神经网络 第3部分:学习和评估
这一部分主要讨论建立网络之后如何进行学习,内容包括:
1. 梯度检查
2. 合理性检查
3. 监控学习过程
4. 参数更新
5. 超参数优化
6. 模型集成
1.4 参数更新
一旦计算出解析梯度,它将被用来更新参数,接下来介绍一些更新参数的方法(参数都用x表示):
1.4.1 SGD
Vanilla更新 最简单的参数更新方式,以梯度的负方向更新参数
# Vanilla更新
x += - learning_rate * dx
动量(Momentum)更新
另一种在深度网络中获得更快收敛速度的更新方法,它从物理视角看待优化问题。我们把损失值看作是山地上某个位置的高度,将参数初始化为随机值相当于在山地上某个位置设置了一个速度为0的小球,而优化过程可以看作让小球从上述位置滚下来。
在普通SGD中,位置变化量直接由梯度决定,而在动量版本中,梯度影响速度,而速度决定位置变化量。
# 动量更新
v = mu*v - learning_rate*dx # 速度
x += v # 更新量等于速度
速度v初始值为0,摩擦系数mu为超参数(一般取值为0.9左右,可以尝试[0.5, 0.9, 0.95, 0.99])。上面的式子很好理解,mu*v表示速度越快摩擦阻力越大,而梯度(坡度)dx越大速度越快。
涅斯特罗夫动量(Nesterov Momentum)
现在流行的对动量更新的改进版本,取得了比标准动量更新稍微好一些的表现。
v_prev = v
v = mu*v - learning_rate*dx # 速度
x += v + mu*(v - v_prev)
建议看看有关涅斯特罗夫加速动量(NAG,Nesterov’s Accelerated Momentum)的扩展阅读:
- Advances in optimizing Recurrent Networks, 章节3.5。
- Ilya Sutskever’s thesis,章节7.2。
1.4.2 学习率退火
在深度学习训练中,一般随着时间的推移减小学习率,下面是三种常见的减小学习率的方法:

- 逐步递减:每经过一定的epoch数就用某个因子(比如0.9)减小学习率,5个epoch后学习率降低到大约原来的 ,20个epoch后降为原来的 。
- 指数递减: , 为超参数,t为epoch数。
- 1/t递减: , 为超参数,t为epoch数。
在实践中逐步递减更可行,如果你的计算资源足够,可以让递减缓慢些。
1.4.3 二阶法
第二种在深度学习中常用的优化方法是牛顿法,它的更新表达式为:
是海森矩阵,它是函数的二阶偏导数的平方矩阵,描述了函数的局部曲率。和海森矩阵的逆矩阵相乘表示在曲率小的地方大步前进,在曲率大的地方小步前进。关键是这个公式里没有超参数,这是相对一阶方法的巨大进步。
尽管如此,但是牛顿法对绝大多数深度学习应用来说都不切实际,因为计算海森矩阵和它的逆矩阵开销非常大。
实际上,在大规模网络中一阶方法应用更常见,因为它们简单。
1.4.4 逐参数适应学习率法
所有之前讨论的方法对每个参数的学习率都是一样的。调整学习率是一个开销很大的过程,所以在设计自适应调整学习率甚至对每个参数进行自适应调整的方法上作了很多的工作。下面介绍一些实践中可能遇到的自适应方法:
Adagrad
cache += dx**2
x += - learning_rate * dx / (np.sqrt(cache) + eps)
eps取1e-4到1e-8,防止除0。
RMSprop
cache = decay_rate * cache + (1 - decay_rate) * dx**2
x += - learning_rate * dx / (np.sqrt(cache) + eps)
decay_rate是一个超参数,常用值为[0.9, 0.99, 0.999]。
Adam
m = beta1*m + (1-beta1)*dx
mt = m / (1-beta1**t)
v = beta2*v + (1-beta2)*(dx**2)
vt = v / (1-beta2**t)
