神经网络 第3部分:学习和评估
这一部分主要讨论建立网络之后如何进行学习,内容包括:
1. 梯度检查
2. 合理性检查
3. 监控学习过程
4. 参数更新
5. 超参数优化
6. 模型集成
1.学习
前面的部分讨论了神经网络中的静态内容:如何构建网络、数据和损失函数。这个部分将介绍网络中的动态部分:如何对参数进行学习并找到最优的超参数。
1.1 梯度检查
理论上,进行梯度检查就是简单比较解析梯度和数值梯度,但是实践中这个过程更加复杂和易出错。下面是一些关于梯度检查的提示、技巧和需要注意的问题:
使用中心差分公式
上面是三种数值梯度计算方式,其中 的值非常小,实际一般大概为1e-5左右,所以中心差分拥有较小的误差。
使用相对误差进行比较
为解析梯度, 为数值梯度,一般可参考的判断标准为:
- ,算错了。
- ,你有些不适,这很尴尬,应该是错了。
- ,如果目标函数有不可导点则可以接受,没有误差就偏大了。
- ,算对了。
记住,当网络层数越深,相对误差会越大。一个10层的网络,BP到前面几层 的误差也许是可以接受的。
精度问题
Python3默认使用双精度,保证17位十进制精度。
- 如果不知道哪里算错了,可以检查下是否使用了单精度变量。
- 当梯度值过小时,比如大概1e-10,相对误差计算也可能过大。(计算机结构问题)
- 值不要过小,一般在1e-4到1e-6之间。
目标函数的不可导点

目标函数存在不可导点,此处无法计算解析梯度,但是数值梯度有值。比如在ReLU的0点,解析梯度为0,数值梯度则有值。这种情况很常见,ReLU和SVM中都存在不可导点。检查少一些的数据点有利于避开不可导点,一般几个数据点正确整批数据都没问题,这样使梯度检查更有效率。
不要让正则化项压过数据
有一种情况需要注意,正则化项的损失盖过了数据的损失。解决方式是每次检查时,先检查一次不带正则化项的梯度,再加上正则化项检查一次。
记得关掉随机失活
在进行梯度检查时,记得关掉随机失活等不确定的影响,因为这些操作很明显会使数值梯度产生巨大误差。关掉这些操作将无法对它们进行梯度检查(例如随机失活没有正确的反向传播)。一个更好的办法是在计算f(x+h)和f(x-h)和计算解析梯度前强制使用一个特定的随机种子。
只检查少量的维度
在实践中可能有几百万个参数,在这种情况下实际只能检查其中的一些维度而假设其它的都是正确的。需要注意的是,要保证检查这些维度中的所有不同参数。比如没有检查偏差 的梯度,此时错误梯度可能将被忽略。
1.2 在学习之前:合理性检查的提示和技巧
从概率表现寻找正确的损失值
弄清楚用随机初始化后期望的初始损失值是多少并检验(此时关掉正则化项)。比如使用Softmax分类器分类CIFAR-10图片,期望的初始损失值是-ln(0.1) = 2.302。(因为随机参数分类图片的正确率是0.1)
第二个合理性检查是损失值随着正则化项增大而增大
过拟合一个小数据集
最后也是最重要的,在你训练整个数据集之前,使用一个小的数据集(例如20个样本)进行训练,确保能够达到0损失。(关掉正则化项,它会阻碍你获得0损失)
1.3 监控学习过程
在神经网络训练阶段有很多有用的数值需要监控,这些数值的图表能让你直观的感受不同超参数的影响并有效率的调整这些超参数。这些图表的x轴一般都是epoch数(将所有样本过一遍是一个epoch)。
损失函数
在训练中损失值是第一重要的数值,并且在每个batch都记录它。下面的图表表现了不同的学习率下损失值的变化情况:

单独的损失值随时间变化的图表如下:
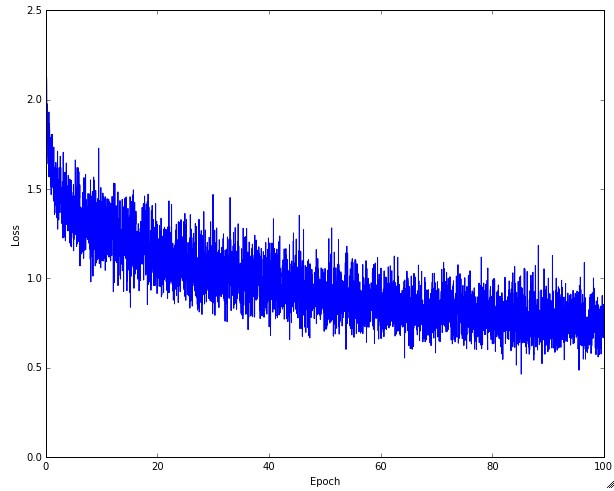
在上图中,上下波动的幅度和batch的大小有关(每次梯度更新都会改进损失函数),batch的大小越大波动幅度越小。
训练/验证 准确率
在训练一个分类器时第二重要的数值是训练/验证的准确率。这个图表揭示了你的模型的过拟合程度。
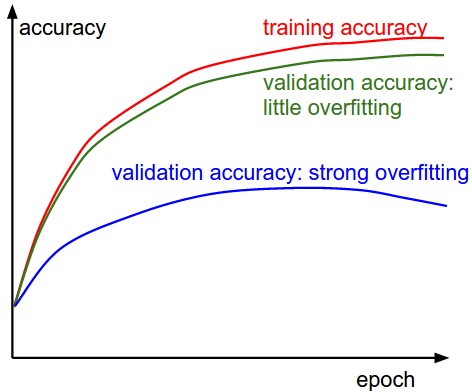
在上图中,训练准确率和验证准确率之间的差距反应了模型的过拟合程度,差距越大过拟合程度越大。在过拟合时,可以增大正则化项、加大随机失活概率或用更多数据验证。还有一种情况是模型本身的容量不够,这时需要增加参数使用更大的模型。
权值变化率
最后一个你可能需要跟踪的数值是权值变化率,它的计算如下列代码,一个合适的变化率大概在1e-3附近。
# W是权值,dW是权值的梯度
param_scale = np.linalg.norm(W.ravel())
update = -learning_rate*dW # SGD
update_scale = np.linalg.norm(update.ravel())
W += update # 权值更新量
print update_scale / param_scale # 应该在 1e-3 附近
每层的激活/梯度分布
一个错误的初始化可以使学习过程变慢或完全停止。幸运的是,这个问题可以使用所有层的激活/梯度直方图观察到。例如一个tanh神经元应该有[-1,1]的分布,而不是全0或全部集中在-1或1附近。
可视化第一层权值
在处理图片像素时,将第一层权值可视化可能会有帮助(在SVM和Softmax作业的最后展示过)。
© 2018 by 0ne.tech