cs231n (一)神经网络介绍
标签(空格分隔): 神经网络
本课程首先介绍了关于计算机视觉的相关知识和背景
0.介绍图像分类
动机: 图像分类是计算机视觉的核心问题之一。
例子: 图像分类模型是获取单个图像并分配给自己定好的标签,像素值jpg格式的是0-255,如下图。
一眼就看出他是猫,现在计算机的作用就是看了这么像素,然后返回一个标签:‘猫’!
难点: 视角、大小、形变、部分、模糊、背景干扰、类别数量大
那么好的模型必须:做到很好的泛化能力。
数据驱动方法: 我们如何做到分类呢?那么就需要有先验知识,就是自己做的标签,先告诉计算机说这是猫,然后它见了其他的,就会以一定比例告诉你这是猫。
那么我们做一个四分类分类器,可能为每一个类别提供数十万的图像数据。
图像分类管道: 那么分类线就是
- 输入:输入一组图像,每个图像有自己的类别,这就是训练集
- 学习:接下来就是让计算机学习了,这个模型就叫做学习模型
- 评估:那么我给它新图像,看电脑给出的结果和人类能否一致
1.最近邻分类器
第一个方法用到的是:KNN,和你所听说的CNN没有关系,虽然很少用到,我还是写一下吧,毕竟ZB可以用啊。
示例图像数据集:就是标签啦,一个就是CIFAR-10
dataset,包含60000个32x32的图像十个类别图像库,看下面啊。
其中有50000训练数据,10000测试数据(就是先测试一下分类器厉害不)

