cs231n (五)神经网络part 1 构建架构
标签(空格分隔): 神经网络
文章目录
0.回顾
cs231n (一)图像分类识别讲了KNN
cs231n (二)讲了线性分类器:SVM和SoftMax
cs231n (三)优化问题及方法
cs231n (四)反向传播
1. 引言
千呼万唤始出来,晕死大佬一大片,终于到了构建神经网络的部分了,一个字:干!
好嘞,咱们开始第一次的神经网络构建呗!!!
咳咳咳…说到第一次啊,大家都比较兴奋,又拘谨,不好意思,跑题了啊。
从一般优化方法到线性分类器,再到直接使用数学定义解决优化问题,再到简单(lan de)高效的反向传播。
关于之前我们掌握的具体点就是:在之前的CIFAR-10case中,输入是 x = [3072x1], W = [10x3072], 所以我们知道这解决的是一个10分类问题。
- 现在不同了,神经网络是:
其中 W1:一个 NxD 的矩阵,比如:100x3072, 把 图像转化为 100维的中间向量,矩阵W2是:[10x100], 所以最终得到的就是10个数字,对应十个类别。
至于函数 你把它想成激活函数,如果不理解,不要紧,先放着,可能你也猜到了,这类似一个二层的神经网络。
- 那么类比一下,三层的神经网络就好比:
其中W1, W2, W3, 是需要进行学习的参数.
怎么学习这参数?
别急哇,你先理解了,接着往下看。

2. 构建一个神经元
1. 生物启发下?
对的,大脑就是用神经元计算的, 看看下图:左边是我们,右边是电脑
我们是突出电流信号是否激活,而电脑是激活函数,聪明!
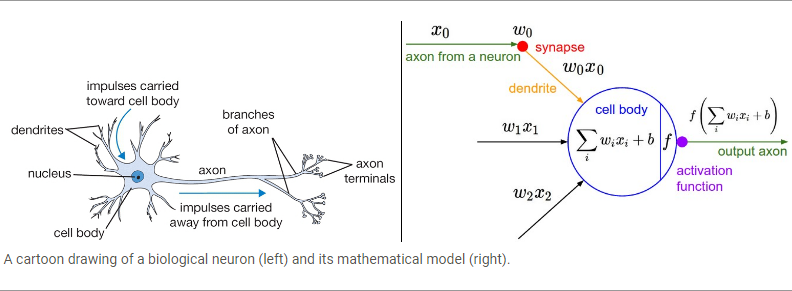
一个大概的前向传播的代码就这个样子, 这里用的激活函数就是sigmoid 函数
class Neuron(object):
# ...
def forward(self, inputs):
""" assume inputs and weights are 1-D numpy arrays and bias is a number """
cell_body_sum = np.sum(inputs * self.weights) + self.bias
firing_rate = 1.0 / (1.0 + math.exp(-cell_body_sum)) # sigmoid activation function
return firing_rate
个人观点:我根本不认为人类可以用机器模拟人脑,现在人类造一个没什么细胞器的红细胞都费劲啊, 别说是人脑了,探索糖类如何进出细胞都能得个诺贝尔,想想人类在生物医学上看到的还只是冰山一角。
下面这俩是神经科学的进展情况。
Dendritic Computation
Current Opinion in Neurobiology
2. 线性分类的单个神经元
二分类的Softmax 和SVM 我们已经学过了,他们都是将输出限制在1内,然后取阈值。
伴随他们的还有就是惩罚项:其实就是 正则化啦~
3. 常用的激活函数
一个是老生常谈的Sigmoid 把数值压缩到 [0, 1]
另一个是 tanh 把数值压缩到 [-1, 1]
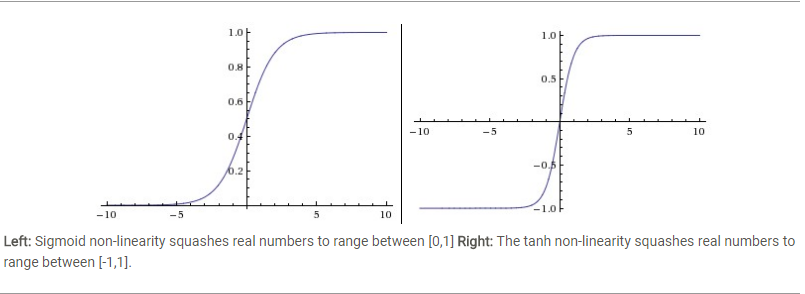
Sigmoid很少用了:因为它缺心眼啊
- 函数饱和导致梯度消失,看图嘛,就是靠近1,和0的那些地方,因为这些地方梯度几乎是零,
