
本文同步更新在我的微信公众号里,地址:https://mp.weixin.qq.com/s/IPyI2Ee6Kzyv3wFAUN7NOQ
本文同步更新在我的知乎专栏里,地址:https://zhuanlan.zhihu.com/p/43190710
目录
1. 基本循环神经网络
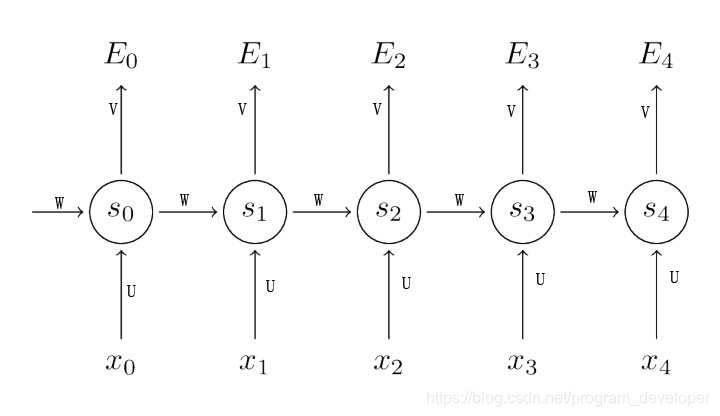
传统的神经网络模型是从输入层到隐含层再到输出层的全连接,且同层的节点之间是无连接,网络的传播也是顺序的,但这种普通的网络结构对于许多问题却显得无能为力。例如,在自然语言处理中,如果要预测下一个单词,就需要知道前面的部分单词,因为一个句子中的单词之间是相互联系的,即有语义。这就需要一种新的神经网络,即循环神经网络RNN,循环神经网络对于序列化的数据有很强的模型拟合能力。具体的结构为:循环神经网络在隐含层会对之前的信息进行存储记忆,然后输入到当前计算的隐含层单元中,也就是隐含层的内部节点不再是相互独立的,而是互相有消息传递。隐含层的输入不仅可以由两部分组成,输入层的输出和隐含层上一时刻的输出,即隐含层内的节点自连;隐含层的输入还可以由三部分组成,输入层的输出、隐含层上一时刻的输出、上一隐含层的状态,即隐含层内的节点不仅自连还互连。结构如图1所示。
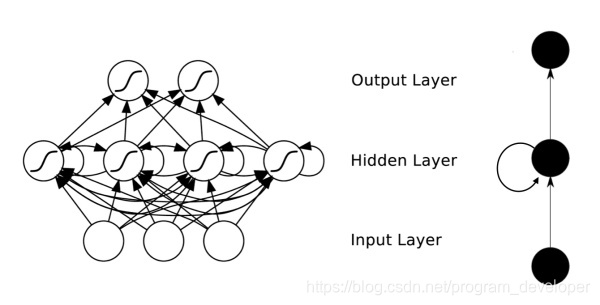
在图1中,可以看到隐含层节点间有消息的相互传递。为了更简单的理解,现在我们将RNN在时间坐标轴上展开成一个全神经网络,如图2所示。例如,对一个包含3个单词的语句,那么展开的网络便是一个有3层的神经网络,每一层代表一个单词。
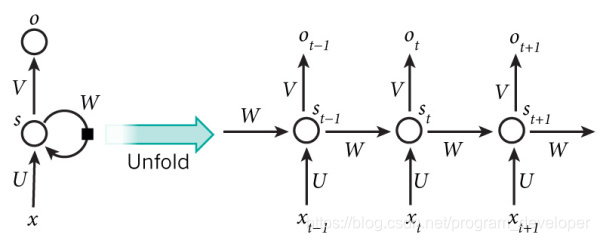
对于图2的网络,计算过程如下:
-
表示第
步(step)的输入。比如
为第二个词的词向量(
为第一个词);
-
为隐藏层的第t步的状态,它是网络的记忆单元。
进行计算,如公式1所示。其中,U是输入层的连接矩阵,W是上一时刻隐含层到下一时刻隐含层的权重矩阵,f(x)一般是非线性的激活函数,如tanh或ReLU。
(1)
