简介
周志华的“西瓜书”—《机器学习》一书中,第八章介绍了集成学习的三种方法,分别是:序列化方法(Boost)、并行化方法(Bagging和随机森林),本文针对第一种方法进行了算法介绍以及代码实验。
本文参考了一下两篇文章:
原理及代码:https://www.ibm.com/developerworks/cn/analytics/library/machine-learning-hands-on6-adaboost/index.html
主推代码:https://www.jianshu.com/p/a6426f4c4e64
以上文章解释得非常到位,基本所有的相关文章都跟这里差不多,就不一一列举了。
基本思想
Boost的基本思想是通过一系列的弱分类器,经过计算得到每个弱分类器的权重比例,从而把各个弱分类器关联起来,组成一个强学习器。
最经常使用的弱分类器是单层决策树。单层决策树又称为决策树桩(decision stump),即层数为1的决策树。
下面将直接上代码(原理请看上面的第一个链接):
#author: xiaolinhan_daisy
#date: 2018/01/13
#site: YueJiaZhuang
from numpy import *
#加载数据集
def loadDataSet():
x = [0, 1, 2, 3, 4, 5,6,7,8]
y = [1, 1, -1, -1, 1, -1,1,1,-1]
return x, y
#把相邻两个样本的均值作为切分点,获得一系列的切分店
def generateGxList(x):
gxlist = []
for i in range(len(x) - 1):
gx = (x[i] + x[i + 1]) / 2
gxlist.append(gx)
return gxlist
#判断以gx为切分点的两种方式里,哪种会让误差更小
def calcErrorNum(gx, x, y, weight):
error1 = 0
errorNeg1 = 0
ygx = 1
for i in range(len(x)):
if i < gx and y[i] != 1: error1 += weight[i]
if i > gx and y[i] != -1: error1 += weight[i]
if i < gx and y[i] != -1: errorNeg1 += weight[i]
if i > gx and y[i] != 1: errorNeg1 += weight[i]
if errorNeg1 < error1:
return errorNeg1, -1 #x>gx,则fgx = 1
return error1, 1 #x<gx, 则fgx = 1
#计算弱分类器的权重,组合成强分类器
def calcAlpha(minError):
alpha = 1/2 * log((1-minError)/minError)
return alpha
#计算错误数量,更新每个样本的权重
def calcNewWeight(alpha,ygx, weight, gx, y):
newWeight = []
sumWeight = 0
for i in range(len(weight)):
flag = 1
if i < gx and y[i] != ygx: flag = -1
if i > gx and y[i] != -ygx: flag = -1
weighti = weight[i]*exp(-alpha*flag)
newWeight.append(weighti)
sumWeight += weighti
newWeight = newWeight / sumWeight
return newWeight
#选择最优若分类器,更新权重
def trainfxi(fx, i, x, y, weight):
minError = inf
bestGx = 0.5
gxlist = generateGxList(x) #x所有可能划分点的过程。本文选取两个相邻x的均值作为划分点。
bestygx = 1
# 计算基本分类器
for xi in gxlist:
error, ygx = calcErrorNum(xi, x, y, weight) #获取每个划分点,左右两边最低错误率的其中一边
if error < minError:
minError = error
bestGx = xi #划分点,比如0.5、1.5、2.5、3.5、4.5
bestygx = ygx
fx[i]['gx'] = bestGx #第n个弱分类器的最小错误率的划分点
alpha = calcAlpha(minError)
fx[i]['alpha'] = alpha #第n个弱分类器的权重
fx[i]['ygx'] = bestygx
#计算新的训练数据权值
newWeight = calcNewWeight(alpha,bestygx, weight, bestGx, y) #计算错误数量,更新每个样本的权重
return newWeight
#计算错误率
def calcFxError(fx, n, x, y):
errorNum = 0
for i in range(len(x)):
fi = 0
for j in range(n):
fxiAlpha = fx[j]['alpha']
fxiGx = fx[j]['gx']
ygx = fx[j]['ygx']
if i < fxiGx: fgx = ygx
else: fgx = -ygx
fi += fxiAlpha * fgx
if sign(fi) != y[i]: errorNum += 1
return errorNum/len(x)
#训练强学习器,得到n个弱学习器的参数及权重
def trainAdaBoost(x, y, errorThreshold, maxIterNum):
fx = {}
weight = []
xNum = len(x)
for i in range(xNum):
w = float(1/xNum) #初始化权重,每个都是1/m
weight.append(w)
for i in range(maxIterNum):
fx[i] = {} #保存决策树的参数
newWeight = trainfxi(fx, i, x, y, weight) #更新权重
weight = newWeight
fxError = calcFxError(fx, (i+1), x, y) #错误率
if fxError < errorThreshold: break
return fx
if __name__ == '__main__':
x, y = loadDataSet() #加载数据集
errorThreshold = 0.01 #错误率阈值,小于0.01则停止训练
maxIterNum = 10 #步长
fx = trainAdaBoost(x, y, errorThreshold, maxIterNum) #训练强学习器,得到n个弱学习器的参数及权重
print(fx)
训练样本和标签为:
x = [0, 1, 2, 3, 4, 5]
y = [1, 1, -1, -1, 1, -1]
得到结果如下:
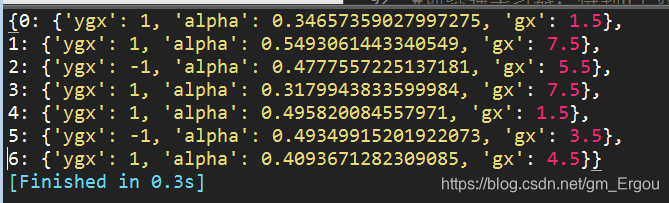
分别对应了三个弱分类器的参数,以及每个分类器的权重alpha。