一、引言
提升(boosting)方法是一种常用的统计学习方法,应用广泛且有效,在分类问题中,它通过改变训练样本的权重,学习多个分类器,并将这些分类器进行线性组合,提高分类的性能。
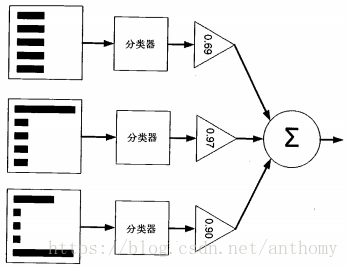
对于分类问题,给定一个训练样本集,比较粗糙的分类规则(弱分类器),要比精确分类规则(强分类器)容易,提升方法就是从弱学习算法出发,反复学习,得到一系列弱分类器,然后组合这些弱分类器,构成一个强分类器,大多数提升方法都是改变训练数据的概率分布(训练数据的权值分布),AdaBoost的做法是,提高那些被前一轮分类器错误分类的样本的权值,而降低那些被正确分类样本的权值,这样那些没有得到正确分类的数据,由于权值加大而受到后一轮弱分类器更大的关注。AdaBoost关于如何将弱分类器组合成一个强分类器,采用加权多数表决的方法,具体地,加大分类误差率小的弱分类器的权值,使其在表决中起较大的作用,减小分类误差率大的弱分类器的权值,使其在表决中起较小的作用。
二、AdaBoost算法原理
假设给定一个二分类的训练数据集:
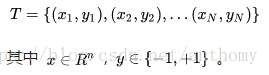
X是实例空间,y是标签集合。
<1>初始化训练数据的权值分布
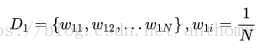
假设训练数据具有均匀的权值分布,即每个训练样本在基本分类器的学习中作用相同,这一假设保证第一步能够保证这一步能够在原始数据上学习基本分类器Gi(x)
<2>对m=1,2,...,M
AdaBoost反复学习基本分类器,在每一轮m=1,2,...,M顺次地执行下列操作:
a>使用具有权值分布Dm的训练数据集学习,得到基本(弱)分类器
Gm(x):X->{-1,1}
b>计算Gm(x)在训练数据集上的分类误差率
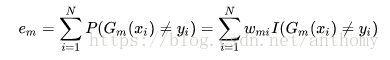
Wmi表示第m轮中第i个实例的权值,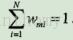
由此可以得到数据权值分布Dm与基本分类器Gm(x)的分类误差率的关系
c>计算Gm(x)的系数
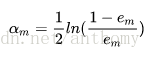
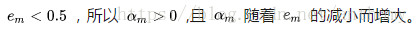
所以分类误差越小的基本分类器在最终的分类器的作用越大。
d>更新训练数据集的权值分布
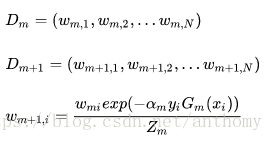
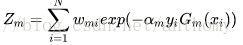
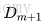
结果使得被基本分类器Gm(x)误分类样本的权值得以扩大,而被正确分类样本的权值得以缩小,两相比较,误分类样本的权值被放大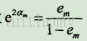
<3>构建基本分类器的线性组合
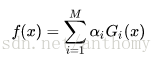
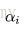
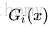
得到最终的分类器
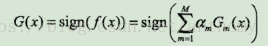
线性组合f(x)实现M个基本分类器的加权表决,系数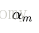
三、程序调试
1.基于单层决策树构建弱分类器的代码
def stumpClassify(dataMatrix,dimen,threshVal,threshIneq):#just classify the data
retArray = ones((shape(dataMatrix)[0],1))
if threshIneq == 'lt':
retArray[dataMatrix[:,dimen] <= threshVal] = -1.0
else:
retArray[dataMatrix[:,dimen] > threshVal] = -1.0
return retArray
def buildStump(dataArr,classLabels,D):
dataMatrix = mat(dataArr); labelMat = mat(classLabels).T
m,n = shape(dataMatrix)
numSteps = 10.0; bestStump = {}; bestClasEst = mat(zeros((m,1)))
minError = inf #init error sum, to +infinity
for i in range(n):#loop over all dimensions
rangeMin = dataMatrix[:,i].min(); rangeMax = dataMatrix[:,i].max();
stepSize = (rangeMax-rangeMin)/numSteps
for j in range(-1,int(numSteps)+1):#loop over all range in current dimension
for inequal in ['lt', 'gt']: #go over less than and greater than
threshVal = (rangeMin + float(j) * stepSize)
predictedVals = stumpClassify(dataMatrix,i,threshVal,inequal)#call stump classify with i, j, lessThan
errArr = mat(ones((m,1)))
errArr[predictedVals == labelMat] = 0
weightedError = D.T*errArr #calc total error multiplied by D
#print "split: dim %d, thresh %.2f, thresh ineqal: %s, the weighted error is %.3f" % (i, threshVal, inequal, weightedError)
if weightedError < minError:
minError = weightedError
bestClasEst = predictedVals.copy()
bestStump['dim'] = i
bestStump['thresh'] = threshVal
bestStump['ineq'] = inequal
return bestStump,minError,bestClasEst
2.完整Adaboost算法的实现
过程:每次迭代中
利用buildStump函数找到最佳的单层决策树
将最佳单层决策树加入到单层决策树组
计算alpha,新的权重向量D
更新累计类别估计值
如果错误率等0,则退出循环
2.1基于单层决策树的adaboost训练算法
def adaBoostTrainDS(dataArr,classLabels,numIt=40):
weakClassArr = []
m = shape(dataArr)[0]
D = mat(ones((m,1))/m) #init D to all equal
aggClassEst = mat(zeros((m,1)))
for i in range(numIt):
bestStump,error,classEst = buildStump(dataArr,classLabels,D)#build Stump
#print "D:",D.T
alpha = float(0.5*log((1.0-error)/max(error,1e-16)))#calc alpha, throw in max(error,eps) to account for error=0
bestStump['alpha'] = alpha
weakClassArr.append(bestStump) #store Stump Params in Array
#print "classEst: ",classEst.T
expon = multiply(-1*alpha*mat(classLabels).T,classEst) #exponent for D calc, getting messy
D = multiply(D,exp(expon)) #Calc New D for next iteration
D = D/D.sum()
#calc training error of all classifiers, if this is 0 quit for loop early (use break)
aggClassEst += alpha*classEst
#print "aggClassEst: ",aggClassEst.T
aggErrors = multiply(sign(aggClassEst) != mat(classLabels).T,ones((m,1)))
errorRate = aggErrors.sum()/m
print ('total error: ',errorRate)
if errorRate == 0.0: break
return weakClassArr,aggClassEst
2.2AdaBoost分类函数算法
def adaClassify(datToClass,classifierArr):
dataMatrix = mat(datToClass)#do stuff similar to last aggClassEst in adaBoostTrainDS
m = shape(dataMatrix)[0]
aggClassEst = mat(zeros((m,1)))
for i in range(len(classifierArr)):
classEst = stumpClassify(dataMatrix,classifierArr[i]['dim'],\
classifierArr[i]['thresh'],\
classifierArr[i]['ineq'])#call stump classify
aggClassEst += classifierArr[i]['alpha']*classEst
print(aggClassEst)
return sign(aggClassEst)
2.3应用IRIS数据集进行测试
2.3.1数据预处理
选择两种花的数据,Iris-setosa 和Iris-versicolor ,并将标签替换为1和-1;