是第t步的输出。输出层是全连接层,即它的每个节点和隐含层的每个节点都互相连接,V是输出层的连接矩阵,g(x)是激活函数。
(2)
如果将(1)式循环带入(2)式可得:
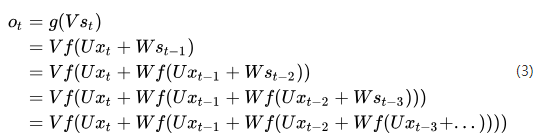
由式(3)可以看出,循环神经网络的输出值与前面多个时刻的历史输入值有关,这就是为何循环神经网络能够往前看任意多个输入值的原因,也就是为何循环神经网络能够对序列数据建模的原因。
在图2中,我们展示了一个单向循环神经网络,但是单向循环神经网络也有不足之处。从单向的结构中可以知道它的下一时刻预测输出是根据前面多个时刻的输入共同影响的,而有些时候预测可能需要由前面若干输入和后面若干输出共同决定,这样才会更加准确。
2. 双向循环神经网络
2.1 双向循环神经网络的介绍
对于语言模型来说,很多时候单向循环神经网络表现是不好的,比如下面这句话:
我的手机坏了,我打算____一部新手机。
可以想象,如果我们只看横线前面的词,手机坏了,那么我是打算修一修?换一部新的?还是大哭一场?这些都是无法确定的。但如果我们也看到了横线后面的词是『一部新手机』,那么,横线上的词填『买』的概率就大得多了。
对于上面的语言模型,单向循环神经网络是无法对此进行建模的。因此,我们需要用双向循环神经网络,如图3所示。
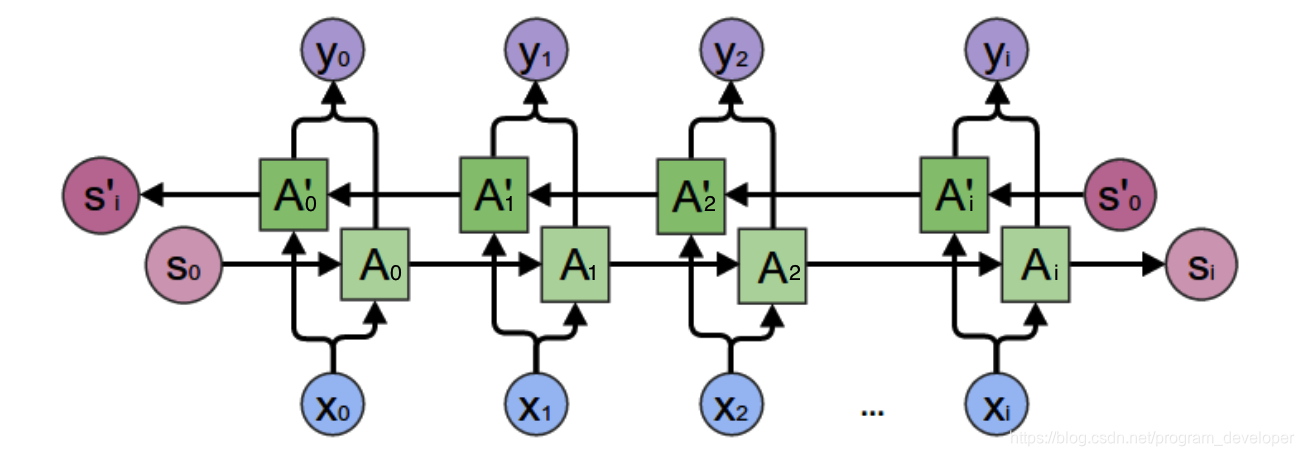
从图3中可以看出,双向循环神经网络的隐藏层要保存两个值,一个A参与正向计算,另一个值参与反向计算。我们以
的计算为例,推出循环神经网络的一般规律。最终的输出值
取决于
和
。其计算方式为公式4:
(4)
和
则分别计算为:
(5)
(6)
现在,我们已经可以看出一般的规律:正向计算时,隐藏层的值与
有关;反向计算时,隐藏层的值
与
有关;最终的输出取决于正向和反向计算的加和。现在,我们仿照式5和式6,写出双向循环神经网络的计算方法:
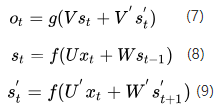
从上面三个公式我们可以看到,正向计算和反向计算不共享权重,也就是说U和U'、W和W'、V和V'都是不同的权重矩阵。
2.2 双向循环神经网络的训练
前向传播:
-
