神经网络 第1部分:建立架构
这一部分主要讨论神经网络的来源和架构,包括:
- 建模一个神经元
- 神经网络架构
1.建模一个神经元
神经网络领域源自于渴望建立生物神经系统模型的目的,但是后来转变为使用在工程领域和在机器学习任务中取得好的效果。下面非常简单的介绍一下生物神经系统:
生物学动机
大脑最基本的计算单位叫做神经元(neuron),人类的神经系统中有大概有860亿各神经元,它们通过10^14到10^15个突触(synapse) 相互连接。每个神经元通过多个树突(dendrite)接收信号,然后通过一个轴突(axon)发送信号,轴突通过突触和其它神经元的树突相连。下面的图片简单描述了一个生物神经元。
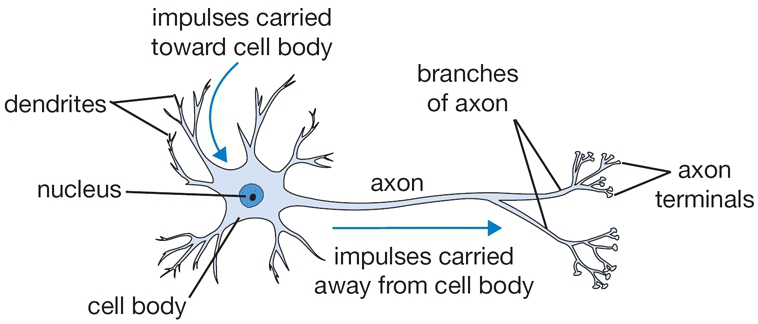
一个神经元通过多个树突接收信号并将这些信号进行处理计算,结果如果超过一定的阈值,则通过轴突将信号发送给下一个神经元。真正的生物神经元是非常复杂的,将其简化的数学模型如下:

代表上一个神经元发送过来的信号, 代表一个树突上的权值, 代表神经元对这些信号的处理计算,然后通过激活函数 来判断结果 是否达到阈值并将信号发送到下一个神经元。
神经元和线性分类器
神经元的简化数学模型似曾相识,一个单独的神经元就像一个二元分类器(比如二元Softmax或者二元SVM)。
二元Softmax分类器:
二元SVM分类器:
正则化项:正则化项在生物学上的解释为逐渐遗忘,它会使参数更新时权值 逐渐减小。

常用的激活函数
激活函数使用固定的步骤处理一个标量数字,下面介绍几个实践中使用的激活函数:
Sigmoid
Sigmoid函数的形式为:
,它将数值压缩到0到1之间。
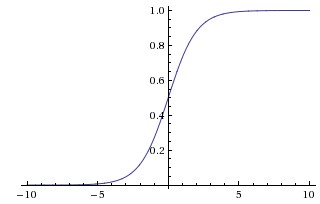
Sigmoid函数如上图所示,它的缺点为:
- Sigmoid函数在取值为0和1处趋近饱和,这些地方导数基本为0,使得在BP时梯度消失。
- Sigmoid函数的输出不是不是以0为中心的。(在下一篇中数据预处理中提到)
Tanh
Tanh函数可以由Sigmoid函数变换得到,形式为:
。
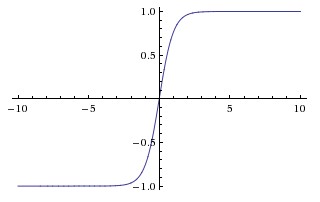
Tanh函数也是饱和函数,但是它是以0为中心的。
ReLU
今年来最流行的激活函数,形式为
。
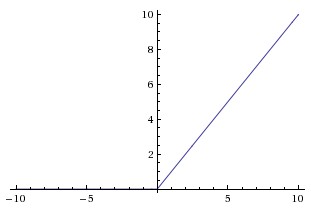
RuLU简单的将0作为阈值,但是有许多优点:
- 由于RuLU的线性和非饱和形式,求导为1不会放大缩小梯度,可以极大加速SGD的收敛。
- 相比Sigmoid和Tanh,RuLU计算非常简单。
RuLU也有一个缺点:
- 可能会使神经元“死亡”,因为它将所有负输出变为0。所以当学习率比较高时,会使梯度永远为0,这个问题可以用调整学习率来降低“死亡”的几率。
Leaky ReLU
Leaky ReLU是为了解决ReLU的神经元死亡问题,形式为:
,
为很小的常数。但是它的改进效果尚不清楚。
小结:
推荐使用ReLU,恰当的设置学习率并监控神经元“死亡”的问题。不要使用Sigmoid或Tanh,就算使用性能也不会比ReLU好。
2.神经网络架构
分层组织
神经网络被建模成一组神经元组成的有向无环图,最常见的是全连接神经网络,如下图所示:
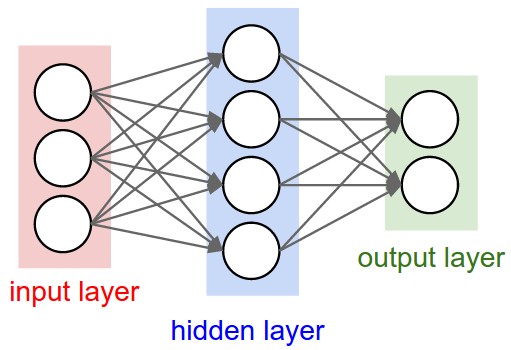
二层全连接网络: 1个输入层,1个隐层,1个输出层。

