪个部分将输出,接着用tanh处理细胞状态(得到一个在-1到1之间的值),再将它和 sigmoid门的输出相乘,输出我们确定输出的那部分。
deta: 比如我们可能需要单复数信息来确定输出“他”还是“他们”,0t的功能就在此
4.LSTM变体