神经网络训练细节part1上
-
训练过程
-
激活函数
- 数据预处理
训练过程
- 取一个batch数据
- 将数据延着网络前向传播,计算每个单元的输出和损失
- 将梯度依据链式法则延网络反向传播
- 根据梯度更新参数
激活函数
- Sigmoid
- tanh
- ReLU
- Leaky ReLU
- PReLU
- Maxout
- ELU
Sigmoid
(挤压函数)函数图像:
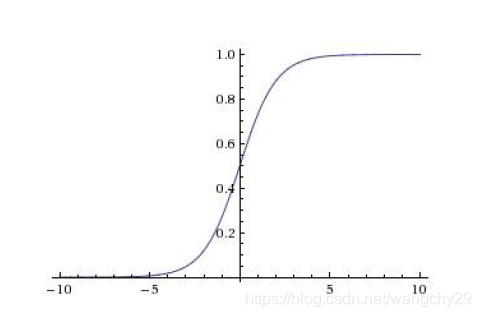
特点:输出在[0,1]之间
问题:
(1)神经元饱和导致梯度消失。在输入值很大或很小的时候输出要么接近0要么接近1,在反向传播过程中梯度会是0,梯度消失。当神经网络较大时,而且很多神经元处于饱和状态,就导致网络无法进行反向传播。
(2)函数输出不是关于原点中心对称的。即激活函数为f,函数输入为,当输入全为正值时,权值的梯度为
,所以当x为正时,权值的梯度的符号只取决于
所以w的权值都同号,要么全为负值要么全为正值。如果输入全为负值也是类似的道理。所以梯度更新在下图绿色部分,但是如果数据不是全为正值或负值时,权值更新就是红色路径,收敛缓慢。输入数据不是中心对称的时候,收敛速度慢。希望输入数据是关于原点中心对称的,输出也是关于原点中心对称的。
