最小的神经网络案例学习
这一部分主要讨论建立网络之后如何进行学习,内容包括:
- 生成数据
- 训练Softmax线性分类器
- 训练神经网络
1.生成数据
首先生成一个不是简单线性可分的分类数据集。我们希望是螺旋形的数据集,像这样生成:
N = 100 # 每种类型的数据数
D = 2 # 纬度,这里是二维坐标点
K = 3 # 类型数
X = np.zeros((N*K,D)) # 数据,每一行为一个样本
y = np.zeros(N*K, dtype='uint8') # 数据的类型标签
for j in xrange(K):
ix = range(N*j,N*(j+1))
r = np.linspace(0.0,1,N) # 极坐标半径
t = np.linspace(j*4,(j+1)*4,N) + np.random.randn(N)*0.2 # 极坐标角度
X[ix] = np.c_[r*np.sin(t), r*np.cos(t)]
y[ix] = j
# 数据可视化:
plt.scatter(X[:, 0], X[:, 1], c=y, s=40, cmap=plt.cm.Spectral)
plt.show()
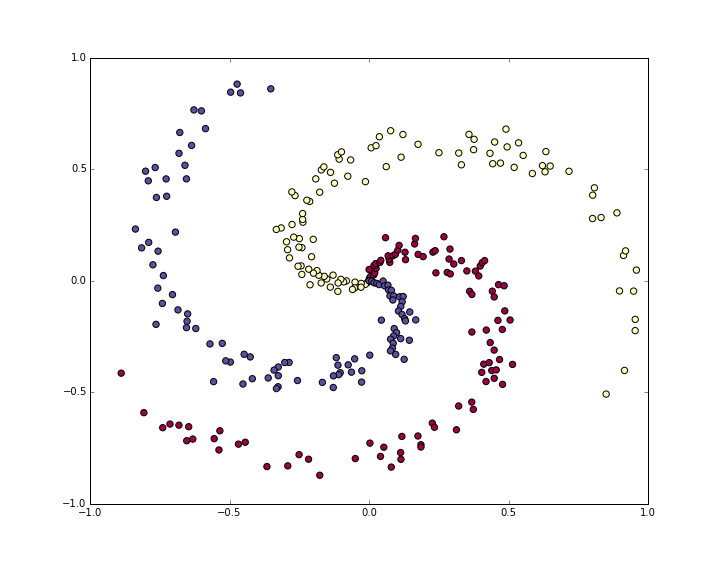
由上图可知,三类数据(红黄蓝)螺旋状的数据构成不能被轻易的线性划分。
通常我们需要将数据预处理成0均值单位标准差的分布,但是这里数据已经很好的分布在-1到1区间了,所以我们省去预处理。
2.训练Softmax线性分类器
1.1 初始化参数
像我们之前课程中看到的,Softmax拥有线性的评分函数(score function)然后使用交叉熵(cross-entropy)计算损失。我们首先用随机数初始化参数:
W = 0.01 * np.random.randn(D,K) #权值
b = np.zeros((1,K)) #偏差
回想一下D = 2是数据维度,K=3是分类的类型数。
1.2 计算类型得分
因为这是一个线性分类器,我们通过一个非常简单的并行的矩阵乘法来计算类型得分:
scores = np.dot(X, W) + b #得分(N,K)
在这个例子里我们有300个2维点坐标,到目前为止得分scores是一个[300x3]的矩阵,每一行都有3个得分(红黄蓝)。
1.3 计算损失值
这里的关键部分是损失函数,它是一个用来量化得分的可微函数,反映预测值(类型得分)和真实值(类型标签)间的差距。无疑我们需要正确类型的得分高于其它的类型的得分,而损失函数的值越低越好。回忆一下Softmax的损失函数如下:
它其实是真实标签分布和预测得分分布的交叉熵,因为真实标签分布为[0,…,1,…,0]的形式,所以简化为只有一项。再回忆一下完整的带正则化项的损失函数:
下面我们来计算损失Loss:
num_examples = X.shape[0]
exp_scores = np.exp(scores)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
correct_logprobs = -np.log(probs[range(num_examples),y])
data_loss = np.sum(correct_logprobs)/num_examples
reg_loss = 0.5*reg*np.sum(W*W)
loss = data_loss + reg_loss
1.4 计算反向传播(Backpropagation)的解析梯度
通过求导可得:
然后通过链式求导法则,计算出dW,db:
dscores = probs
dscores[range(num_examples),y] -= 1
dscores /= num_examples
dW = np.dot(X.T, dscores)
db = np.sum(dscores, axis=0, keepdims=True)
dW += reg*W # 别忘记正则化项
1.5 进行参数更新
W += -step_size * dW
b += -step_size * db
1.6 汇总:训练一个Softmax分类器
# 随机初始化参数
W = 0.01 * np.random.randn(D,K)
b = np.zeros((1,K))
# 一些超参数
step_size = 1e-0
reg = 1e-3 # regularization strength
