本文主要是学习李航的《统计学习方法》的书的笔记,并加入了《机器学习实战》这本书里关于基于单层决策树的AdaBoost代码实现笔记,将两者结合,将有利于我们更好的理解AdaBoost算法。
1 提升方法AdaBoost算法
提升方法是一种统计学习方法,在分类问题中,通过改变训练样本的权重以及学习多个分类器,并将这些分类器进行线性组合,提高分类性能。在提升方法里最具代表性的就是AdaBoost算法。提升树需要解决两个问题,一是如何在每一轮改变训练数据的权值或者概率分布;二是如何将弱分类器组合成强分类器。
对于第一个问题,AdaBoost算法的做法是提高被前一轮弱分类器错误分类样本的权值,而降低被正确分类 样本的权值。这样,没有得到正确分类的数据由于权值被加大而受到后轮的弱分类器更大关注。
对于第二个问题,,AdaBoost算法的做法是AdaBoosting采取 加权多数表决的方法。具体就是加大分类误差小的弱分类器的权值,使其在表决中起较大的作用,减小分类误差率大的弱分类器的权值。
2 AdaBoost算法的具体步骤:
给定一个二类分类的训练数据集,每个样本点由实例xi与标记yi y={-1,1}组成,样本数为N
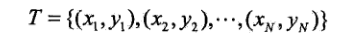
目标从训练数据中学习一系列弱分类器,然后将这些弱分类器Gm(x)组合成一个强分类器G(x)。
(1)初始化训练数据的权值分布
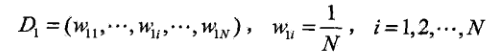
(2)对于第m=1,2,..M轮迭代
(a)使用具有权值分布的Dm的训练数据集学习,得到基本分类器
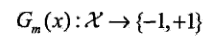
(b)计算基分类器Gm(x)在训练数据集上的分类误差
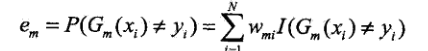
即被Gm(x)误分类的样本的权值和,由此可看出基分类器Gm(x)的分类误差与权值分布Dm关系
(c)计算Gm(x)基分类的系数即基分类器的权值,log为自然对数

可知当em<=1/2时,αm>0,且分类误差率em越小的弱分类器,其权值αm越大。
(d)更新训练数据集的权值分布
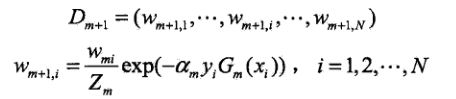
其中,Zm为规范化因子,意思就是让Dm+1是被正确定义的 概率
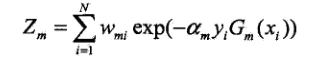
权值分布更新也可表达成如下形式:
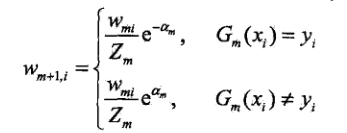
由此可知,正确分类的样本的权值得以缩小,而被误分类的样本的权值得以扩大。
(3)构建弱分类器的线性组合:步骤2完成后得到M(m=1,2,…M)个弱分类器Gm(x):
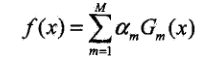
得到最终的强分类器:
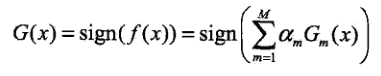
线性组合f(x)实现了 M个基本分类器的加权表决。系数αm表示基本分类器Gm(x)的重要性,系数之和并 不 为1。
3 AdaBoost算法的证明
AdaBoos算法是模型为加法模型,损失函数 为指数函数,学习 算法为 前向分布算法的二分类学习方法。前面的线性组合f(x)就是一个加法模型。可以认为AdaBoost本文省略前向分布算法的介绍,个人觉得直接看AdaBoost的证明也可以了解前向分布 算法的 原理。
(a)AdaBoost算法的最终分类器为:
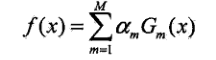
由基本分类 器Gm(x)和基函数 系数αm组成。
(b)AdaBoost的指数损失函数

假设经过m-1轮迭代前向分步算法已经得到fm-1(x):
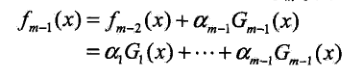
在m轮迭代中得到αm,Gm(x)和fm(x)
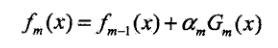
目标是得的αm,Gm(x)使fm(x)在训练集上的指数损失最小,即最小化指数损失函数

上式等价于:


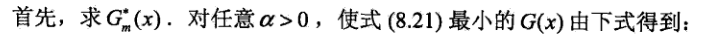 对于求Gm(x)这个式子没怎么明白,感觉看周志华的西瓜书,更好理解
对于求Gm(x)这个式子没怎么明白,感觉看周志华的西瓜书,更好理解