沿着时刻0到时刻i正向计算一遍,得到并保存每个时刻向前隐含层的输出。
-
沿着时刻i到时刻0反向计算一遍,得到并保存每个时刻向后隐含层的输出。
-
正向和反向都计算完所有输入时刻后,每个时刻根据向前向后隐含层得到最终输出。
反向传播:
-
计算所有时刻输出层的损失函数项。
-
根据所有输出层的损失函数项,使用 BPTT 算法更新向前层。
-
根据所有输出层的损失函数项,使用 BPTT 算法更新向后层。
3. 深度循环神经网络
上面介绍的基本循环神经网络和双向循环神经网络只有单个隐藏层,有时不能很好的学习数据内部关系,可以通过叠加多个隐藏层,形成深度循环神经网络结构。
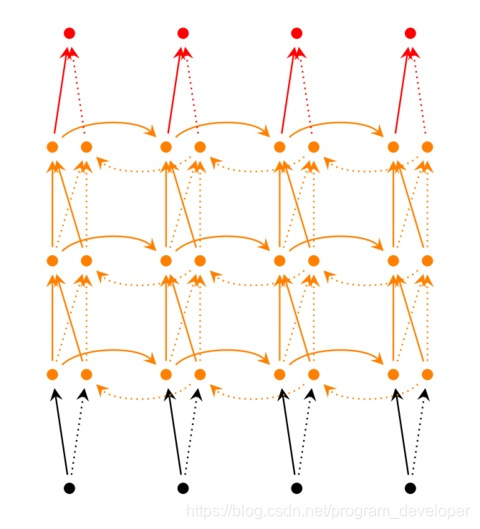
Deep (Bidirectional)RNN和Bidirectional RNN相似,只是在每个时刻会有多个隐藏层。在实际中会有更强的学习能力,但也需要更多的训练数据。
4. 循环神经网络的时间步长和参数共享
4.1 循环神经网络的time steps
time steps 就是循环神经网络认为每个输入数据与前多少个陆续输入的数据有联系。例如具有这样一段序列数据 “…ABCDBCEDF…”,当 time steps 为 3 时,在模型预测中如果输入数据为“D”,那么之前接收的数据如果为“B”和“C”则此时的预测输出为 B 的概率更大,之前接收的数据如果为“C”和“E”,则此时的预测输出为 F 的概率更大。
4.2 循环神经网络的参数共享
循环神经网络参数共享指的是:在每一个时间步上,所对应的参数是共享的。参数共享的目的有两个:一、用这些参数来捕获序列上的特征;二、共享参数减少模型的复杂度。
如图2所示,在RNN中每输入一步,每一层各自都共享参数U、V、W。其反映着RNN中每一时刻都在做相同的事情,只是输入不同,因此大大减少了网络中需要学习的参数。
对于RNN的参数共享,我们可以理解为对于一个句子或者文本,参数U可以看成是语法结构、参数W是一般规律,而下一个单词的预测必须是上一个单词和一般规律W与语法结构U共同作用的结果。我们知道,语法结构和一般规律在语言当中是共享的。所以,参数自然就是共享的!