# 梯度下降循环
num_examples = X.shape[0]
for i in xrange(200):
# 计算得分scores, [N x K]
scores = np.dot(X, W) + b
# 计算Softmax
exp_scores = np.exp(scores)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True) # [N x K]
# 计算损失: 交叉熵损失 和 正则化
correct_logprobs = -np.log(probs[range(num_examples),y])
data_loss = np.sum(correct_logprobs)/num_examples
reg_loss = 0.5*reg*np.sum(W*W)
loss = data_loss + reg_loss
if i % 10 == 0:
print "iteration %d: loss %f" % (i, loss)
# 计算scores的梯度
dscores = probs
dscores[range(num_examples),y] -= 1
dscores /= num_examples
# 计算出参数 (W,b) 的梯度
dW = np.dot(X.T, dscores)
db = np.sum(dscores, axis=0, keepdims=True)
dW += reg*W # regularization gradient
# 进行参数更新
W += -step_size * dW
b += -step_size * db
程序运行输出:
iteration 0: loss 1.096956
iteration 10: loss 0.917265
iteration 20: loss 0.851503
iteration 30: loss 0.822336
iteration 40: loss 0.807586
iteration 50: loss 0.799448
iteration 60: loss 0.794681
iteration 70: loss 0.791764
iteration 80: loss 0.789920
iteration 90: loss 0.788726
iteration 100: loss 0.787938
iteration 110: loss 0.787409
iteration 120: loss 0.787049
iteration 130: loss 0.786803
iteration 140: loss 0.786633
iteration 150: loss 0.786514
iteration 160: loss 0.786431
iteration 170: loss 0.786373
iteration 180: loss 0.786331
iteration 190: loss 0.786302
计算训练集准确率:
scores = np.dot(X, W) + b
predicted_class = np.argmax(scores, axis=1)
print 'training accuracy: %.2f' % (np.mean(predicted_class == y))
准确率大概是 49%,不是十分好,因为数据集的分布不是线性可分的。我们将学习出的选择边界画出来:
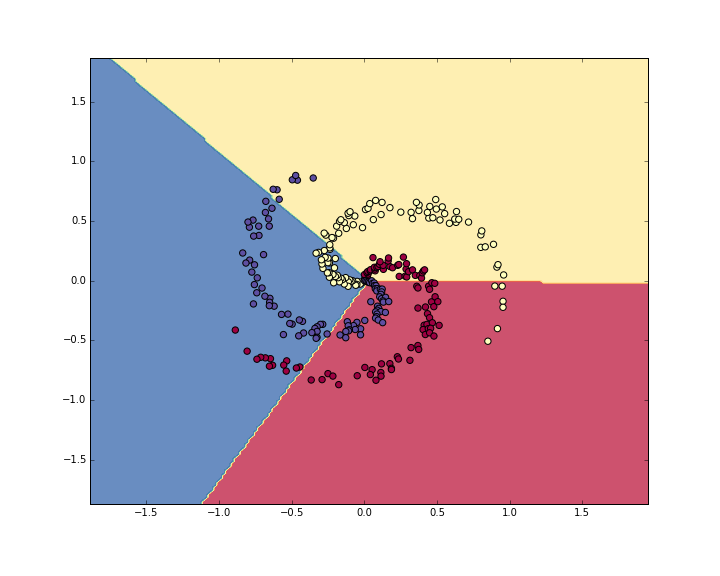
2.训练神经网络
很明显,线性分类器不适用于这种线性不可分的数据集,所以我们希望使用神经网络。一个两层的网络足够应付这个简单的例子。
2.1 初始化参数
h = 100 # 隐层规模
W = 0.01 * np.random.randn(D,h)
b = np.zeros((1,h))
W2 = 0.01 * np.random.randn(h,K)
b2 = np.zeros((1,K))
2.2 计算类型得分
hidden_layer = np.maximum(0, np.dot(X, W) + b) # 使用ReLU激活
scores = np.dot(hidden_layer, W2) + b2
2.3 计算损失
和之前的线性分类器一样。
2.4 反向传播计算梯度
dscores的计算同线性分类器。
dW2 = np.dot(hidden_layer.T, dscores)