怎么确认是不是一类呢?看俩图像相似度
一般用
距离来衡量,比如 图像
和 图像
的
距离就是:
看看可视化过程,如果d很小,那就是图像很像,如果d很大,你懂的
看看如何代码实现?首先把CIFAR-10存成数组,然后都把图像拉成行
Xtr, Ytr, Xte, Yte = load_CIFAR10('data/cifar10/') # a magic function we provide
# flatten out all images to be one-dimensional
Xtr_rows = Xtr.reshape(Xtr.shape[0], 32 * 32 * 3) # Xtr_rows becomes 50000 x 3072
Xte_rows = Xte.reshape(Xte.shape[0], 32 * 32 * 3) # Xte_rows becomes 10000 x 3072
现在把数据拉成行,然后接下来评估
nn = NearestNeighbor() # create a Nearest Neighbor classifier class
nn.train(Xtr_rows, Ytr) # train the classifier on the training images and labels
Yte_predict = nn.predict(Xte_rows) # predict labels on the test images
# and now print the classification accuracy, which is the average number
# of examples that are correctly predicted (i.e. label matches)
print('accuracy: %f' % ( np.mean(Yte_predict == Yte) ))
评估标准,通常使用精确度来度量预测的正确部分,构建的所有分类器都满足以下一个通用API:
它们具有:
train(X,y)将数据和标签从中学习的功能。
在内部,应该建立某种模式的标签,以及如何从数据中预测标签。然后是一个
predict(X)函数,它接收新的数据并预测标签。
下面是一个简单的最近邻分类器的实现,L1距离满足这个模板
import numpy as np
class NearestNeighbor(object):
def __init__(self):
pass
def train(self, X, y):
""" X is N x D where each row is an example. Y is 1-dimension of size N """
# the nearest neighbor classifier simply remembers all the training data
self.Xtr = X
self.ytr = y
def predict(self, X):
""" X is N x D where each row is an example we wish to predict label for """
num_test = X.shape[0]
# lets make sure that the output type matches the input type
Ypred = np.zeros(num_test, dtype = self.ytr.dtype)
# loop over all test rows
for i in xrange(num_test):
# find the nearest training image to the i'th test image
# using the L1 distance (sum of absolute value differences)
distances = np.sum(np.abs(self.Xtr - X[i,:]), axis = 1)
min_index = np.argmin(distances) # get the index with smallest distance
Ypred[i] = self.ytr[min_index] # predict the label of the nearest example
return Ypred
这个代码可以实现38.6%,或接近最先进的卷积神经网络, 95%,符合人类的准确性(94%)(参见CIFAR-10最近的Kaggle比赛的排行榜)。
我们还可以选择
距离
关于这两个距离的解释可以看我之前的博客
那么可以用python这么实现:
distances = np.sqrt(np.sum(np.square(self.Xtr - X[i,:]), axis = 1))
距离 等价于一对图像之间差异的 L1/L2范数,是p范数常见的特例。
2.K-近邻分类器(其他分类器)
思路就是——对于待判断的点,找到离它最近的几个数据点,根据它们的类型决定待判断点的类型,它的特点是完全跟着数据走,没有数学模型可言
想用k-Nearest Neighbor,K应该等于多少呢?接下来我们转向这个问题。
3.超参数调整的验证集
KNN 需要对K进行设置,还有距离的选择有L1,L2范数,还有其他的选择,这些就是超参数,这会出现在机器学习算法设计中出现。
我们不能使用测试集来调整超参数。无论何时设计机器学习算法,您都应该将测试集作为一个非常宝贵的资源,只有模型设置好之后再用它,他是验证你模型的标准。
以CIFAR-10为例,我们可以使用49,000个训练图像进行训练,并留出1,000个用于验证。该验证集本质上用作假测试集来调整超参数。
以下是CIFAR-10的情况:
# assume we have Xtr_rows, Ytr, Xte_rows, Yte as before
# recall Xtr_rows is 50,000 x 3072 matrix
Xval_rows = Xtr_rows[:1000, :] # take first 1000 for validation
Yval = Ytr[:1000]
Xtr_rows = Xtr_rows[1000:, :] # keep last 49,000 for train
Ytr = Ytr[1000:]
# find hyperparameters that work best on the validation set
validation_accuracies = []
for k in [1, 3, 5, 10, 20, 50, 100]:
# use a particular value of k and evaluation on validation data
nn = NearestNeighbor()
nn.train(Xtr_rows, Ytr)
# here we assume a modified NearestNeighbor class that can take a k as input
Yval_predict = nn.predict(Xval_rows, k = k)
acc = np.mean(Yval_predict == Yval)
print 'accuracy: %f' % (acc,)
# keep track of what works on the validation set
validation_accuracies.append((k, acc))
我们可以绘制一个图表,显示哪个k值最好。然后,我们将坚持这个值,并在实际测试集上评估一次。
一般有三种验证方式:
- 简单交叉验证 : 随机分开数据成两部分
- S折交叉验证 : 随机分成S等分,然后用S-1份训练,1 测试
- 留一交叉验证 : 就是2中 S=N 的时候。
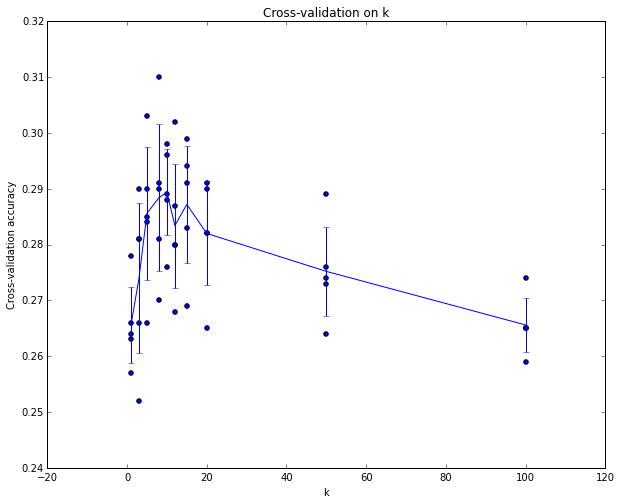
实际中,我们交叉验证应该避免,因为代价昂贵,一般使用 50% - 90%。

4.最近邻分类器优缺点
优点:简单啊; 缺点:泛化能力弱。
高维度数据,距离和感官上是不同的,右边3张图片和左边第1张原始图片的L2距离是一样的,基于像素比较的相似和感官上以及语义上的相似是不同的。

有个视觉化证据,可以证明像素差异是不够的,将CIFAR-10中的图片按照二维方式排布,这样能很好展示图片之间的像素差异值。在这张图片中,排列相邻的图片L2距离就小。
5.总结
使用KNN分类

转载和疑问声明
如果你有什么疑问或者想要转载,没有允许是不能转载的哈
赞赏一下能不能转?哈哈,联系我啊,我告诉你呢 ~~
欢迎联系我哈,我会给大家慢慢解答啦~~~怎么联系我? 笨啊~ ~~ 你留言也行
你关注微信公众号1.听朕给你说:2.tzgns666,3.或者扫那个二维码,后台联系我也行啦!