三层全连接网络: 1个输入层,2个隐层,1个输出层。
命名规定 神经网络的层数一般不包括输入层,计算规模不包括输入神经元。
输出层 输出层一般没有激活函数,它的输出代表类型评分(分类)或者一个实值(回归)。
神经网络规模 一般用神经元的个数(参数个数)来表示神经网络的规模。
上面两个图的规模分别为:
- 二层全连接网络 [4+2]=6个神经元,[3x4]+[4x2]=20个权值,4+2=6个偏差,26个可学习参数。
- 三层全连接网络 4+4+1=9个神经元,[3x4]+[4x4]+[4x1]=32个权值,4+4+1=9个偏差,41个可学习参数。
前馈计算实例
神经网络模型是重复的矩阵计算交织激活函数,使用ReLU的简单表示为 ,采用这种结构的主要原因是结构简单并有利于计算。
拿上面的三层全连接网络来举例,它的输入层是一个[1x3]的向量x。两层之间的权值可以储存在一个矩阵中,例如第一隐层的权值W1为一个[3x4]的矩阵,偏差b1为一个[1x4]的向量,每一个神经元拥有W1中的一列作为自己的权值,所有神经元的偏差在[1x4]的向量b1中,所以整层输出为x.dot(W1)+b1。以此类推这个网络的正向代码如下所示:
f = lambda x: np.maximum(0,x) # 激活函数ReLU
x = np.random.randn(1, 3) # 随机输入 (1x3)
h1 = f(x.dot(W1) + b1) # 计算第一隐层的输出 (1x4)
h2 = f(h1.dot(W2) + b2) # 计算第二隐层的输出 (1x4)
out = h2.dot(W3) + b3 # 输出层 (1x1)
上述代码中W1,W2,W3,b1,b2,b3为网络中待学习的参数,x在实际应用中可以包括多行数据同时进行处理。需要注意输出层没有激活函数。
表达能力
一个很自然的问题是神经网络能够拟合哪些函数?1989年发表的Approximation by Superpositions of Sigmoidal Function证明了单隐层的神经网络可以逼近任何函数。
设置层数和层的规模
我们在面对实际问题时如何选择构建网络的层数和每层的规模?下图是一个二分类问题选择不同隐层层数的分类效果:
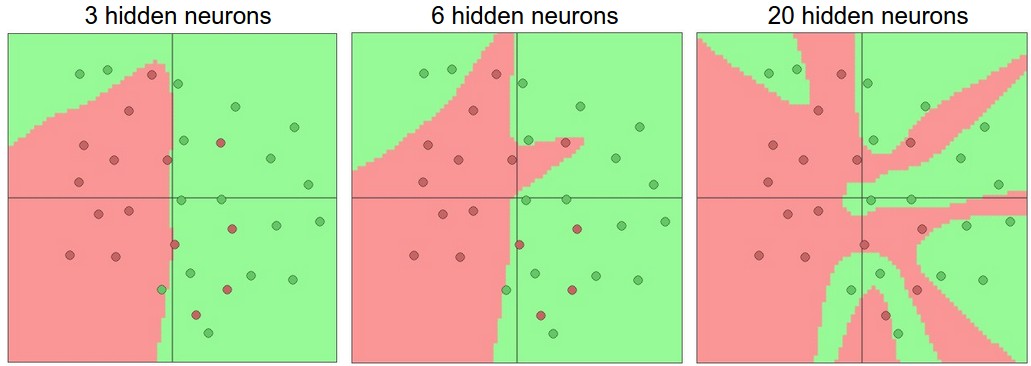
从图中可以看出,越大的网络越能表示更复杂的细节,但是也越可能过拟合。尽管如此,在实践中还是最好用抑制过拟合的方法(如L2范数正则化,随机失活等)而不是减小网络规模来防止过拟合。
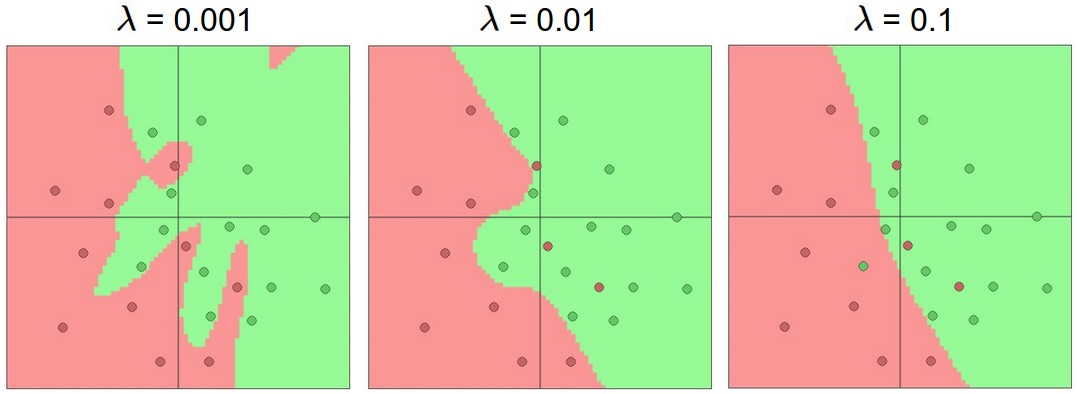
上图 为正则化项的系数,可以看出加大正则化项可以有效防止过拟合。
大网络比小网络好还有一个微妙的原因,神经网络是非凸的有很多局部最小值,大网络在随机初始化参数上拼运气的成份小一些。
总结
- 非常简化的介绍生物神经元
- 最常用的激活函数是ReLU
- 神经网络模型采用矩阵相乘和应用激活函数相交织的方式建立
- 神经网络能表达任何函数
- 大网络总是比小网络表现好
© 2018 by 0ne.tech