4 用单层决策树作为若分类器的代码实现,摘自《机器学习实战》Peter Harrington著
def loadSimpData(): """函数说明:数据集""" dataMat=np.matrix([[1.0,2.1], [2.0,1.1], [1.3,1.0],[1.0,1.0],[2.0,1.0]]) classlabels=[1.0,1.0,-1.0,-1.0,1.0] return dataMat,classlabels def stumpClassify(dataMatrix,dimen,threshVal,threshIneq): #按特征分类 """函数说明:单层决策树分类函数 parameter: dataMatrix -数据集 dimen-第dimen列 threshVal - 阈值 threshIneq - 标志 returns: retArray - 分类结果""" retArray=np.ones((np.shape(dataMatrix)[0],1)) #初始化retArray为1 if threshIneq=='lt': #less than retArray[dataMatrix[:,dimen]<=threshVal]=-1.0 #如果小于阈值,则赋值为-1 else: retArray[dataMatrix[:,dimen]>threshVal]=-1.0 #如果大于阈值,则赋值为-1 return retArray def buildStump(dataArr,classlabels,D): """函数描述:找到数据集上的最佳单层决策树 parameter: dataArr - 数据集 classlabels - 数据标签 D - 样本权重 return: bestStump - 最佳单层决策树信息 minError - 最小误差 bestClassEst - 最佳分类结果""" dataMatrix=np.mat(dataArr);labelMat=np.mat(classlabels).T m,n=np.shape(dataMatrix) numSteps=10.0;bestStump={};bestClassEst=np.mat(np.zeros((m,1))) minError=float('inf') #最小误差初始化为正无穷大 for i in range(n): #遍历所有特征 rangeMin=dataMatrix[:,i].min();rangeMax=dataMatrix[:,i].max(); #找到特征中最小的值和最大值 stepsize=(rangeMax-rangeMin)/numSteps #计算步长 for j in range(-1,int(numSteps)+1): for inequal in ['lt','gt']: #大于和小于的情况,均遍历。lt:less than,gt:greater than threshVal=(rangeMin+float(j)*stepsize) #计算阈值 predictedVals=stumpClassify(dataMatrix,i,threshVal,inequal) #计算分类结果 errArr=np.mat(np.ones((m,1))) #初始化误差矩阵 errArr[predictedVals==labelMat]=0 #分类正确的,赋值为0 weightedError=D.T*errArr #计算误差 #print"split:dim %d,thresh %.2f,thresh inequal:%s,the weighted error is %.3f" %(i,threshVal,inequal,weighyedError) if weightedError<minError: minError=weightedError bestClassEst=predictedVals.copy() bestStump['dim']=i bestStump['thresh']=threshVal bestStump['ineq']=inequal return bestStump,minError,bestClassEst def adaBoostTrainDS(dataArr,classLabels,numIt=40): """函数说明:基于单层决策树的AdaBoost训练过程 parament: dataArr - 数据集 classLabels - 数据标签 numIt- 迭代次数 return: weakClassArr - 弱分类器""" weakClassArr=[] m=np.shape(dataArr)[0] D=np.mat(np.ones((m,1))/m) aggClassEst=np.mat(np.zeros((m,1))) for i in range(numIt): bestStump,error,classEst=buildStump(dataArr,classLabels,D) print("D:",D.T) alpha=float(0.5*math.log((1.0-error)/max(error,1e-16))) bestStump['alpha']=alpha #存储弱学习算法权重 weakClassArr.append(bestStump) #存储单层决策树 print("classEst:",classEst.T) expon=np.multiply(-1*alpha*np.mat(classLabels).T,classEst) #计算e的指数项 D=np.multiply(D,np.exp(expon)) D=D/D.sum() #根据样本权重公式,更新样本权重 aggClassEst+=alpha*classEst #计算类别估计累计值 print ("aggClassEst:",aggClassEst.T) aggErrors=np.mat(np.ones((m,1))) aggErrors[np.sign(aggClassEst)==np.mat(classLabels).T]=0 #计算误差 errorRate=aggErrors.sum()/m print("total error:",errorRate,"\n") if errorRate==0.0:break #误差为0,退出循环 return weakClassArr def adaClassify(datatoclass,classfierArr): """函数说明:adaboost分类函数 parameter: datatoclass - 待分类数组 classfierArr - 弱分类器组成的数组""" dataMatrix=np.mat(datatoclass) m=np.shape(dataMatrix)[0] aggClassEst=np.mat(np.zeros((m,1))) for i in range(len(classfierArr)): classEst= stumpClassify(dataMatrix,classfierArr[i]['dim'],classfierArr[i]['thresh'],classfierArr[i]['ineq']) aggClassEst += classfierArr[i]['alpha']*classEst print(aggClassEst) return np.sign(aggClassEst)