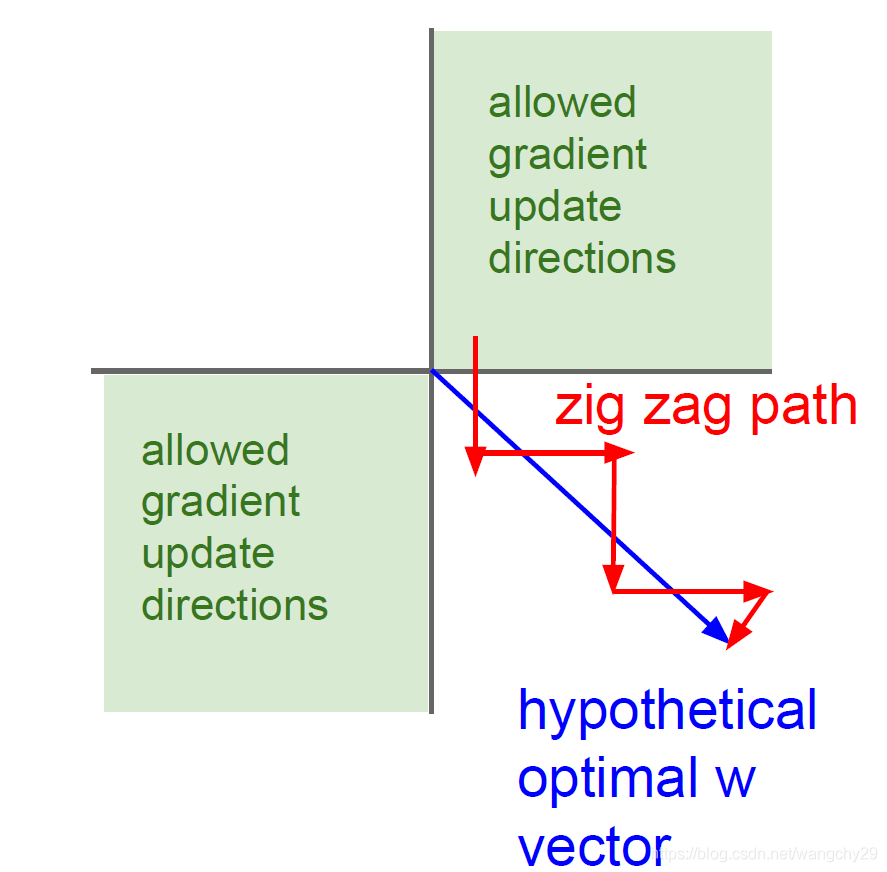
(3)指数计算比较耗时。
tanh
函数图像:
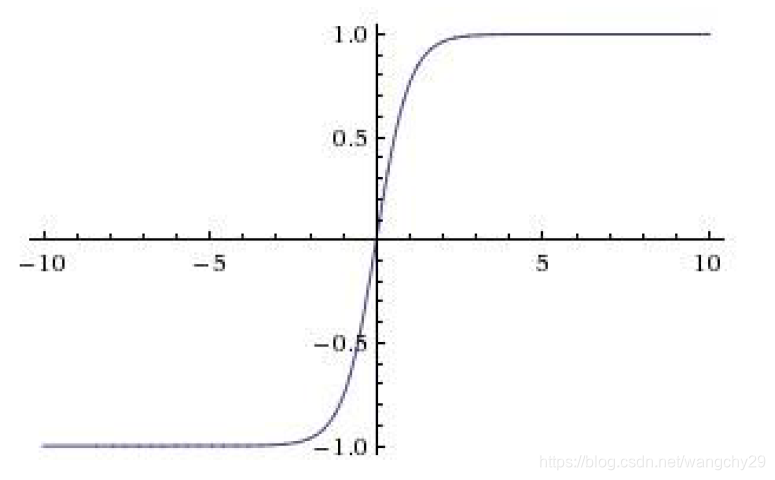
特点:(1)输出函数范围[-1,1]。(2)关于原点中心对称的。
问题:在输入数据很大或很小的时候仍然会发生神经元饱和梯度消失的情况。
ReLU
也称为修正线性函数
函数图像:
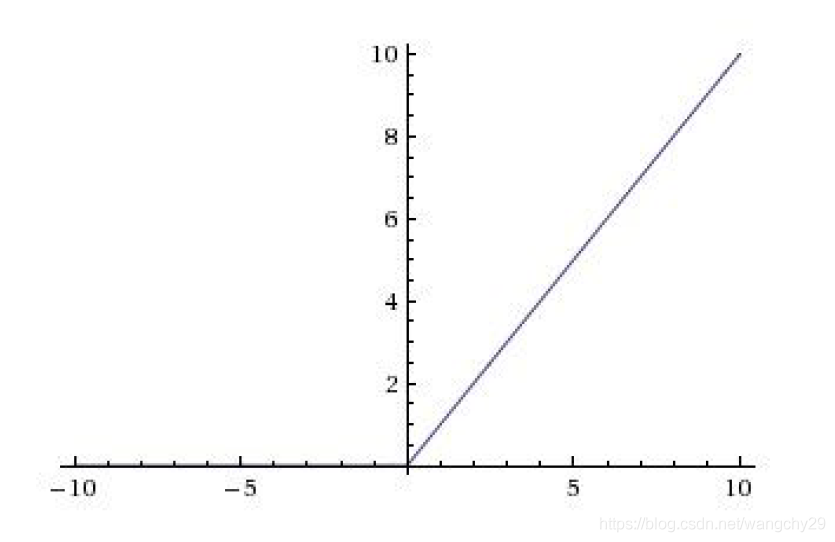
特点:(1)在输入数据为正时不会发现神经元饱和梯度消失的情况。(2)计算效率高。(3)收敛速度比tanh和sigmoid快。
问题:(1)也不是关于原点中心对称的。(2)在输入时负值时仍然会出现神经元饱和梯度消失的情况。
注:(1)当x=0时,,此时梯度是未定义的,如果真出现这种情况梯度是1或者0都可以,对网络影响不大。(2)死Relu:从不会被激活。如果可以激活神经元的数据不在数据集内,那这个神经元将永远不会被激活,就成了死神经元。出现死ReLU的情况有两种,第一种就是初始化时权重被设置成了无法激活神经元的值。第二种就是学习率过大,神经元的输出限制在一个范围内波动,可能发生数据多样性缺失。通常会选择初始化神经元的权值为较小数,使网络更有可能输出正值,更可能被激活。