CNN和RNN参数共享的区别:
我们需要记住的是,深度学习是怎么减少参数的,很大原因就是参数共享,而CNN是在空间上共享参数,RNN是在时间序列上共享参数。
循环神经网络中关于参数共享比较好的文章推荐:
【1】YJango的循环神经网络——介绍 - YJango的文章 - 知乎 https://zhuanlan.zhihu.com/p/24720659
【2】全面理解RNN及其不同架构 - Evan的文章 - 知乎 https://zhuanlan.zhihu.com/p/34152808
5. 循环神经网络的训练算法(BPTT)
RNN的反向传播算法为Backpropagation Through Time (BPTT)。让我们先回忆一下RNN的基本公式,注意到这里在符号上稍稍做了改变(变成
),这只是为了和我参考的一些资料保持一致。
同样把损失值定义为交叉熵损失,如下:
这里,表示时刻
正确的词,
是我们的预测。通常我们会把整个句子作为一个训练样本,所以总体误差是每一时刻的误差的累加和。
我们的目标是计算误差值相对于参数U, V, W的梯度以及用随机梯度下降学习好的参数。就像我们要把所有误差累加一样,我们同样会把每一时刻针对每个训练样本的梯度值相加:
为了计算梯度,我们使用链式求导法则,主要是用反向传播算法往后传播误差。下面我们使用作为例子,主要是为了描述方便。
上面,
是向量的外积。如果你不理解上面的公式,不要担心,我在这里对上面的推导过程进行补充。这里我想说明的一点是梯度值只依赖于当前时刻的结果
。根据这些,计算
的梯度就只剩下简单的矩阵乘积了。
补充上面式子推导过程:
上式中
求导结果,其实是Softmax函数求导结果。我这里直接给出Softmax求导结果:
当
i = j 时,
当
时,
所以,将Softmax求导结果代入(*)式:

但是对于梯度情况就不同了,我们可以像上面一样写出链式法则。
注意到这里的依赖于
,
依赖于
和
,等等。所以为了得到W的梯度,我们不能将
看作常量。我们需要再次使用链式法则,得到的结果如下:
我们把每一时刻得到的梯度值累加,换句话说,在计算输出的每一步中都使用了。我们需要通过将
时刻的梯度反向传播至
时刻。
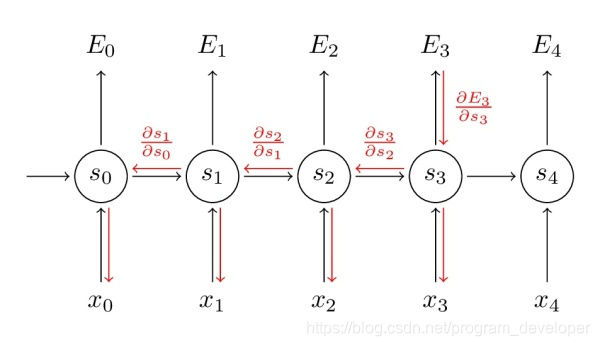
请注意,这与我们在深层前馈神经网络中使用的标准反向传播算法是完全相同的。关键的区别是,我们把每一时刻针对的不同梯度做了累加。在传统的神经网络中,我们不需要跨层共享权重,所以不需要求和。但在我看来,BPTT是应用于展开的RNN上的标准反向传播的另一个名字。就像反向传播一样,你也可以定义一个反向传递的delta向量,例如,