所以很小的数×很小的数=0, 为了防止饱和,初始化权重不能太大。 - 它的输出中心不是0, 网络越深得到的数值就不是零中心,所以梯度下降会中止,如果批量梯度下降可以一定程度减轻这个问题。
Tanh也存在饱和问题,但他的输出是零中心的,它好像吃胖的sigmoid函数
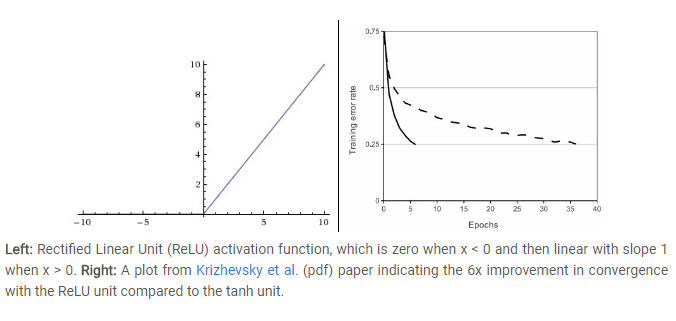
左边是ReLU(校正线性单元:Rectified Linear Unit)
右边是:使用ReLU比使用tanh的收敛快6倍的说明图
**ReLU:**它的函数 f(x)=max(0,x),
优点是:
- 收敛加速呗,因为它是线性并且非饱和的。
- 不耗费计算资源,因为你想哇, 直接取大于零的数值就ok。
缺点是: - 神经元死掉,就是一部分神经元不能激活,可以通过学习率的设置改变这种状况
Leaky ReLU: 专为ReLU死亡而生,做了一个改变就是:x < 0, 则 y = 0.01这样一个比较小的值,而不是零。
其中: 是一个比较小的的常量
Maxout: 人家不用这个 函数形式来作为神经元输出了,他是由谷歌提出的,归纳ReLU和leaky ReLU得到: , (ReLU:当 ), 但是这样他的参数数量会猛增。
**注意:**很少混合使用不同类型的神经元,你要使用哪个取决于各个神经元的激活函数的优缺点。
3. 神经网络的结构是啥样子的嘞?
1. 分层可视化
神经元的过程图示出来: 通常说的就是全连接层,看下面的两个例子
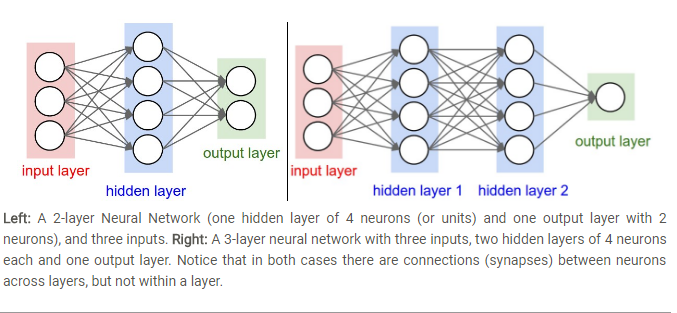
需要注意的一点就是: 同层之间的神经元相互不连接。
规则: 我说十层神经网络(ANN,MLP-Multi-Layer Perceptrons),我是不计算输入层的,单层就是输入直接到输出
输出: 输出是没有激活函数作用的。
网络规模: 由两个因素决定 1. 神经元个数 2. 参数个数,比如:
- 网络一:4+2=6神经元,[3x4]+[4x2]=20 权重,4+2=6个偏置,一共26可学习参数
- 4+4+1=9神经元, [3x4]+[4x4]+[4x1]=32权重,4+4+1=9偏置,共41可学习的参数。
2. 给前向传播举个例子吧
使用上述的三层神经网络举个例子:
# forward-pass of a 3-layer neural network:
f = lambda x: 1.0/(1.0 + np.exp(-x)) # activation function (use sigmoid)
x = np.random.randn(3, 1) # random input vector of three numbers (3x1)
h1 = f(np.dot(W1, x) + b1) # calculate first hidden layer activations (4x1)
h2 = f(np.dot(W2, h1) + b2) # calculate second hidden layer activations (4x1)
out = np.dot(W3, h2) + b3 # output neuron (1x1)
W1,W2,W3,b1,b2,b3 要学习的参数。
这里x不是单独的列向量,而是一个批量的训练数据(每个输入样本是x中的一列)
3. 网络的表达能力
其实就是神经网络的意义呗:
可认为它定义了一个由一系列函数组成的函数家族(想想一下泰勒级数,恩类似,或者傅里叶变换),网络权重就是每个函数的参数咯,那么这么一堆函数表达能力如何嘞?有例外没?