Leaky ReLU
函数图像:
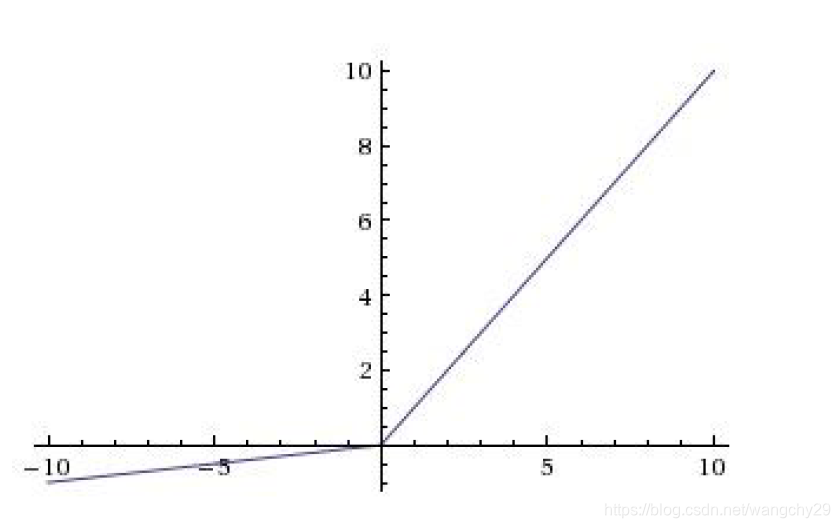
特点:(1)不会出现饱和梯度消失的现象。(2)计算效率高。(3)收敛速度比sigmoid、tanh快。(4)不会出现死神经元的情况。
PReLU
,其中参数
是从网络中学习出来的,每二个神经元都有一个自己的
。
Maxout
特点:(1)是分段线性函数。(2)不会出现饱和梯度消失现象。(3)不会出现死神经元。(4)是ReLU和Leaky ReLU的一般化。
问题:参数数目翻倍。
ELU
指数线性函数
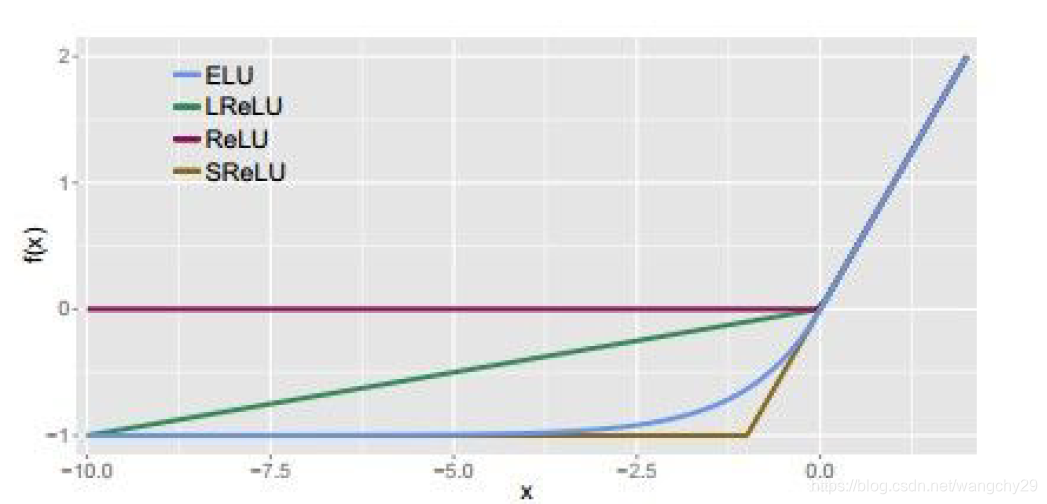
特点:1)在输入数据为正时不会发现神经元饱和梯度消失的情况。(2)计算效率高。(3)收敛速度比tanh和sigmoid快。(4)不会出现死神经元。(5)接近于0均值输入。
问题:计算比较耗时。
数据预处理
常用的两种:(1)减去图像均值(2)减去通道均值:在红绿蓝三个通道中单独计算均值,三个通道分别减去其对应的均值。