db2 = np.sum(dscores, axis=0, keepdims=True)
dhidden = np.dot(dscores, W2.T)
dhidden[hidden_layer <= 0] = 0 # BP for ReLU
dW = np.dot(X.T, dhidden)
db = np.sum(dhidden, axis=0, keepdims=True)
2.5 进行参数更新
W += -step_size * dW
b += -step_size * db
W2 += -step_size * dW2
b2 += -step_size * db2
2.6 汇总:训练一个神经网络
# 随机初始化参数
h = 100 # size of hidden layer
W = 0.01 * np.random.randn(D,h)
b = np.zeros((1,h))
W2 = 0.01 * np.random.randn(h,K)
b2 = np.zeros((1,K))
# 一些超参数
step_size = 1e-0
reg = 1e-3 # 正则化强度
# 梯度下降循环
num_examples = X.shape[0]
for i in xrange(10000):
# 计算类型得分scores, [N x K]
hidden_layer = np.maximum(0, np.dot(X, W) + b) # note, ReLU activation
scores = np.dot(hidden_layer, W2) + b2
# 计算Softmax
exp_scores = np.exp(scores)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True) # [N x K]
# 计算损失: 交叉熵损失 和 正则化
correct_logprobs = -np.log(probs[range(num_examples),y])
data_loss = np.sum(correct_logprobs)/num_examples
reg_loss = 0.5*reg*np.sum(W*W) + 0.5*reg*np.sum(W2*W2) #所有层的正则化项的和
loss = data_loss + reg_loss
if i % 1000 == 0:
print "iteration %d: loss %f" % (i, loss)
# 计算scores的梯度
dscores = probs
dscores[range(num_examples),y] -= 1
dscores /= num_examples
# 反向传播计算参数梯度
# W2和b2的梯度
dW2 = np.dot(hidden_layer.T, dscores)
db2 = np.sum(dscores, axis=0, keepdims=True)
# 反向传播到隐层
dhidden = np.dot(dscores, W2.T)
# 计算ReLU的梯度
dhidden[hidden_layer <= 0] = 0
# 最后是W和b
dW = np.dot(X.T, dhidden)
db = np.sum(dhidden, axis=0, keepdims=True)
# 加上正则化项的梯度贡献
dW2 += reg * W2
dW += reg * W
# 进行参数更新
W += -step_size * dW
b += -step_size * db
W2 += -step_size * dW2
b2 += -step_size * db2
计算训练集的准确率:
hidden_layer = np.maximum(0, np.dot(X, W) + b)
scores = np.dot(hidden_layer, W2) + b2
predicted_class = np.argmax(scores, axis=1)
print 'training accuracy: %.2f' % (np.mean(predicted_class == y))
准确率是 98%!学习出的选择边界如图所示:
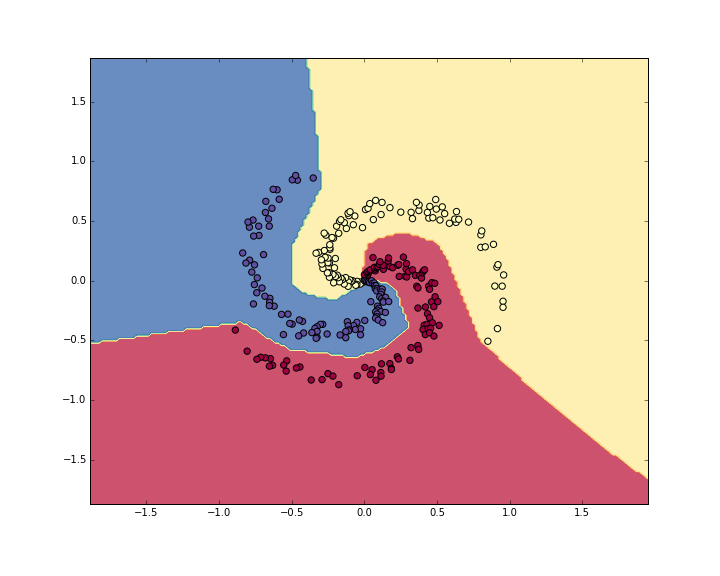
总结
我们看到了线性分类器和两层的神经网络在代码上区别不大,但是带来了巨大的提升。
© 2018 by 0ne.tech