,其中
通过以上的推导,我们可以得出结论:
RNN很难训练的原因是:序列(句子)可能很长,可能是20个单词或更多,因此需要在许多层中进行反向传播。在实践中,许多人限定反向传播为有限的步骤(也是因为有梯度消失的问题存在)。
本部分参考文章:
【1】循环神经网络教程第三部分-BPTT和梯度消失 - 徐志强的文章 - 知乎 https://zhuanlan.zhihu.com/p/22338087
6. RNN的梯度消失和梯度爆炸
上面我们讲到的单向循环神经网络、双向循环神经网络和深度循环神经网络都是传统的循环神经网络。这些传统的循环神经网络在学习过程中容易出现梯度消失和梯度爆炸的现象。所谓的梯度消失是指:信息在反向传播时误差减小为0;而梯度爆炸是指:信息在反向传播时误差呈指数增长。下面,我们来深入的了解一下循环神经网络中产生梯度消失和梯度爆炸的本质原因。
6.1 梯度消失
RNN很难学到长范围的依赖-即相隔几步的词之间的联系。传统的RNN不能捕获长距离词之间的关系。要理解为什么,让我们先仔细看一下下面计算的梯度:
注意到也需要使用链式法则。例如,
。注意到因为我们是用向量函数对向量求导数,结果是一个矩阵(称为Jacobian Matrix),矩阵元素是每个点的导数。我们可以把上面的梯度重写成:
可以证明上面的Jacobian矩阵的二范数(可以认为是一个绝对值)的上界是1。这很直观,因为激活函数把所有值映射到-1和1之间,导数值得界限也是1。
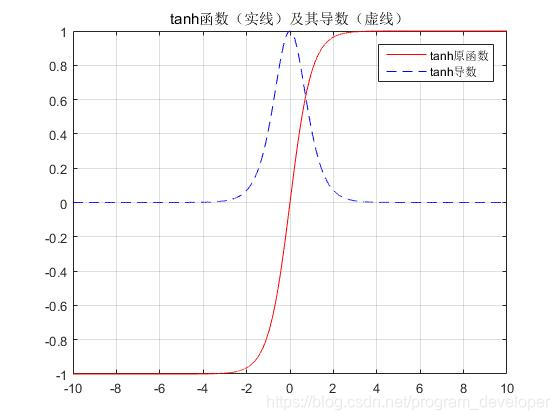
从图7中我们可以看到,tanh函数在x趋近于无穷大和无穷小时梯度值都为0。当这种情况出现时,我们就认为相应的神经元饱和。它们的梯度为0使得前面层的梯度也为0,因为前面层的梯度是由后面层的梯度连乘得到的。梯度中存在比较小的值,多个梯度相乘会使梯度值以指数级速度下降,最终在反向传播几步后就完全消失。比较远的时刻的梯度值为0,这些时刻的状态对学习过程没有帮助,导致你无法学习到长距离依赖。梯度消息问题不仅出现在RNN中,同样也出现在深度前向神经网中。只是RNN网络通常比较深,使得这个问题更加普遍。
6.2 梯度爆炸