1989年的论文Approximation by Superpositions of Sigmoidal Function
Michael Nielsen的解释
说明只要有一个隐含层就可以近似任何函数,那么为什么还有深度学习嘞?
还不是浅层的不行啊,毛爷爷说过:实践时检验真理的唯一标准
更多研究:
Deep Learning的Chapter6.4
Do Deep Nets Really Need to be Deep?
FitNets: Hints for Thin Deep Nets
4. 层数和尺寸怎么设置呢?
层和数量多了,这个网络的表达能力一定程度上是增强了:下图是同层不同元。
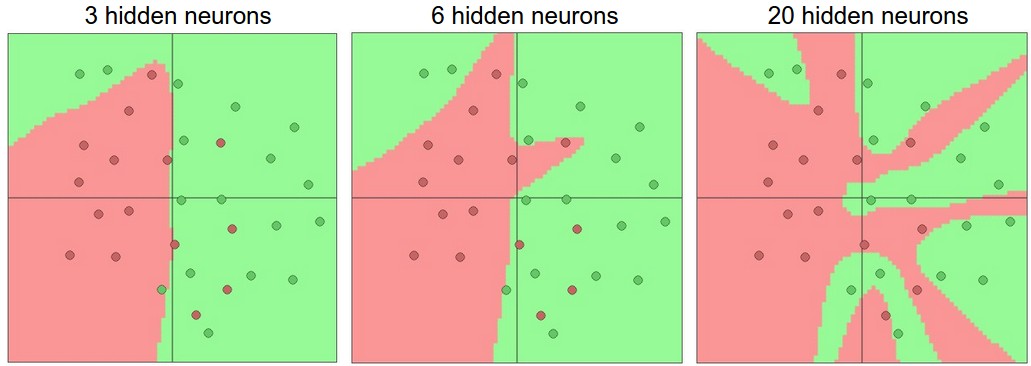
其实就是数据不复杂就不需要太大的网络,网络要大点的主要原因还是:
小网络更难用梯度下降等局部方法来训练
使用正则化也是一个很好的控制过拟合的办法:
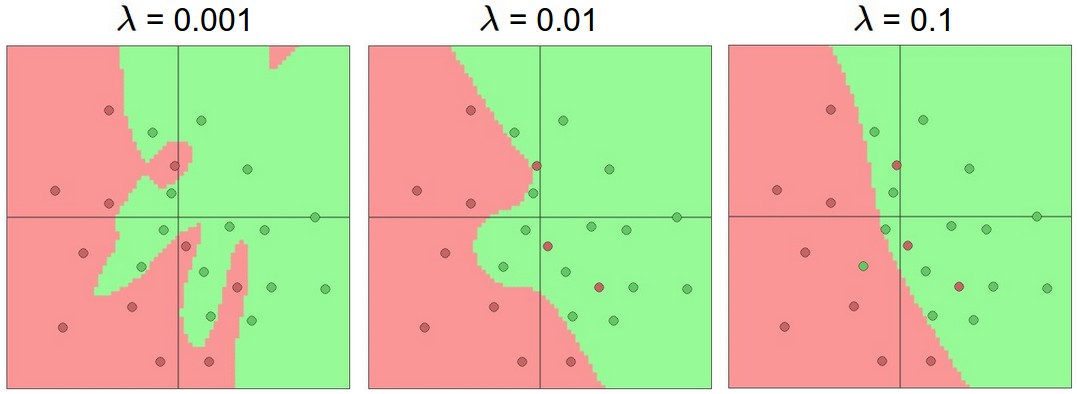
每个神经网络20个隐层神经元,随着正则化强度递增,决策边界变得更丝滑,就是这么丝滑。
4. 总结
- 对于激活函数ReLU是比较好的
- 神经网络的基本结构
- 神经网络可以拟合近似几乎所有的函数
- 关于设计,还是使用大的神经网络吧,最后可以使用正则化来调整比如:Dropout