x += - learning_rate * mt / (np.sqrt(vt) + eps)
论文推荐的eps = 1e-8, beta1 = 0.9, beta2 = 0.999。

上面的动画直观的反应了几种优化方式的区别。
1.5 超参数优化
训练神经网络的过程中涉及很多超参数,主要的有三个:
- 初始的学习率
- 学习率的递减率
- 正则化强度
如前面介绍,除了这三个主要的超参数,其实还有更多不太敏感的超参数。下面额外介绍一些优化超参数的提示和技巧:
实现方式
大型的神经网络需要很长时间去训练,尝试超参数需要很多天甚至几星期。一种特别的设计是用一些“工人程序”去持续的对超参数进行采样和验证,“工人程序”会将验证的各个阶段性结果(checkpoints)写入文件。在系统中还有一个“调度程序”,它负责管理所有的“工人程序”,并且对“工人程序”写入的结果进行检查并进行统计。
使用一个验证集代替交叉验证
在大多数情况下,一个大小可观的验证集可以简化代码,而不需要用交叉验证把代码分成几部分。
超参数范围
在指数尺度上进行超参数搜索,对学习率的一个典型的采样可能像这样:learning_rate = 10 ** uniform(-6, 1),即从均匀分布中随机生成一个数字,然后让它成为10的幂。对于正则化强度也应该采取同样的策略,这是因为它们对训练力度有乘法效应。而对于随机失活概率就应该采用原始的尺度:dropout = uniform(0,1))。
使用随机搜索代替网格搜索
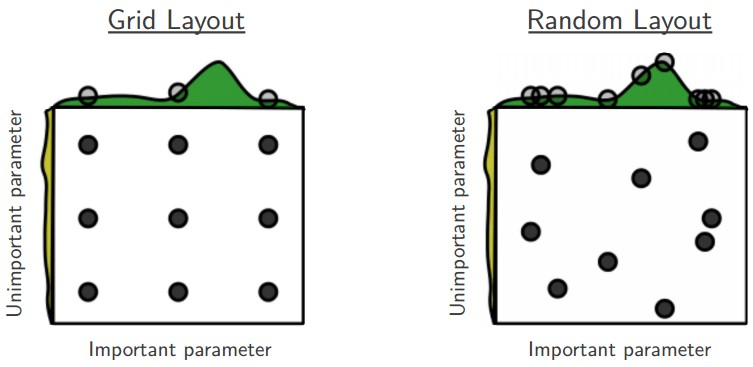
对超参数优化,随机选择比网格化的选择更加有效率,而且在实践中也更容易实现。
注意边界上的最优值
如果找到的最优值,应该再检查一下是不是在边界上,以免错过好的搜索范围。
从粗到细搜索
从大的范围开始搜索,先用较少的数据找到更小的范围,然后用较多的数据在更小的范围上搜索,如此迭代。
贝叶斯超参数优化
这是一个研究领域,致力于找到更加有效的探索超参数空间的算法。更多的信息可以看这里。
2.模型集成
在实践中,一个可靠的提高神经网络性能几个百分点的的方法是训练多个单独的模型,然后在测试时平均它们的预测结果。当集成的模型数增加时,性能通常也单调提升。此外,这种提升和集成的模型多样相关。下面是一些模型集成的方式:
- 一样的模型,不同的初始化 用交叉验证确定最优的超参数,然后用最优的超参数和随机的的初始化参数训练多个模型。
- 用交叉验证发现最好的模型 用交叉验证确定最优的超参数,然后选择其中最好的几个模型来集成。
- 一个模型的不同记录点 如果训练开销特别大,那就用一个模型的多个不同记录点进行集成,有些人也用这种方式取得了有限的成功。很明显,这种方法缺乏多样性。
- 在训练时跑参数的平均值 和上一个方法类似,一个能增加一两个百分比的廉价的方法是在内存中保持一份权值拷贝,这个拷贝是之前训练中权值的指数衰减和(an exponentially decaying sum,更多信息请看原文)
模型集成的一个缺点是用很长时间取评估测试样本。感兴趣的读者可能发现最近Geoff Hinton在“Dark Knowledge”上的工作令人鼓舞,它通过将集成的对数似然估计纳入到修改的目标函数中,从一个好的集成回溯到一个单独模型。
总结
- 用一个小的batch来对你的解析梯度进行梯度检查并注意各种问题。
- 对于合理性检查,确认你的初始损失值,还有你能在一小块数据上获得0损失。
- 在训练中,监控损失值,训练/验证准确率还有权值变化率(应该在1e-3左右),CNN的话还有第一层权值。
- 两个建议的参数更新方法是SGD+Nesterov动量和Adam。
- 逐步的降低学习率。
- 随机搜索超参数,逐步细化超参数。
- 进行模型集成获得额外的性能。
附加参考文献
- SGD tips and tricks
- Efficient BackProp
- Practical Recommendations for Gradient-Based Training of Deep Architectures
© 2018 by 0ne.tech