RNN的学习依赖于我们的激活函数和网络初始参数,如果Jacobian矩阵中的值太大,会产生梯度爆炸而不是梯度消失问题。梯度消失比梯度爆炸受到了更多的关注有两方面的原因。其一,梯度爆炸容易发现,梯度值会变成NaN,导致程序崩溃。其二,用预定义的阈值裁剪梯度可以简单有效的解决梯度爆炸问题。梯度消失问题就不容易发现并且也不好处理,这也是梯度消失比梯度爆炸受到学术界更多关注的原因。
7. RNN的Long-Term依赖问题
上面我们讲到的循环神经网络梯度消失问题在RNN中会造成不能Long-Term依赖问题。
例如,考虑一个语言模型试图基于先前的词预测下一个词。如果我们要预测“the clouds are in the sky”,我们不需要其它更遥远的上下文信息就能预测出下一个词应该是sky。在这样的例子中,句子长度很小,相关信息和预测单词的距离很小,RNN可以学着去使用过去的信息。
但是,在大部分情况下我们需要更多的上下文信息。考虑预测这个句子中最后一个词:“I grew up in France… I speak fluent French.” 最近的信息表明下一个词可能是一种语言的名字,但如果我们想要找出是哪种语言,我们需要从更久远的地方获取France的上下文。相关信息和预测单词之间的距离完全可能是非常巨大的。而不幸的是,随着距离的增大,RNN会产生梯度消失的问题,造成不能够连接更长的上下文信息。
8. RNN的几种架构
由于RNN对于序列化的数据有很强的模型拟合能力,因此在不同的应用场景中可以对RNN组合形成不同的网络架构。
8.1 1 to 1

图8是普通的单个神经网络,由于图8模型过于简单,在实际的场景中没有什么应用价值。但是对于我们学习RNN的模型来说,它是最基本的也是最好理解的。
8.2 1 to N
这种情况有两种方式,一种是只在序列开始进行输入计算:
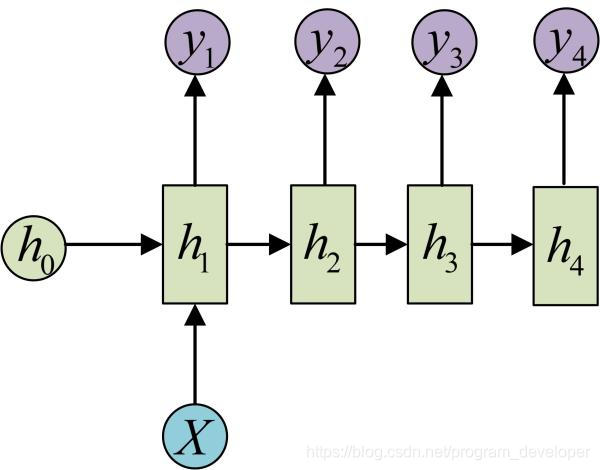
还有一种结构是把输入信息X作为每个阶段的输入:
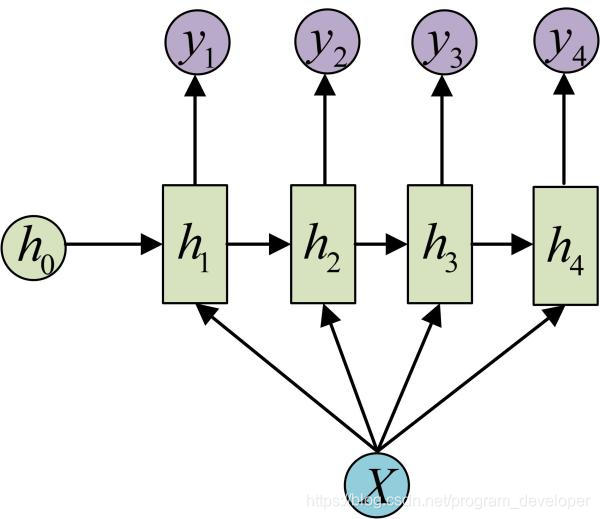
这种1 to N的结构可以处理的问题有很多,比如图像标注,输入的X是图像的特征,而输出的y序列是一段句子。
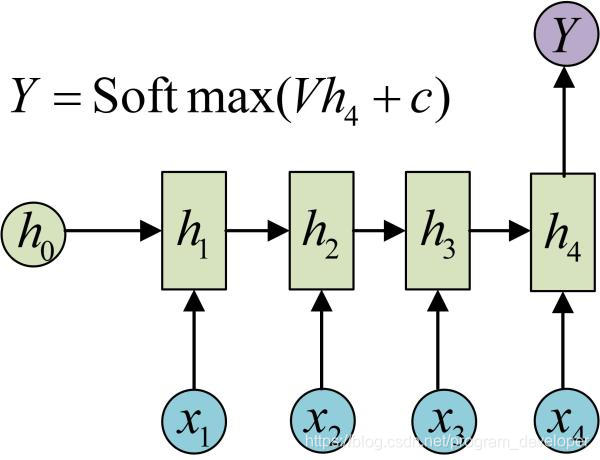
8.3 N to 1
输入是一个序列,输出是一个单独的值而不是序列。这种结构通常用来处理序列分类问题。如输入一段文字判别它所属的类别,输入一个句子判断其情感倾向,输入一段文档并判断它的类别等等。具体如图11:
8.4 N to N