2.3.2数据可视化
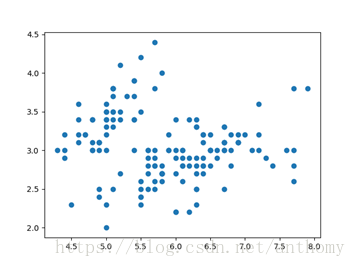
花萼长度、花萼宽度数据构建的散点图
2.3.3 训练数据测试

因为训练使用的数据量相对较少(50条),错误率为0。
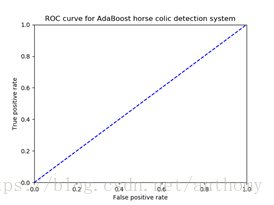
2.3.4测试数据测试和ROC曲线

2.4应用Titanic数据集进行测试
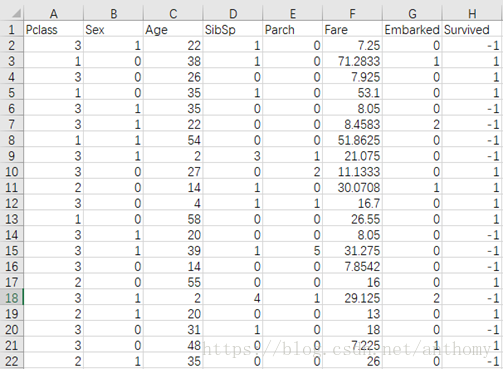
2.4.1 数据预处理
删除Passenger属性、Name属性、Ticket属性,因为对分类结果并不具有直接的关系。
对性别属性,male替换为1,female替换为0;
年龄属性中有很多缺失值,用最大值和最小值中的随机值进行填充;
Embark属性中的S、C、Q对应用0、1、2进行替换;
Survive属性(标签)1/0 按照算法要求处理为1/-1;
处理结果如下图
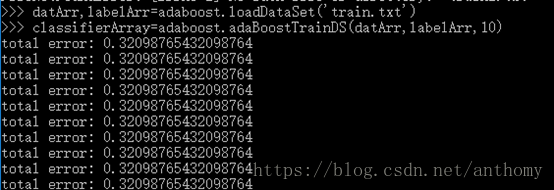
2.4.2 训练数据测试
10个基本分类器(单层决策树)
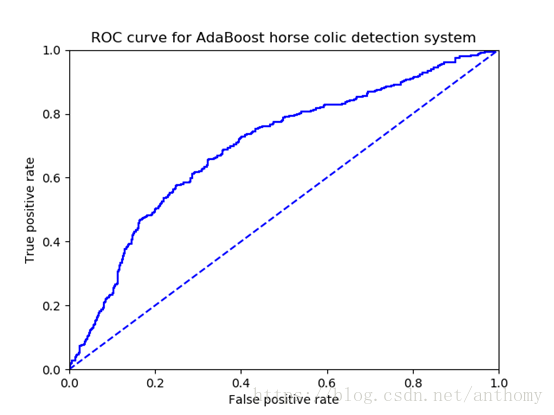
2.4.3 ROC曲线
四、总结与体会
Adaboost方法是个非常强大学习方法,通过各个基本分类器的线性组合来达到更好的分类效果,而在每次迭代中只改变错误样本所占的权值,是个非常高效且使用的算法。
时间有限,并没有找到一些有趣的、更实用的数据集,IRIS数据相对来说比较成熟,简单,错误率低也是可以理解,过段时间会继续寻找一些数据集来进行测试,本片文章也会一直更新。
五、参考文献
【1】Python的替换函数——strip(),replace()和re.sub()
https://blog.csdn.net/zcmlimi/article/details/47709049
【2】《机器学习实战》
【3】《统计学习方法》
非常感谢阅读!如有不足之处,请留下您的评价和问题。