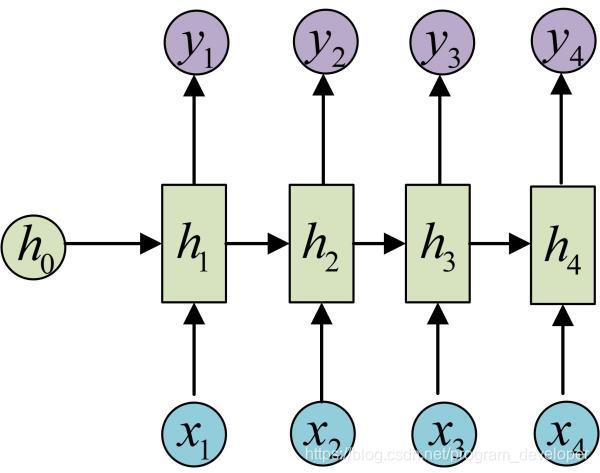
输入和输出序列是等长的。这种可以作为简单的Char RNN可以用来生成文章,诗歌,甚至是代码,非常有意思。
8.5 N to M
这种结构又叫Encoder-Decoder模型,也称之为Seq2Seq模型。在现实问题中,我们遇到的大部分序列都是不等长的。如机器翻译中,源语言和目标语言的句子往往并没有相同的长度。而Encoder-Decoder结构先将输入数据编码成一个上下文向量c,之后在通过这个上下文向量输出预测序列。
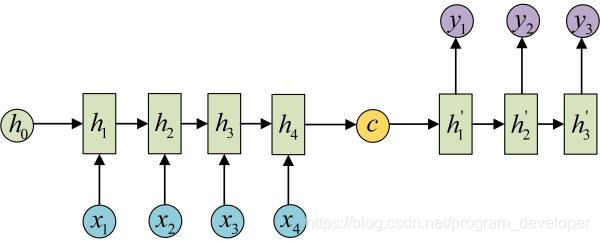
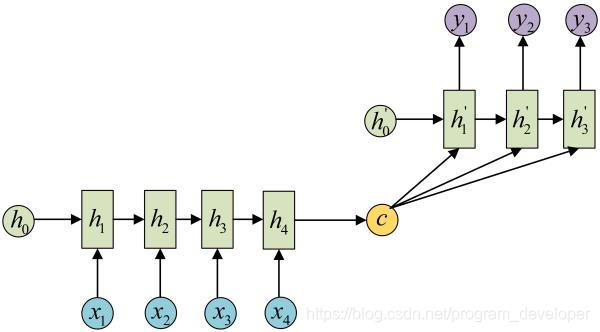
注意,很多时候只用上下文向量C效果并不是很好,而attention机制很大程度弥补了这点。seq2seq的应用的范围非常广泛,机器翻译,文本摘要,阅读理解,对话生成等等。
Reference
【1】 零基础入门深度学习(5) - 循环神经网络
地址:https://zybuluo.com/hanbingtao/note/541458
【2】 全面理解RNN及其不同架构
地址:https://zhuanlan.zhihu.com/p/34152808
【3】完全图解RNN、RNN变体、Seq2Seq、Attention机制
地址:https://zhuanlan.zhihu.com/p/28054589
【4】循环神经网络教程第一部分-RNN简介
地址:https://zhuanlan.zhihu.com/p/22266022
【5】Understanding LSTM Networks
地址:http://colah.github.io/posts/2015-08-Understanding-LSTMs/
【6】]YJango的循环神经网络——介绍 - YJango的文章 - 知乎
地址:https://zhuanlan.zhihu.com/p/24720659
【7】循环神经网络教程第三部分-BPTT和梯度消失 - 徐志强的文章 - 知乎
地址:https://zhuanlan.zhihu.com/p/22338087
【8】循环神经网络(RNN)介绍3:RNN的反向传播算法Backpropagation Through Time (BPTT) - 刘博的文章 - 知乎
地址:https://zhuanlan.zhihu.com/p/32930648
